RocketQA
1.0.0

В последние годы плотные ретриверы, основанные на предварительно обученных языковых моделях, достигли замечательного прогресса. Чтобы облегчить больше разработчиков, используя передовые технологии, этот репозиторий обеспечивает простой в использовании инструментарий для работы и точной настройки современных плотных ретриверов, а именно Rocketqa . Этот инструментарий имеет следующие преимущества:
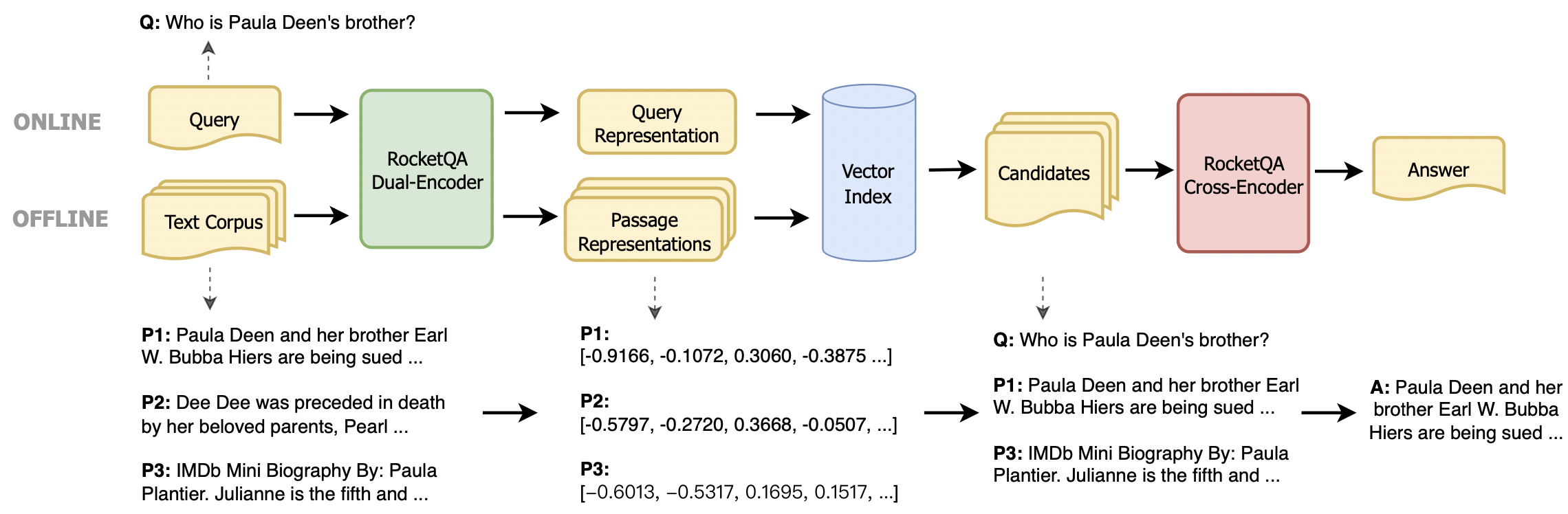
Мы предоставляем два метода установки: пакет установки Python и среда Docker
Во -первых, установите PaddlePaddle.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddleВо -вторых, установите пакет Rocketqa (последняя версия: 1.1.0):
$ pip install rocketqaПримечание. Этот инструментарий должен работать на Python3.6+ с PaddlePaddle 2.0+.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bashОбратитесь к примерам ниже, вы можете создать и запустить свою собственную поисковую систему с помощью нескольких строк кода. Мы также предоставляем детскую площадку с Jupyternotebook. Попробуйте Rocketqa сразу в своем браузере!
Джина-это облачная структура поиска нейронного анализа для создания SOTA и масштабируемых приложений поиска глубокого обучения за считанные минуты. Вот простой пример создания поисковой системы, основанной на Jina и Rocketqa.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cliПожалуйста, просмотрите пример JINA, чтобы узнать больше.
