GPT2 NewsTitle
1.0.0
매우 상세한 주석이있는 GPT2 뉴스 타이틀 생성 프로젝트
코드를 실행하십시오
streamlit run app.py
or
streamlit run app.py --server.port your_port
세부 사항은 아래 그림에 나와 있습니다.
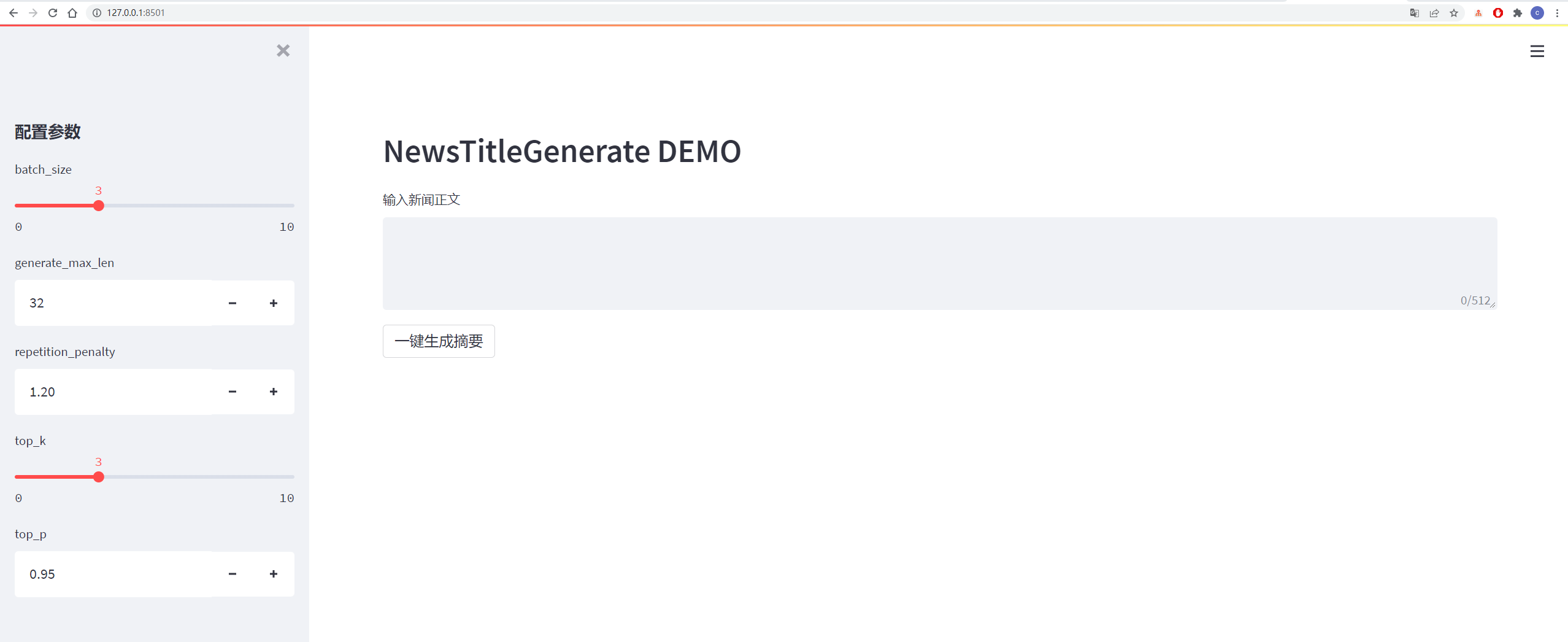
| 데이터 | 원래 데이터/프로젝트 주소 | 처리 후 파일 다운로드 주소 |
|---|---|---|
| Tsinghua 뉴스 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : vhol |
| Sogou 뉴스 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : ODE6 |
| NLPCC2017 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : E0ZQ |
| CSL 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : 0QOT |
| 교육 및 훈련 산업 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : KJZ3 |
| LCSS 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : BZOV |
| Shence Cup 2018 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : 6F4F |
| Wanfang 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : P69G |
| WeChat 공식 계정 요약 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : 5HAS |
| Weibo 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : 85T5 |
| News2016ZH 뉴스 데이터 | 주소 | 바이두 클라우드 디스크 추출 코드 : QSJ1 |
데이터 세트 수집 : 바이두 클라우드 디스크 추출 코드 : 7am8
자세한 내용은 요구 사항.txt 파일을 참조하십시오
데이터는 Sina Weibo, Data Link : https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg에서 제공됩니다
| 데이터 설명 | 주소를 다운로드하십시오 |
|---|---|
| 원시 데이터 | Baidu NetDisk, 추출 코드 : NQZI |
| 처리 된 데이터 | Baidu Netdisk, 추출 코드 : Duba |
원래 데이터는 인터넷에서 직접 다운로드 한 뉴스 데이터입니다. 처리 후 데이터는 Data_Helper.py를 사용하여 데이터를 처리하며 교육에 직접 사용할 수 있습니다.
