GPT2 NewsTitle
1.0.0
Proyecto de generación de títulos de noticias GPT2 con anotaciones súper detalladas
Ejecutar el código
streamlit run app.py
or
streamlit run app.py --server.port your_port
Los detalles se muestran en la figura a continuación:
| datos | Dirección original de datos/proyecto | Dirección de descarga de archivos después del procesamiento |
|---|---|---|
| Datos de noticias de Tsinghua | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: VHOL |
| Datos de noticias de Sogou | DIRECCIÓN | Código de extracción de disco en la nube de Baidu: ODE6 |
| NLPCC2017 Datos de resumen | DIRECCIÓN | Código de extracción de disco en la nube de Baidu: E0ZQ |
| Datos de resumen de CSL | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: 0qot |
| Datos de resumen de la industria de la educación y capacitación | DIRECCIÓN | Código de extracción de disco en la nube de Baidu: KJZ3 |
| Datos de resumen de LCSS | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: BZOV |
| Datos de resumen de Shence Cup 2018 | DIRECCIÓN | Código de extracción de disco en la nube de Baidu: 6F4F |
| Datos de resumen de Wanfang | DIRECCIÓN | Código de extracción de disco en la nube de Baidu: P69G |
| Datos de resumen de cuenta oficial de WeChat | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: 5has |
| Datos de Weibo | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: 85T5 |
| News2016zh Datos de noticias | DIRECCIÓN | Código de extracción de disco de la nube de Baidu: QSJ1 |
Colección del conjunto de datos: Baidu Cloud Disk Code: 7am8
Consulte requisitos.txt archivo para más detalles
Los datos provienen de Sina Weibo, enlace de datos: https://www.jiansshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg
| Descripción de los datos | Dirección de descarga |
|---|---|
| Datos sin procesar | Baidu NetDisk, Código de extracción: NQZI |
| Datos procesados | Baidu NetDisk, Código de extracción: Duba |
Los datos originales son datos de noticias descargados directamente de Internet. Después del procesamiento, los datos se procesan con datos utilizando data_helper.py y pueden usarse directamente para la capacitación.
Consulte el archivo config/config.json para obtener más detalles
| parámetro | valor |
|---|---|
| inicializador_range | 0.02 |
| LAYER_NORM_EPSILON | 1e-05 |
| N_CTX | 512 |
| N_EMBD | 768 |
| n_head | 12 |
| N_LAYER | 6 |
| N_Positions | 512 |
| VOCAB_SIZE | 13317 |
Nota: Además de la representación vectorial de cada palabra, la entrada del modelo también incluye la representación del vector del párrafo de texto y la representación del vector de posición. 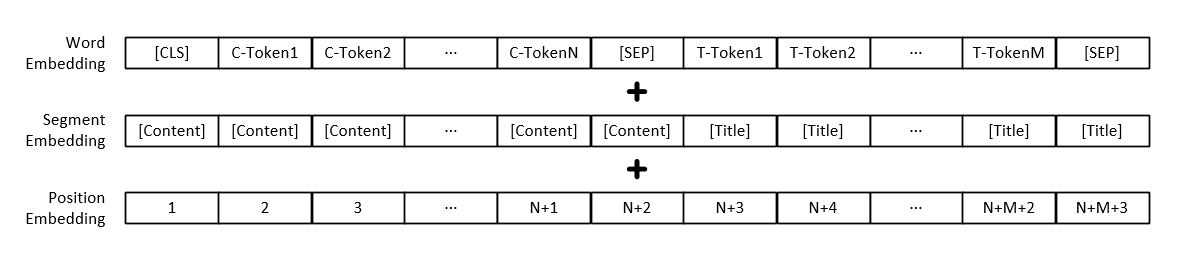
| Modelo | Dirección de descarga |
