RocketQA
1.0.0

近年來,基於預訓練的語言模型的密集檢索器取得了顯著的進步。為了促進更多開發人員使用最先進的技術,該存儲庫提供了一個易於使用的工具包,用於運行和微調最先進的密集檢索器,即Rocketqa 。該工具包具有以下優點:
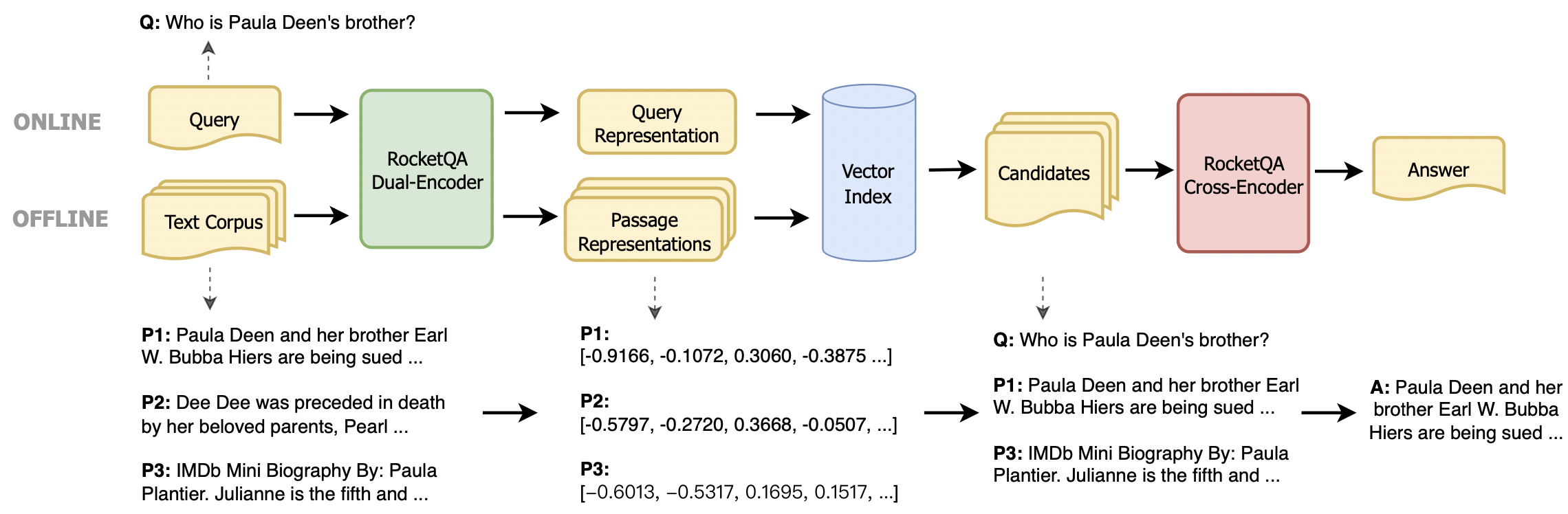
我們提供兩種安裝方法: Python安裝程序包和Docker環境
首先,安裝槳板。
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddle第二,安裝RocketQa軟件包(最新版本:1.1.0):
$ pip install rocketqa注意:此工具包必須在Python3.6+上運行,並使用PaddlePaddle 2.0+運行。
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bash請參閱下面的示例,您可以使用幾行代碼來構建和運行自己的搜索引擎。我們還提供一個帶有Jupyternotebook的操場。在瀏覽器中立即嘗試Rocketqa!
Jina是一個雲本地的神經搜索框架,可在幾分鐘內構建SOTA和可擴展的深度學習搜索應用程序。這是一個簡單的示例,用於構建基於Jina和Rocketqa的搜索引擎。
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cli請查看Jina示例以了解更多。
我們還提供了一個基於faiss的簡單示例。
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.py您還可以輕鬆地將RocketQA集成到自己的任務中。我們提供兩種類型的模型:基於Ernie的雙重編碼器,用於答案檢索和基於Ernie的交叉編碼器,以重新排名。對於運行我們的模型,您可以使用以下功能。
rocketqa.available_models()返回可用RocketQA型號的名稱。要了解有關可用模型的更多信息,請參閱代碼註釋。
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)返回輸入參數指定的模型。它可以初始化雙重編碼器和交叉編碼器。通過設置輸入參數,您可以加載由“可用_models()”返回的RocketQA型號或您自己的檢查點。
由“ load_model()”返回的雙編碼器支持以下功能:
model.encode_query(query: List[str])給定查詢列表,返回按模型編碼的表示向量。
model.encode_para(para: List[str], title: List[str])給定段落及其相應標題(可選)的列表,返回由模型編碼的表示向量。
model.matching(query: List[str], para: List[str], title: List[str])給定查詢和段落(和標題)的列表,返回其匹配分數(兩個表示向量之間的點產品)。
model.train(train_set: str, epoch: int, save_model_path: str, args)鑑於HyperParameters train_set , epoch和save_model_path ,您可以訓練自己的雙編碼器模型或Finetune我們的型號。其他設置(例如save_steps and learning_rate也可以在args中設置。請參閱示例/示例。
由“ load_model()”返回的交叉編碼器支持以下功能:
model.matching(query: List[str], para: List[str], title: List[str])給定查詢和段落(和標題)的列表,返回其匹配分數(段落是查詢正確的答案的概率)。
model.train(train_set: str, epoch: int, save_model_path: str, args)給定超參數train_set , epoch和save_model_path ,您可以訓練自己的交叉編碼器模型或我們的型號Finetune。其他設置(例如save_steps and learning_rate也可以在args中設置。請參閱示例/示例。
按照以下示例,您可以檢索文檔的向量表示,並將RocketQA連接到您自己的任務。
要運行RocketQA模型,您應該在“ load_model()”中設置參數model ,其中RocketQa模型名稱由'opaine_models()返回。
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list )要訓練自己的模型,您可以將train()功能與數據集和參數一起使用。培訓數據包含4列:查詢,標題,Para,標籤(0或1),由“ t”隔開。有關參數和數據集的詳細信息,請參閱'./ examples/example.py'
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' )要運行自己的模型,您應該使用JSON配置文件中的“ Load_Model()”中設置參數model 。
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )配置是這樣的JSON文件
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
文件夾examples提供了更多詳細信息。
如果您發現Rocketqa V1模型有所幫助,請隨時引用我們的出版物Rocketqa:一種優化的培訓方法,可用於張開通道檢索,以回答
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
如果您發現配對模型有幫助,請隨時引用我們的出版物對:利用以段落為中心的相似性關係以改善密集的通道檢索
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
如果您發現Rocketqa V2型號有用
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
如果您發現Dureader檢索數據集有用
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
如果您發現我們的調查對您的工作有用,請在基於驗證的語言模型中引用以下紙張密集文本檢索:一項調查
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
該存儲庫是在Apache-2.0許可下提供的。
有關使用RocketQA的幫助或問題,請提交GitHub問題。
有關其他溝通或合作,請聯繫Jing Liu([email protected])或掃描以下QR碼。