자세한 내용은 config/config.json 파일을 참조하십시오
| 매개 변수 | 값 |
|---|---|
| 이니셜 라이저_Range | 0.02 |
| layer_norm_epsilon | 1E-05 |
| N_CTX | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| vocab_size | 13317 |
참고 : 각 단어의 벡터 표현 외에도 모델 입력에는 텍스트 단락 벡터 표현 및 위치 벡터 표현도 포함됩니다. 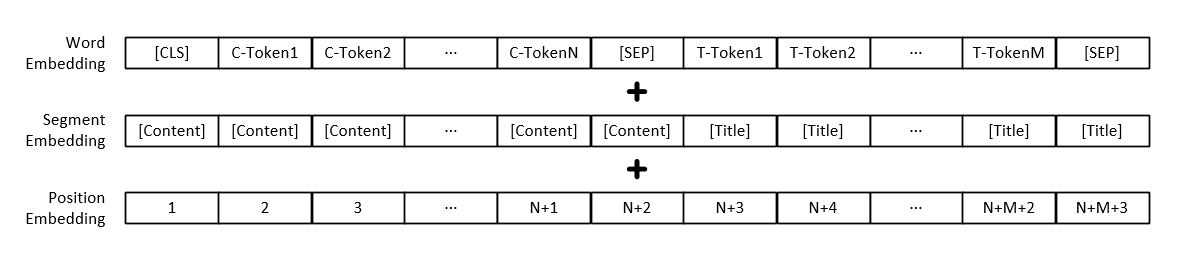
| 모델 | 주소를 다운로드하십시오 |
|---|---|
| GPT2 모델 | Baidu Netdisk, 추출 코드 : 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
교육 매개 변수는 다음과 같이 매개 변수를 포함하여 직접 추가 할 수 있습니다.
| 매개 변수 | 유형 | 기본값 | 설명하다 |
|---|---|---|---|
| 장치 | str | "0" | 교육 또는 테스트에 사용되는 그래픽 카드 설정 |
| config_path | str | "config/config.json" | 모델 매개 변수 구성 정보 |
| vocab_path | str | "vocab/vocab.txt" | 단어 목록은 작은 단어 목록이며 몇 가지 새로운 마크를 추가했습니다. |
| Train_File_Path | str | "data_dir/train_data.json" | 뉴스 타이틀에 의해 생성 된 교육 데이터 |
| test_file_path | str | "data_dir/test_data.json" | 뉴스 제목에 의해 생성 된 테스트 데이터 |
| pretrained_model_path | str | 없음 | 미리 훈련 된 GPT2 모델로가는 경로 |
| data_dir | str | "data_dir" | 캐시 된 데이터 저장 경로를 생성합니다 |
| NUM_TRAIN_EPOCHS | int | 5 | 모델 교육을위한 라운드 수 |
| Train_batch_size | int | 16 | 훈련 중 각 배치의 크기 |
| test_batch_size | int | 8 | 테스트 중 각 배치의 크기 |
| Learning_rate | 뜨다 | 1E-4 | 모델 교육 중 학습 속도 |
| WARTUP_PROPORATION | 뜨다 | 0.1 | 워밍업 확률, 즉 총 교육 단계 크기의 백분율은 워밍업 작업을 수행합니다. |
| Adam_epsilon | 뜨다 | 1E-8 | Adam Optimizer의 Epsilon 값 |
| logging_steps | int | 20 | 교육 로그를 저장하기위한 단계 수 |
| 평가_steps | int | 4000 | 훈련 중에 몇 단계가 수행됩니까? |
| gradient_accumulation_steps | int | 1 | 그라디언트 축적 |
| max_grad_norm | 뜨다 | 1.0 | |
| output_dir | str | "output_dir/" | 모델 출력 경로 |
| 씨앗 | int | 2020 | 임의의 씨앗 |
| max_len | int | 512 | 입력 모델의 최대 길이는 구성에서 N_CTX보다 작습니다. |
또는 기본값을 수정하려면 Train.py 파일에서 set_args 함수의 내용을 수정하십시오.
