GPT2 NewsTitle
1.0.0
GPT2 news title generation project with super detailed annotations
Run the code
streamlit run app.py
or
streamlit run app.py --server.port your_port
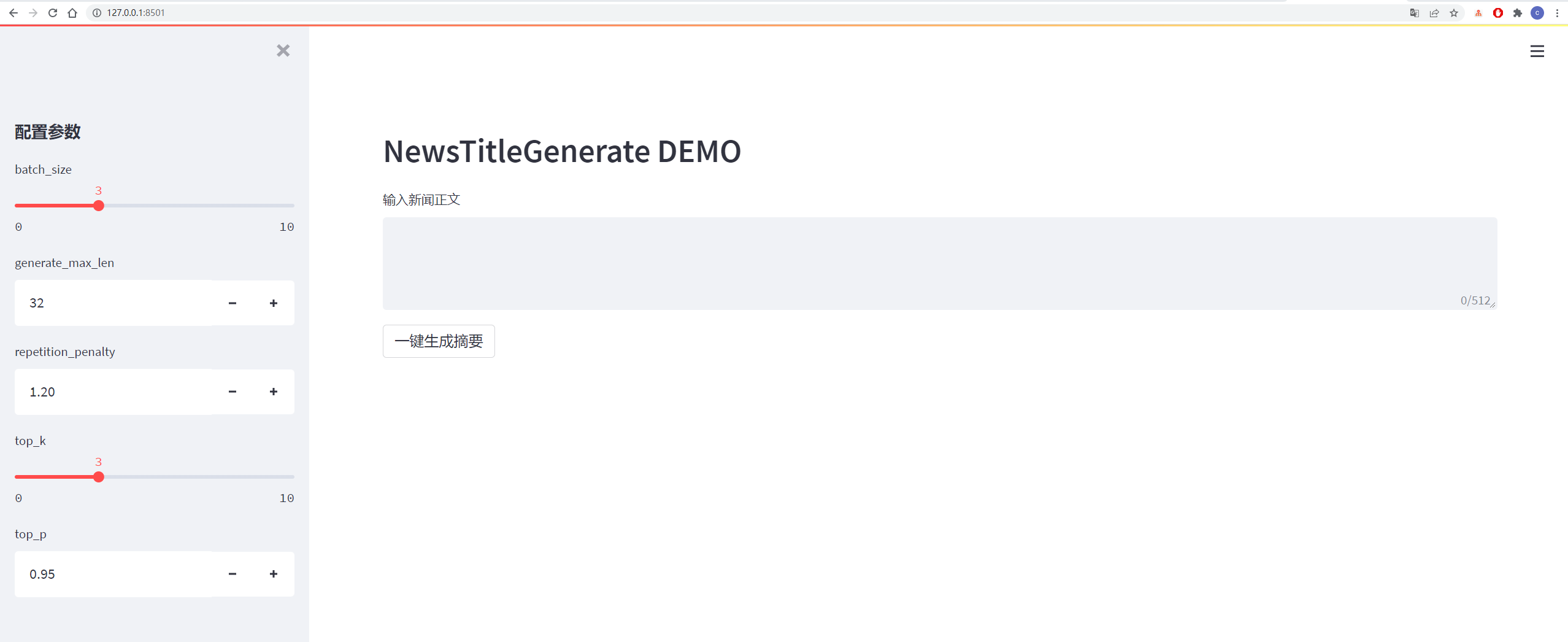
The details are shown in the figure below:
| data | Original data/project address | File download address after processing |
|---|---|---|
| Tsinghua News Data | address | Baidu Cloud Disk Extraction Code: vhol |
| Sogou News Data | address | Baidu Cloud Disk Extraction Code: ode6 |
| nlpcc2017 summary data | address | Baidu Cloud Disk Extraction Code: e0zq |
| csl summary data | address | Baidu Cloud Disk Extraction Code: 0qot |
| Education and training industry summary data | address | Baidu Cloud Disk Extraction Code: kjz3 |
| lcss summary data | address | Baidu Cloud Disk Extraction Code: bzov |
| Shence Cup 2018 Summary Data | address | Baidu Cloud Disk Extraction Code: 6f4f |
| Wanfang Summary Data | address | Baidu Cloud Disk Extraction Code: p69g |
| WeChat official account summary data | address | Baidu Cloud Disk Extraction Code: 5has |
| Weibo data | address | Baidu Cloud Disk Extraction Code: 85t5 |
| news2016zh news data | address | Baidu Cloud Disk Extraction Code: qsj1 |
Dataset collection: Baidu Cloud Disk Extraction Code: 7am8
See requirements.txt file for details
The data comes from Sina Weibo, data link: https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg
| Data description | Download address |
|---|---|
| Raw data | Baidu Netdisk, extract code: nqzi |
| Processed data | Baidu Netdisk, extract code: duba |
The original data is news data downloaded directly from the Internet. After processing, the data is data processed using data_helper.py and can be directly used for training.
