RocketQA
1.0.0

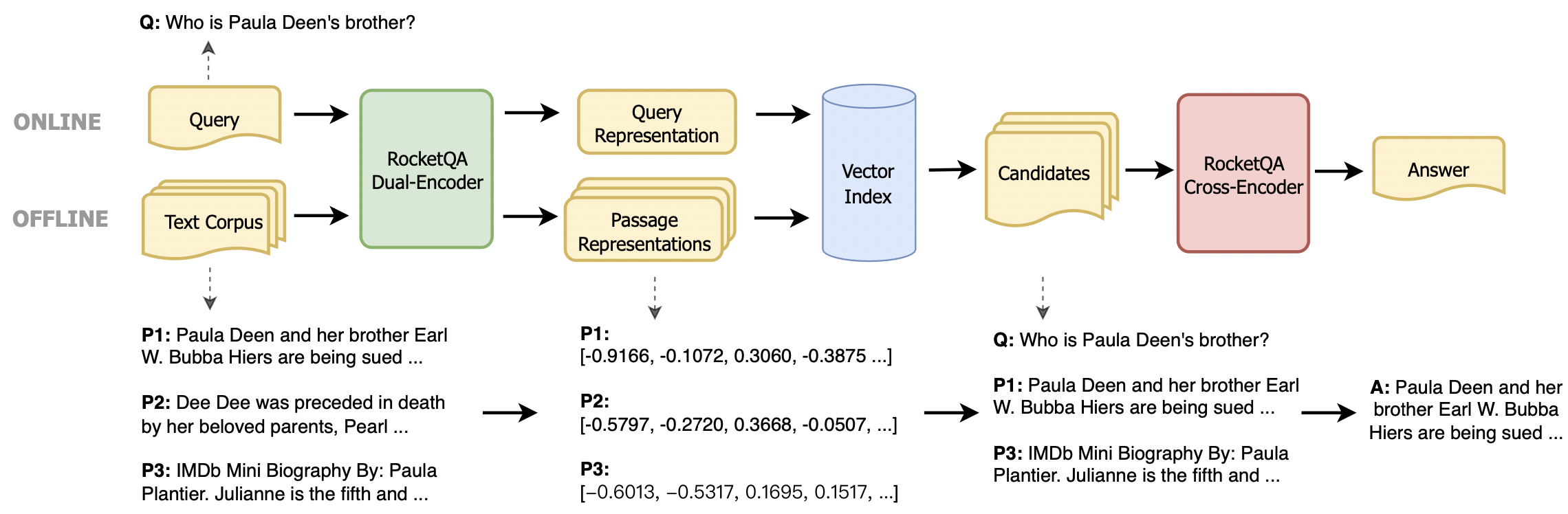
近年、事前に訓練された言語モデルに基づいた密集したレトリバーは、驚くべき進歩を達成しています。最先端のテクノロジーを使用してより多くの開発者を容易にするために、このリポジトリは、最先端の密集したレトリバー、つまりRocketQAを実行および微調整するための使いやすいツールキットを提供します。このツールキットには次の利点があります。
PythonインストールパッケージとDocker環境の2つのインストール方法を提供します
まず、パドルパドルをインストールします。
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddle第二に、RocketQAパッケージをインストールします(最新バージョン:1.1.0):
$ pip install rocketqa注:このツールキットは、パドルパドル2.0+を使用してPython3.6+で実行されている必要があります。
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bash以下の例を参照してください。いくつかのコードで独自の検索エンジンを構築および実行できます。また、Jupyternotebookで遊び場を提供しています。ブラウザですぐにRocketqaをお試しください!
