RocketQA
1.0.0

최근 몇 년 동안, 미리 훈련 된 언어 모델을 기반으로 한 조밀 한 리트리버는 놀라운 진보를 달성했습니다. 최첨단 기술을 사용하여 더 많은 개발자를 용이하게하기 위해이 저장소는 최첨단 조밀 한 리트리버, 즉 Rocketqa를 실행하고 미세 조정하기위한 사용하기 쉬운 툴킷을 제공합니다. 이 툴킷에는 다음과 같은 장점이 있습니다.
우리는 두 가지 설치 방법을 제공합니다 : Python 설치 패키지 및 Docker Environment
먼저 PaddlePaddle을 설치하십시오.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddle둘째, RocketQa 패키지를 설치합니다 (최신 버전 : 1.1.0) :
$ pip install rocketqa참고 :이 툴킷은 Python3.6+에서 PaddlePaddle 2.0+로 실행되어야합니다.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bash아래 예제를 참조하십시오. 여러 줄의 코드로 자체 검색 엔진을 빌드하고 실행할 수 있습니다. 우리는 또한 Jupyternotebook과 함께 놀이터를 제공합니다. 브라우저에서 바로 Rocketqa를 사용해보십시오!
Jina는 몇 분 안에 SOTA 및 확장 가능한 딥 러닝 검색 애플리케이션을 구축하기위한 클라우드 네이티브 신경 검색 프레임 워크입니다. 다음은 Jina와 Rocketqa를 기반으로 검색 엔진을 구축하는 간단한 예입니다.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cli더 많은 것을 알려면 Jina 예제를보십시오.
또한 Faiss에 구축 된 간단한 예제를 제공합니다.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyRocketqa를 자신의 작업에 쉽게 통합 할 수도 있습니다. 우리는 답변 검색을위한 Ernie 기반 듀얼 인코더의 두 가지 유형의 모델과 답변을위한 Ernie 기반 크로스 인코더를 제공합니다. 모델을 실행하려면 다음 기능을 사용할 수 있습니다.
rocketqa.available_models()사용 가능한 rocketqa 모델의 이름을 반환합니다. 사용 가능한 모델에 대한 자세한 내용은 코드 주석을 참조하십시오.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)입력 매개 변수로 지정된 모델을 반환합니다. 듀얼 인코더와 크로스 인코더를 모두 초기화 할 수 있습니다. 입력 매개 변수를 설정하면 "used_models ()"로 반환 된 RocketQa 모델 또는 자체 체크 포인트를로드 할 수 있습니다.
"load_model ()"에 의해 반환 된 듀얼 인코더는 다음 기능을 지원합니다.
model.encode_query(query: List[str])쿼리 목록이 주어지면 모델로 인코딩 된 표현 벡터를 반환합니다.
model.encode_para(para: List[str], title: List[str])단락 목록과 해당 제목 (선택 사항)이 주어지면 모델별로 인코딩 된 표현 벡터를 반환합니다.
model.matching(query: List[str], para: List[str], title: List[str])쿼리 및 단락 (및 제목) 목록이 주어지면 일치 점수 (두 표현 벡터 사이의 DOT 제품)를 반환합니다.
model.train(train_set: str, epoch: int, save_model_path: str, args) Hyperparameters train_set , epoch 및 save_model_path 가 주어지면 자신의 듀얼 인코더 모델을 훈련 시키거나 모델을 양조 할 수 있습니다. save_steps 및 learning_rate 와 같은 다른 설정도 args 에서 설정할 수 있습니다. 자세한 내용은 예제/example.py를 참조하십시오.
"load_model ()"에 의해 반환 된 Cross-Encoder는 다음 기능을 지원합니다.
model.matching(query: List[str], para: List[str], title: List[str])쿼리 및 단락 (및 제목) 목록이 주어지면 일치 점수를 반환합니다 (단락이 쿼리의 정답이 될 확률).
model.train(train_set: str, epoch: int, save_model_path: str, args) Hyperparameters train_set , epoch 및 save_model_path 가 주어지면 자신의 크로스 인코더 모델을 훈련 시키거나 모델을 정합 할 수 있습니다. save_steps 및 learning_rate 와 같은 다른 설정도 args 에서 설정할 수 있습니다. 자세한 내용은 예제/example.py를 참조하십시오.