See config/config.json file for details
| parameter | value |
|---|---|
| initializer_range | 0.02 |
| layer_norm_epsilon | 1e-05 |
| n_ctx | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| vocab_size | 13317 |
Note: In addition to the vector representation of each word, the model input also includes text paragraph vector representation and position vector representation. 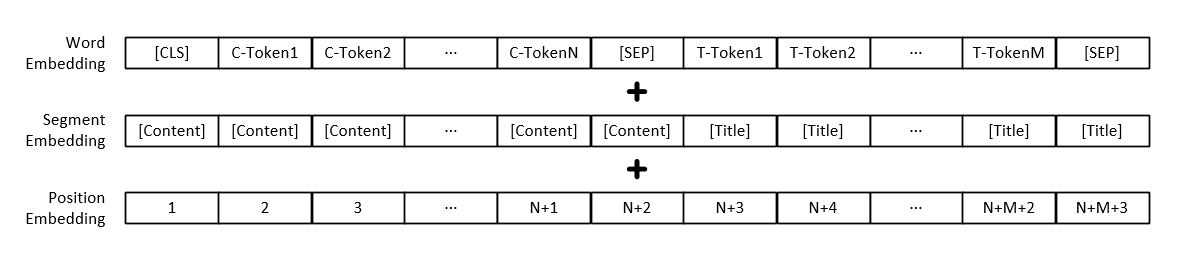
| Model | Download address |
|---|---|
| GPT2 model | Baidu Netdisk, extraction code: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
The training parameters can be added by yourself, including the parameters as follows:
| parameter | type | default value | describe |
|---|---|---|---|
| device | str | "0" | Set up the graphics card used for training or testing |
| config_path | str | "config/config.json" | Model parameter configuration information |
| vocab_path | str | "vocab/vocab.txt" | The word list is a small word list and has added some new marks |
| train_file_path | str | "data_dir/train_data.json" | Training data generated by news titles |
| test_file_path | str | "data_dir/test_data.json" | Test data generated by news titles |
| pretrained_model_path | str | None | Path to pre-trained GPT2 model |
| data_dir | str | "data_dir" | Generate cached data storage path |
| num_train_epochs | int | 5 | Number of rounds for model training |
| train_batch_size | int | 16 | The size of each batch during training |
| test_batch_size | int | 8 | The size of each batch during testing |
| learning_rate | float | 1e-4 | Learning rate during model training |
| warmup_proportion | float | 0.1 | The warm up probability, that is, the percentage of the total training step size, perform the warm up operation |
| adam_epsilon | float | 1e-8 | epsilon value of Adam optimizer |
| logging_steps | int | 20 | Number of steps to save the training log |
| eval_steps | int | 4000 | How many steps will be performed during training? |
| gradient_accumulation_steps | int | 1 | Gradient accumulation |
| max_grad_norm | float | 1.0 | |
| output_dir | str | "output_dir/" | Model output path |
| seed | int | 2020 | Random seeds |
| max_len | int | 512 | The maximum length of the input model is smaller than n_ctx in config |
Or modify the content of the set_args function in the train.py file to modify the default value.