이 프로젝트에서 제공 한 모델은 5 개의 에포크를 훈련 시켰으며 모델 교육 손실 및 테스트 세트 손실은 다음과 같습니다. 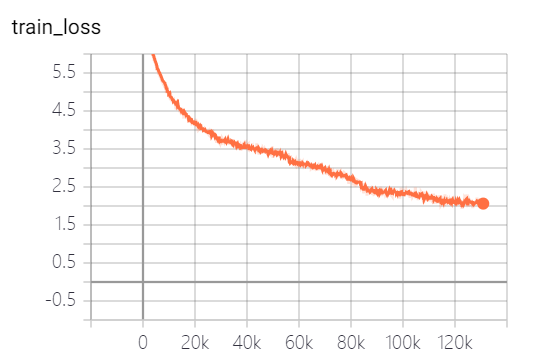
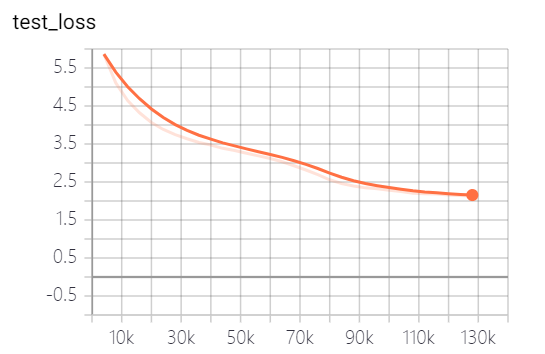
이 모델은 아직 완전히 훈련되지 않았습니다. 손실 추세에 따르면 계속 훈련 할 수 있습니다.
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
파라미터는 다음과 같이 매개 변수를 포함하여 직접 추가 할 수 있습니다.
| 매개 변수 | 유형 | 기본값 | 설명하다 |
|---|---|---|---|
| 장치 | str | "0" | 교육 또는 테스트에 사용되는 그래픽 카드 설정 |
| model_path | str | "output_dir/checkpoint-139805" | 모델 파일 경로 |