|---|---|
| Modelo GPT2 | Baidu NetDisk, Código de extracción: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
Los parámetros de entrenamiento se pueden agregar usted mismo, incluidos los parámetros de la siguiente manera:
| parámetro | tipo | valor predeterminado | describir |
|---|---|---|---|
| dispositivo | stri | "0" | Configure la tarjeta gráfica utilizada para capacitación o prueba |
| config_path | stri | "config/config.json" | Información de configuración de parámetros del modelo |
| VOCAB_PATH | stri | "Vocab/Vocab.txt" | La lista de palabras es una pequeña lista de palabras y ha agregado algunas marcas nuevas |
| Train_file_path | stri | "data_dir/trenes_data.json" | Datos de capacitación generados por títulos de noticias |
| test_file_path | stri | "data_dir/test_data.json" | Datos de prueba generados por títulos de noticias |
| Pretrenado_model_path | stri | Ninguno | Camino al modelo GPT2 previamente capacitado |
| data_dir | stri | "data_dir" | Generar la ruta de almacenamiento de datos en caché |
| num_train_epochs | intencionalmente | 5 | Número de rondas para el entrenamiento modelo |
| Train_batch_size | intencionalmente | 16 | El tamaño de cada lote durante el entrenamiento |
| test_batch_size | intencionalmente | 8 | El tamaño de cada lote durante la prueba |
| aprendizaje_rate | flotar | 1e-4 | Tasa de aprendizaje durante la capacitación de modelos |
| Warmup_proportion | flotar | 0.1 | La probabilidad de calentamiento, es decir, el porcentaje del tamaño total del paso de entrenamiento, realiza la operación de calentamiento |
| Adam_epsilon | flotar | 1e-8 | Valor Epsilon de Adam Optimizer |
| logging_steps | intencionalmente | 20 | Número de pasos para guardar el registro de capacitación |
| eval_steps | intencionalmente | 4000 | ¿Cuántos pasos se realizarán durante el entrenamiento? |
| gradiente_accumulación_steps | intencionalmente | 1 | Acumulación de gradiente |
| max_grad_norm | flotar | 1.0 | |
| salida_dir | stri | "output_dir/" | Ruta de salida del modelo |
| semilla | intencionalmente | 2020 | Semillas aleatorias |
| max_len | intencionalmente | 512 | La longitud máxima del modelo de entrada es menor que N_CTX en config |
O modifique el contenido de la función SET_ARGS en el archivo Train.py para modificar el valor predeterminado.
Los modelos proporcionados por este proyecto han capacitado 5 épocas, y la pérdida de entrenamiento del modelo y la pérdida del conjunto de pruebas son las siguientes: 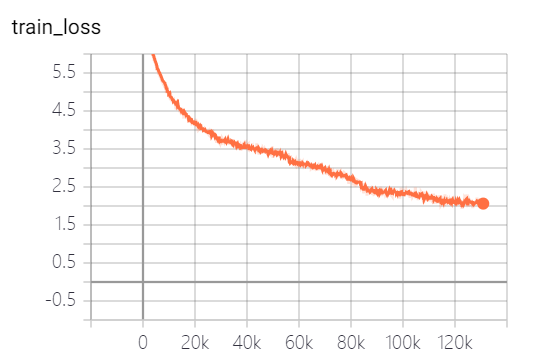
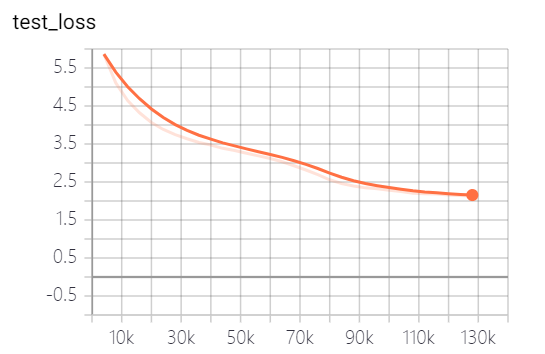
El modelo aún no ha sido completamente entrenado. Según la tendencia de pérdida, puede continuar entrenando.