The models provided by this project have trained 5 epochs, and the model training loss and test set loss are as follows: 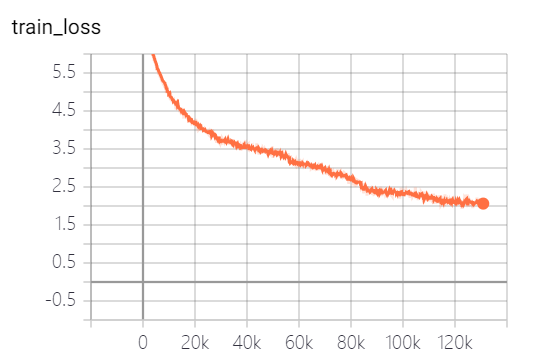
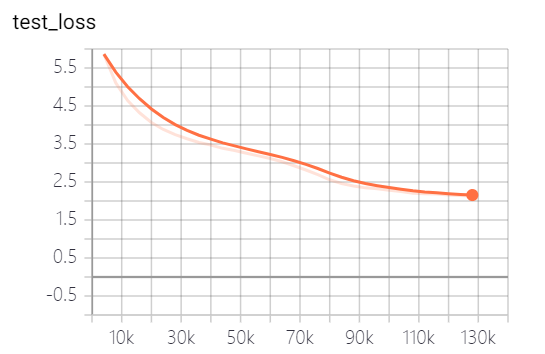
The model has not been fully trained yet. According to the loss trend, you can continue to train.
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
Parameters can be added by yourself, including parameters as follows:
| parameter | type | default value | describe |
|---|---|---|---|
| device | str | "0" | Set up the graphics card used for training or testing |
| model_path | str | "output_dir/checkpoint-139805" | Model file path |
| vocab_path | str | "vocab/vocab.txt" | The word list is a small word list and has added some new marks |
| batch_size | int | 3 | Number of titles generated |
| generate_max_len | int | 32 | Maximum length of generated title |
| repetition_penalty | float | 1.2 | Repeated penalty rate |