Мы также приводим простой пример, построенный на Faiss.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyВы также можете легко интегрировать Rocketqa в свою собственную задачу. Мы предоставляем два типа моделей, двойной энкодер на базе Ernie для поиска ответов и Cross Encoder на основе Эрни для повторного рейтинга. Для запуска наших моделей вы можете использовать следующие функции.
rocketqa.available_models()Возвращает имена доступных моделей Rocketqa. Чтобы узнать больше о доступных моделях, см. Код комментарий.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)Возвращает модель, указанную входным параметром. Он может инициализировать как двойной энкодер, так и поперечный энкодер. Установив параметр ввода, вы можете загрузить либо модели RocketQA, возвращаемые «office_models ()», либо ваши собственные контрольно -пропускные пункты.
Двойной кодер возвращается "load_model ()" поддерживает следующие функции:
model.encode_query(query: List[str])Учитывая список запросов, возвращает их векторы представления, кодируемые моделью.
model.encode_para(para: List[str], title: List[str])Учитывая список абзацев и соответствующих их названий (необязательно), возвращает их векторы представлений, кодируемые моделью.
model.matching(query: List[str], para: List[str], title: List[str])Учитывая список запросов и параграфов (и названий), возвращает свои соответствующие оценки (точечный продукт между двумя векторами представления).
model.train(train_set: str, epoch: int, save_model_path: str, args) Учитывая гиперпараметры train_set , epoch и save_model_path , вы можете обучить свою собственную модель с двойным энкодером или Finetune наши модели. Другие настройки, такие как save_steps и learning_rate также могут быть установлены в args . Пожалуйста, обратитесь к примерам/example.py для получения подробной информации.
Поперечный кодер возвращается "LOAD_MODEL ()" поддерживает следующую функцию:
model.matching(query: List[str], para: List[str], title: List[str])Учитывая список запросов и абзацев (и названий), возвращает свои сопоставления (вероятность того, что абзац является правильным ответом запроса).
model.train(train_set: str, epoch: int, save_model_path: str, args) Учитывая гиперпараметры train_set , epoch и save_model_path , вы можете обучить свою собственную модель Cross Encoder или Finetune наши модели. Другие настройки, такие как save_steps и learning_rate также могут быть установлены в args . Пожалуйста, обратитесь к примерам/example.py для получения подробной информации.
Следуя примерам ниже, вы можете получить векторные представления о ваших документах и подключить Rocketqa с вашими собственными задачами.
Чтобы запустить модели RocketQA, вы должны установить model параметров в 'Load_Model ()' с именем модели RocketQA, возвращаемом 'revare_models ()'.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) Чтобы обучить свои собственные модели, вы можете использовать функцию train() с вашим набором данных и параметрами. Данные обучения содержат 4 столбца: запрос, заголовок, пара, метка (0 или 1), разделенные « t». Для получения подробной информации о параметрах и наборе данных, пожалуйста, см.
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) Чтобы запустить свои собственные модели, вы должны установить model параметров в 'Load_Model ()' с файлом конфигурации JSON.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )config - это файл JSON
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
examples папок предоставляют более подробную информацию.
Если вы обнаружите, что модели Rocketqa V1 полезны, не стесняйтесь цитировать нашу публикацию Rocketqa: оптимизированный подход обучения к плотному поиску отрыва для ответа на вопрос открытого домена.
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
Если вы найдете полезные парные модели, не стесняйтесь ссылаться на нашу пару публикации: использование отношения сходства, ориентированного на проходы, для улучшения плотного отпуска
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Если вы обнаружите, что модели Rocketqa V2 полезны, не стесняйтесь цитировать нашу публикацию RocketQav2: метод совместного обучения для плотного извлечения и повторного прохода
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Если вы обнаружите, что набор данных поиска Dureader полезным, не стесняйтесь цитировать нашу публикацию Dureader_retrieval: крупномасштабный китайский эталон для поиска прохода из веб-поисковой системы
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
Если вы найдете нашу опрос полезным для вашей работы, пожалуйста, укажите следующую бумажную плотную листу
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
Этот репозиторий предоставляется по лицензии Apache-2.0.
Для получения помощи или проблем с использованием RocketQA, пожалуйста, отправьте проблему GitHub.
Для другого общения или сотрудничества, пожалуйста, свяжитесь с Jing Liu ([email protected]) или сканируйте следующий QR -код.