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
Los parámetros se pueden agregar usted mismo, incluidos los parámetros de la siguiente manera:
| parámetro | tipo | valor predeterminado | describir |
|---|---|---|---|
| dispositivo | stri | "0" | Configure la tarjeta gráfica utilizada para capacitación o prueba |
| modelo_path | stri | "output_dir/checkpoint-139805" | Ruta de archivo de modelo |
| VOCAB_PATH | stri | "Vocab/Vocab.txt" | La lista de palabras es una pequeña lista de palabras y ha agregado algunas marcas nuevas |
| lote_size | intencionalmente | 3 | Número de títulos generados |
| generar_max_len | intencionalmente | 32 | Longitud máxima del título generado |
| repetición_penalia | flotar | 1.2 | Tasa de penalización repetida |
| top_k | intencionalmente | 5 | Cuántas etiquetas con la mayor probabilidad de retención durante la decodificación |
| Top_p | flotar | 0.95 | Marcadores cuya probabilidad de retención es mayor de lo que es la probabilidad de retención acumulada durante la decodificación |
| max_len | intencionalmente | 512 | La longitud máxima del modelo de entrada es menor que N_CTX en config |
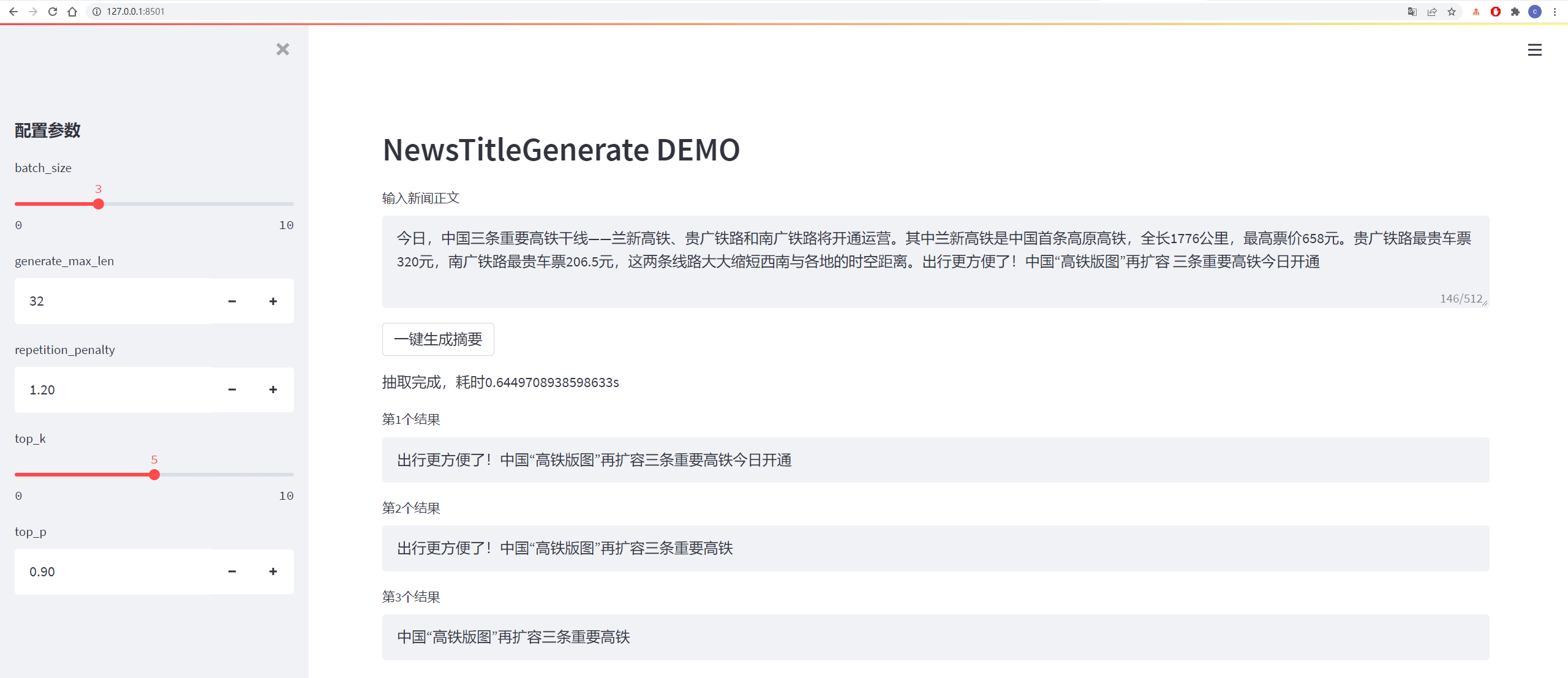
Los resultados de la prueba son los siguientes:
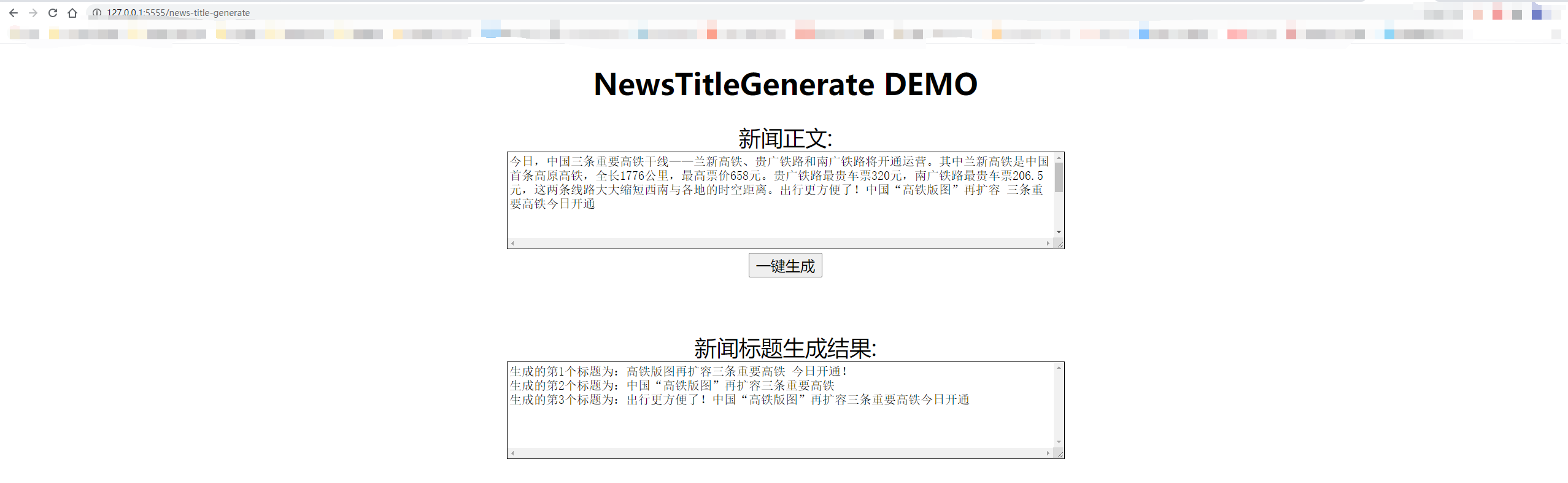
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
La decodificación adopta estrategias de decodificación TOP_K y TOP_P, que tienen cierta aleatoriedad y pueden generarse repetidamente.
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
Las pruebas locales usan "127.0.0.1:5555/News-Title Generate". Si le da acceso a otros, solo necesita reemplazar "127.0.0.1" con la dirección IP de la computadora.
Los detalles se muestran en la figura a continuación:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
Correo electrónico: [email protected]
Zhihu: Liu Cong NLP
Cuenta oficial: estación de trabajo de NLP