| vocab_path | str | "vocab/vocab.txt" | 단어 목록은 작은 단어 목록이며 몇 가지 새로운 마크를 추가했습니다. |
| batch_size | int | 3 | 생성 된 타이틀 수 |
| generate_max_len | int | 32 | 생성 된 제목의 최대 길이 |
| repetition_penalty | 뜨다 | 1.2 | 반복되는 페널티 율 |
| top_k | int | 5 | 디코딩 중에 유지 될 확률이 가장 높은 태그 수 |
| top_p | 뜨다 | 0.95 | 보유 확률이 디코딩 중 누적 된 보유 확률보다 큰 마커 |
| max_len | int | 512 | 입력 모델의 최대 길이는 구성에서 N_CTX보다 작습니다. |
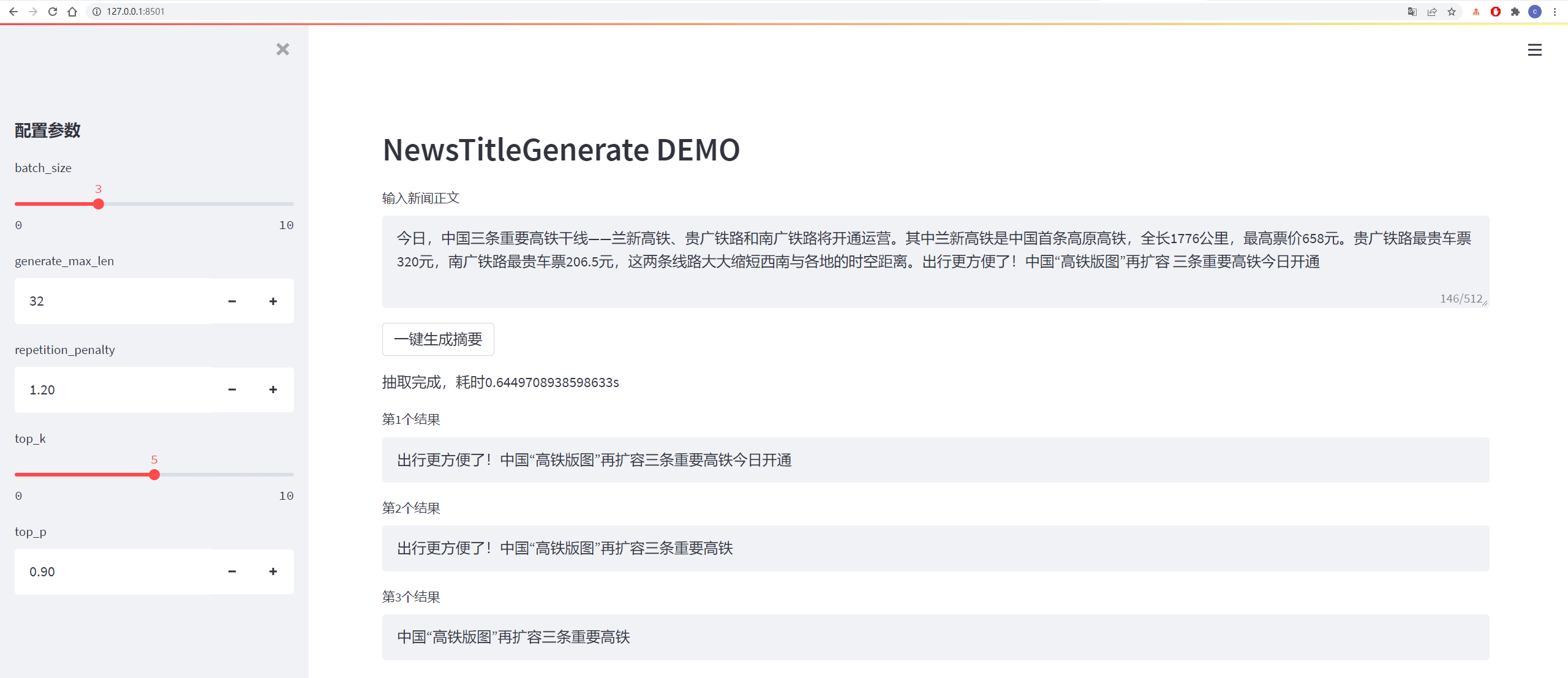
테스트 결과는 다음과 같습니다.
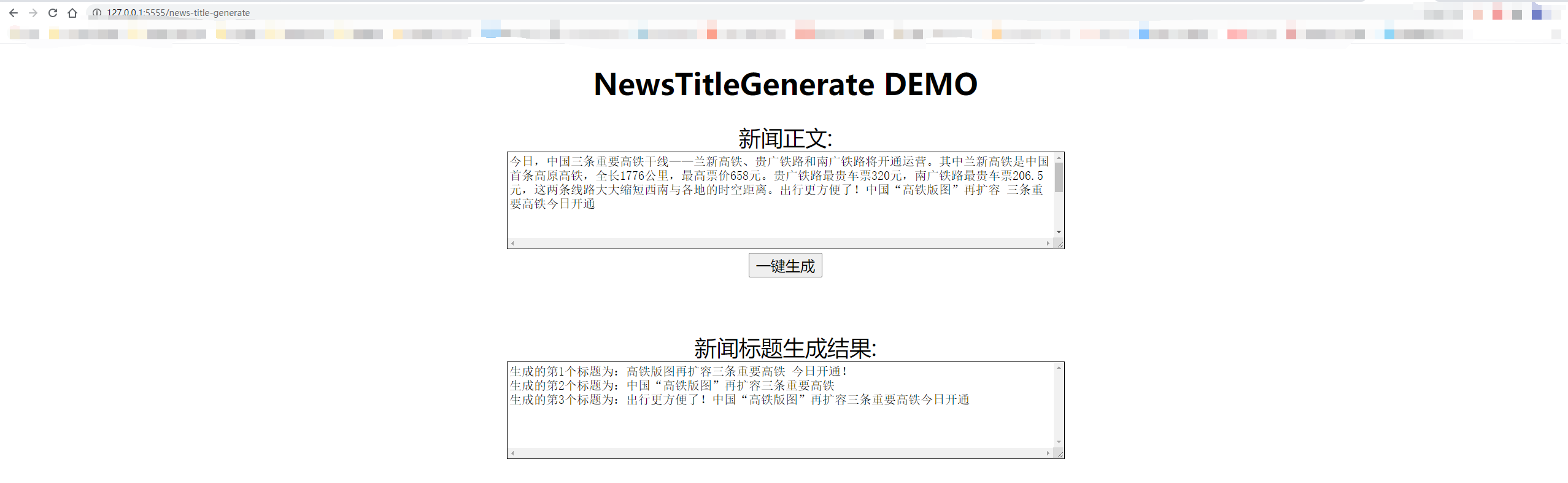
