RocketQA
1.0.0

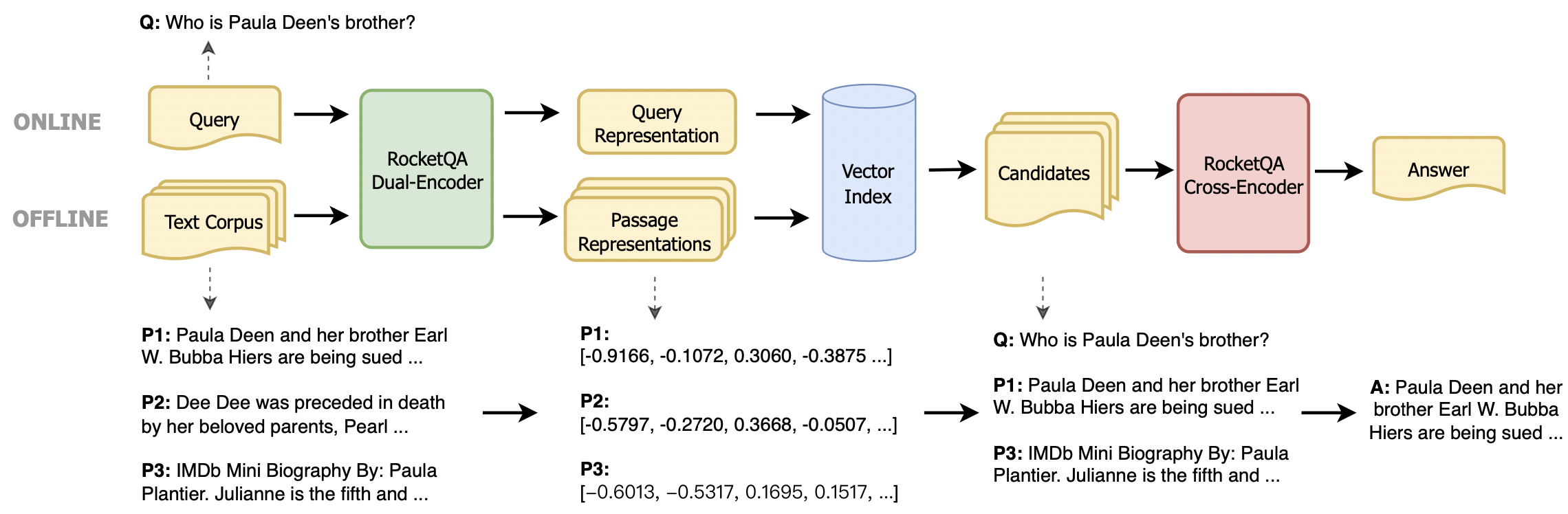
Dalam beberapa tahun terakhir, retriever padat berdasarkan model bahasa pra-terlatih telah mencapai kemajuan luar biasa. Untuk memfasilitasi lebih banyak pengembang menggunakan teknologi canggih, repositori ini menyediakan toolkit yang mudah digunakan untuk menjalankan dan menyempurnakan pengambil yang canggih, yaitu Rocketqa . Toolkit ini memiliki keunggulan berikut:
Kami menyediakan dua metode pemasangan: Paket Instalasi Python dan Lingkungan Docker
Pertama, pasang Paddlepaddle.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddleKedua, Instal Paket RocketQA (Versi Terbaru: 1.1.0):
$ pip install rocketqaCatatan: Toolkit ini harus berjalan di Python3.6+ dengan Paddlepaddle 2.0+.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bashLihat contoh di bawah ini, Anda dapat membangun dan menjalankan mesin pencari Anda sendiri dengan beberapa baris kode. Kami juga menyediakan taman bermain dengan jupyternotebook. Coba Rocketqa langsung di browser Anda!
Jina adalah kerangka pencarian saraf-asli cloud untuk membangun sota dan aplikasi pencarian pembelajaran mendalam yang dapat diskalakan dalam hitungan menit. Berikut adalah contoh sederhana untuk membangun mesin pencari berdasarkan Jina dan Rocketqa.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cliSilakan lihat contoh Jina untuk mengetahui lebih banyak.