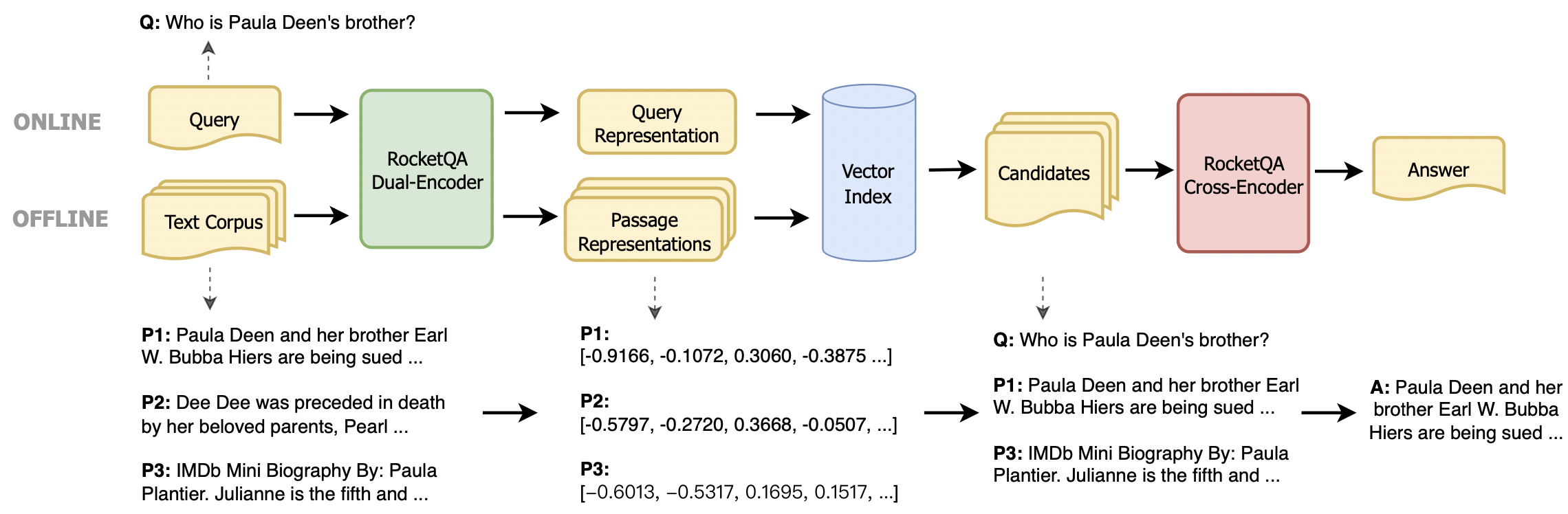
아래 예제에 따라 문서의 벡터 표현을 검색하고 RocketQA를 자신의 작업에 연결할 수 있습니다.
RocketQa 모델을 실행하려면 'ed용_models ()'에 의해 RocketQa 모델 이름을 사용하여 'load_model ()'에서 매개 변수 model 설정해야합니다.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) 자신의 모델을 훈련 시키려면 데이터 세트 및 매개 변수와 함께 train() 기능을 사용할 수 있습니다. 교육 데이터에는 " t"로 구분 된 쿼리, 제목, 파라, 레이블 (0 또는 1)의 4 개의 열이 포함됩니다. 매개 변수 및 데이터 세트에 대한 자세한 내용은 './examples/example.py'를 참조하십시오.
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) 자신의 모델을 실행하려면 JSON 구성 파일을 사용하여 'load_model ()'에서 매개 변수 model 설정해야합니다.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )구성은 이와 같은 JSON 파일입니다
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
폴더 examples 자세한 내용을 제공합니다.
Rocketqa V1 모델이 도움이된다면, 출판물을 자유롭게 인용하십시오. Rocketqa : 열린 도메인 질문 답변을위한 조밀 한 통과 검색을위한 최적화 된 훈련 접근법
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
쌍 모델이 도움이되는 것을 찾으면 출판물 쌍을 자유롭게 인용하십시오 : 조밀 한 통과 검색 개선을위한 통로 중심 유사성 관계
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Rocketqa v2 모델이 도움이되면 출판물을 자유롭게 인용하십시오.
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Dureader 검색 데이터 세트가 도움이된다면, 우리의 출판물을 자유롭게 인용하십시오 Dureader_Retrieval : 웹 검색 엔진에서 통과 검색을위한 대규모 중국 벤치 마크.
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
당사의 설문 조사에 유용한 경우, 사전에 사전 된 언어 모델을 기반으로 한 다음 논문의 조밀 한 텍스트 검색을 인용하십시오 : 설문 조사
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
이 저장소는 Apache-2.0 라이센스에 따라 제공됩니다.
Rocketqa를 사용하는 도움이나 문제는 Github 문제를 제출하십시오.
다른 커뮤니케이션 또는 협력은 Jing Liu ([email protected])에 문의하거나 다음 QR 코드를 스캔하십시오.