| top_k | int | 5 | How many tags with the highest probability of retaining during decoding |
| top_p | float | 0.95 | Markers whose retention probability is greater than what is the accumulated retention probability during decoding |
| max_len | int | 512 | The maximum length of the input model is smaller than n_ctx in config |
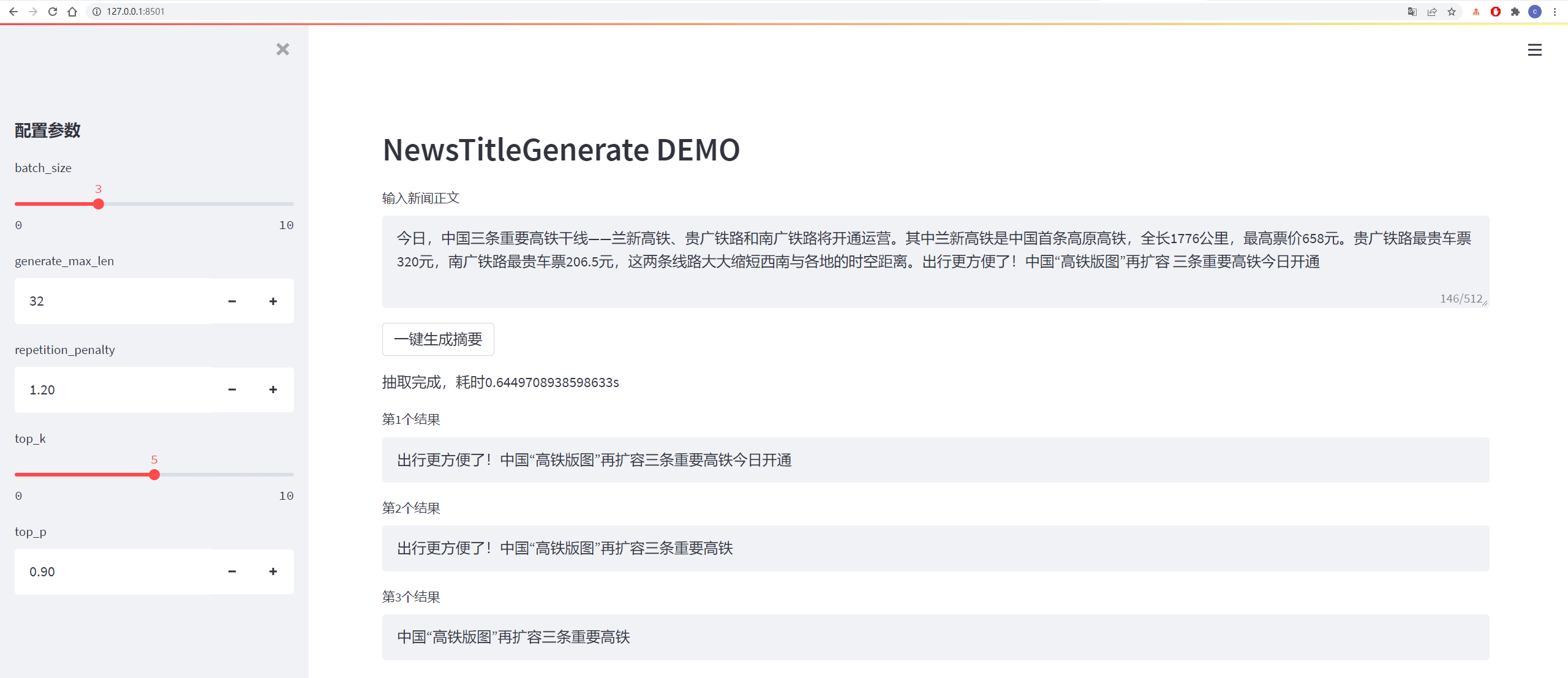
The test results are as follows:
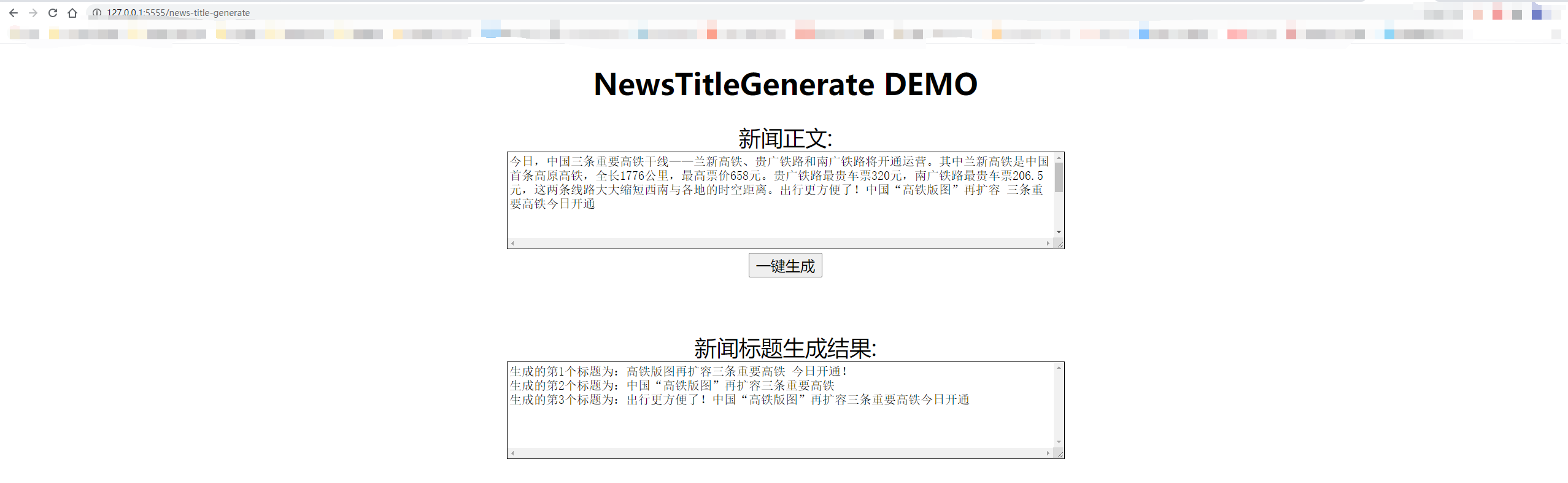
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
The decoding adopts top_k and top_p decoding strategies, which have certain randomness and can be generated repeatedly.
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
Local tests use "127.0.0.1:5555/news-title-generate". If you give others access, you only need to replace "127.0.0.1" with the IP address of the computer.
The details are shown in the figure below:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
e-mail: [email protected]
Zhihu: Liu Cong NLP
Official account: NLP workstation