Kami juga memberikan contoh sederhana yang dibangun di atas FAISS.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyAnda juga dapat dengan mudah mengintegrasikan Rocketqa ke dalam tugas Anda sendiri. Kami menyediakan dua jenis model, encoder ganda yang berbasis di Ernie untuk pengambilan jawaban dan encoder cross yang berbasis di Ernie untuk mendapatkan ulang jawaban. Untuk menjalankan model kami, Anda dapat menggunakan fungsi -fungsi berikut.
rocketqa.available_models()Mengembalikan nama -nama model RocketQA yang tersedia. Untuk mengetahui lebih banyak tentang model yang tersedia, silakan lihat komentar kode.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)Mengembalikan model yang ditentukan oleh parameter input. Ini dapat menginisialisasi dual encoder dan cross encoder. Dengan mengatur parameter input, Anda dapat memuat model RocketQA yang dikembalikan oleh "tersedia_models ()" atau pos pemeriksaan Anda sendiri.
Dual-encoder dikembalikan oleh "load_model ()" mendukung fungsi-fungsi berikut:
model.encode_query(query: List[str])Diberi daftar pertanyaan, kembalikan vektor representasi mereka yang dikodekan oleh model.
model.encode_para(para: List[str], title: List[str])Diberi daftar paragraf dan judul yang sesuai (opsional), mengembalikan vektor representasi mereka yang dikodekan oleh model.
model.matching(query: List[str], para: List[str], title: List[str])Diberi daftar pertanyaan dan paragraf (dan judul), mengembalikan skor pencocokan mereka (produk titik antara dua vektor representasi).
model.train(train_set: str, epoch: int, save_model_path: str, args) Mengingat hyperparameters train_set , epoch dan save_model_path , Anda dapat melatih model encoder ganda Anda sendiri atau finetune model kami. Pengaturan lain seperti save_steps dan learning_rate juga dapat diatur dalam args . Silakan merujuk ke contoh/example.py untuk detail.
Cross-encoder dikembalikan oleh "load_model ()" mendukung fungsi berikut:
model.matching(query: List[str], para: List[str], title: List[str])Diberi daftar pertanyaan dan paragraf (dan judul), mengembalikan skor pencocokan mereka (probabilitas bahwa paragraf adalah jawaban yang tepat kueri).
model.train(train_set: str, epoch: int, save_model_path: str, args) Mengingat hyperparameters train_set , epoch dan save_model_path , Anda dapat melatih model cross encoder Anda sendiri atau finetune model kami. Pengaturan lain seperti save_steps dan learning_rate juga dapat diatur dalam args . Silakan merujuk ke contoh/example.py untuk detail.
Mengikuti contoh -contoh di bawah ini, Anda dapat mengambil representasi vektor dari dokumen Anda dan menghubungkan Rocketqa ke tugas Anda sendiri.
Untuk menjalankan model RocketQA, Anda harus mengatur model parameter di 'load_model ()' dengan nama model RocketQA dikembalikan oleh 'tersedia_models ()'.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) Untuk melatih model Anda sendiri, Anda dapat menggunakan fungsi train() dengan dataset dan parameter Anda. Data pelatihan berisi 4 kolom: kueri, judul, para, label (0 atau 1), dipisahkan oleh " t". Untuk detail tentang parameter dan dataset, silakan merujuk ke './examples/example.py'
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) Untuk menjalankan model Anda sendiri, Anda harus mengatur model parameter di 'load_model ()' dengan file konfigurasi JSON.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )Config adalah file JSON seperti ini
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
examples folder memberikan detail lebih lanjut.
Jika Anda menemukan model Rocketqa V1 bermanfaat, jangan ragu untuk mengutip publikasi kami Rocketqa: pendekatan pelatihan yang dioptimalkan untuk pengambilan bagian yang padat untuk menjawab pertanyaan domain terbuka
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
Jika Anda menemukan model pasangan bermanfaat, jangan ragu untuk mengutip pasangan publikasi kami: memanfaatkan hubungan kesamaan yang berpusat pada bagian-bagian untuk meningkatkan pengambilan bagian yang padat
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Jika Anda menemukan model Rocketqa V2 bermanfaat, jangan ragu untuk mengutip publikasi kami Rocketqav2: Metode Pelatihan Bersama untuk Pengambilan Paling Lalat dan Perkecil Peringkat Peringkat
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Jika Anda menemukan Dureader Retrieval Dataset bermanfaat, jangan ragu untuk mengutip publikasi kami Dureader_Retrieval: Benchmark Cina skala besar untuk pengambilan bagian dari mesin pencari web Web
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
Jika Anda menemukan survei kami berguna untuk pekerjaan Anda, silakan kutip pengambilan teks padat kertas berikut berdasarkan model bahasa pretrained: sebuah survei
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
Repositori ini disediakan di bawah lisensi APACHE-2.0.
Untuk bantuan atau masalah menggunakan RocketQA, silakan kirimkan masalah GitHub.
Untuk komunikasi atau kerja sama lainnya, silakan hubungi Jing Liu ([email protected]) atau pindai kode QR berikut.