Jinaは、数分でSOTAとスケーラブルなディープラーニング検索アプリケーションを構築するクラウドネイティブニューラル検索フレームワークです。 JinaとRocketqaに基づいた検索エンジンを構築する簡単な例を次に示します。
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cli詳細については、Jinaの例をご覧ください。
また、FAISS上に構築された簡単な例を提供します。
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyまた、RocketQAを独自のタスクに簡単に統合することもできます。回答検索用のアーニーベースのデュアルエンコーダーと、回答の再ランキング用のアーニーベースのクロスエンコーダの2種類のモデルを提供します。モデルを実行するには、次の機能を使用できます。
rocketqa.available_models()利用可能なRocketQAモデルの名前を返します。利用可能なモデルの詳細については、コードコメントをご覧ください。
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)入力パラメーターで指定されたモデルを返します。デュアルエンコーダーとクロスエンコーダーの両方を初期化できます。入力パラメーターを設定することにより、「available_models()」によって返されたRocketQAモデルまたは独自のチェックポイントのいずれかをロードできます。
「load_model()」によって返されたデュアルエンコーダーは、次の機能をサポートします。
model.encode_query(query: List[str])クエリのリストが与えられた場合、モデルによってエンコードされた表現ベクトルを返します。
model.encode_para(para: List[str], title: List[str])段落とその対応するタイトル(オプション)のリストが与えられ、モデルによってエンコードされた表現ベクトルを返します。
model.matching(query: List[str], para: List[str], title: List[str])クエリと段落(およびタイトル)のリストが与えられた場合、マッチングスコア(2つの表現ベクトル間のDOT製品)を返します。
model.train(train_set: str, epoch: int, save_model_path: str, args) HyperParameters train_set 、 epoch 、 save_model_pathを考えると、独自のデュアルエンコーダーモデルをトレーニングするか、モデルをFintuneできます。 save_stepsやlearning_rateなどのその他の設定もargsで設定できます。詳細については、例/example.pyを参照してください。
「load_model()」によって返されるクロスエンコーダーは、次の関数をサポートします。
model.matching(query: List[str], para: List[str], title: List[str])クエリと段落(およびタイトル)のリストが与えられた場合、マッチングスコアを返します(段落がクエリの正しい答えである可能性があります)。
model.train(train_set: str, epoch: int, save_model_path: str, args) HyperParameters train_set 、 epoch 、 save_model_pathを考えると、独自のクロスエンコーダーモデルをトレーニングするか、モデルをFintuneできます。 save_stepsやlearning_rateなどのその他の設定もargsで設定できます。詳細については、例/example.pyを参照してください。
以下の例に従って、ドキュメントのベクトル表現を取得し、RocketQAを独自のタスクに接続できます。
RocketQAモデルを実行するには、「load_model()」にパラメーターmodelを「load_model()」に設定する必要があります。
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list )独自のモデルをトレーニングするには、データセットとパラメーターでtrain()機能を使用できます。トレーニングデータには、「 t」で区切られたクエリ、タイトル、パラ、ラベル(0または1)の4つの列が含まれています。パラメーターとデータセットの詳細については、 './examples/example.py'を参照してください。
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' )独自のモデルを実行するには、JSON構成ファイルを使用して「load_model()」にパラメーターmodelを設定する必要があります。
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )構成はこのようなJSONファイルです
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
フォルダーのexamples 、詳細が記載されています。
Rocketqa V1モデルが役立つと思われる場合は、公開open-domain質問に応答するための密なパッセージ検索への最適化されたトレーニングアプローチの出版物を自由に引用してください。
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
ペアモデルが役立つと思われる場合は、お気軽に私たちの出版物ペアを引用してください。
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Rocketqa V2モデルが役立つと思われる場合は、お気軽に私たちの出版物を引用してくださいRocketQAV2:密集したパッセージ検索とパッセージの再ランクのための共同トレーニング方法
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Dureader検索データセットが役立つと思われる場合は、私たちの出版物を自由に引用してくださいdureader_retrieval:Web検索エンジンからのパッセージ検索のための大規模な中国のベンチマーク
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
私たちの調査があなたの仕事に役立つと思われる場合は、事前に支配された言語モデルに基づいて、次の論文密度の高いテキスト検索を引用してください:
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
このリポジトリは、Apache-2.0ライセンスの下で提供されます。
RocketQAを使用したヘルプまたは問題については、GitHubの問題を提出してください。
その他のコミュニケーションや協力については、Jing Liu([email protected])に連絡するか、次のQRコードをスキャンしてください。