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
디코딩은 TOP_K 및 TOP_P 디코딩 전략을 채택하며, 이는 특정한 무작위성을 가지며 반복적으로 생성 될 수 있습니다.
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
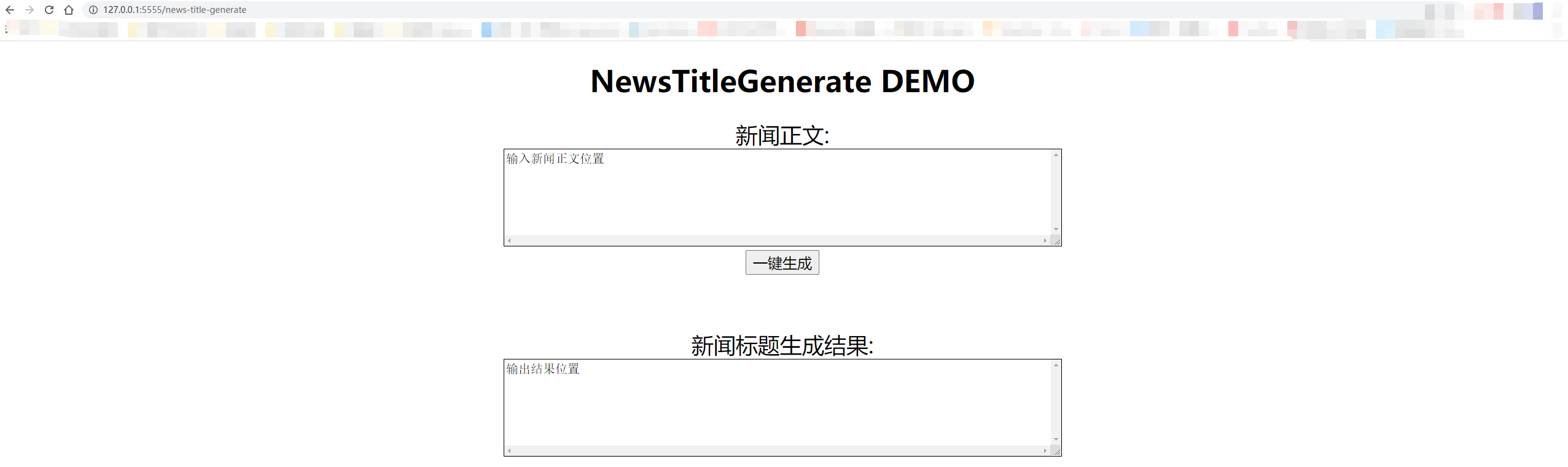
로컬 테스트는 "127.0.0.1:5555/news-title-generate"를 사용합니다. 다른 사람에게 액세스 권한을 부여하는 경우 "127.0.0.1"만 컴퓨터의 IP 주소로만 교체하면됩니다.
세부 사항은 아래 그림에 나와 있습니다.
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
이메일 : [email protected]
Zhihu : Liu cong nlp
공식 계정 : NLP 워크 스테이션



