RocketQA
1.0.0

Nos últimos anos, os densos retrievers com base em modelos de idiomas pré-treinados alcançaram um progresso notável. Para facilitar mais desenvolvedores usando tecnologias de ponta, esse repositório fornece um kit de ferramentas fácil de usar para executar e ajustar os retrievers densos de ponta, a saber, Rocketqa . Este kit de ferramentas tem as seguintes vantagens:
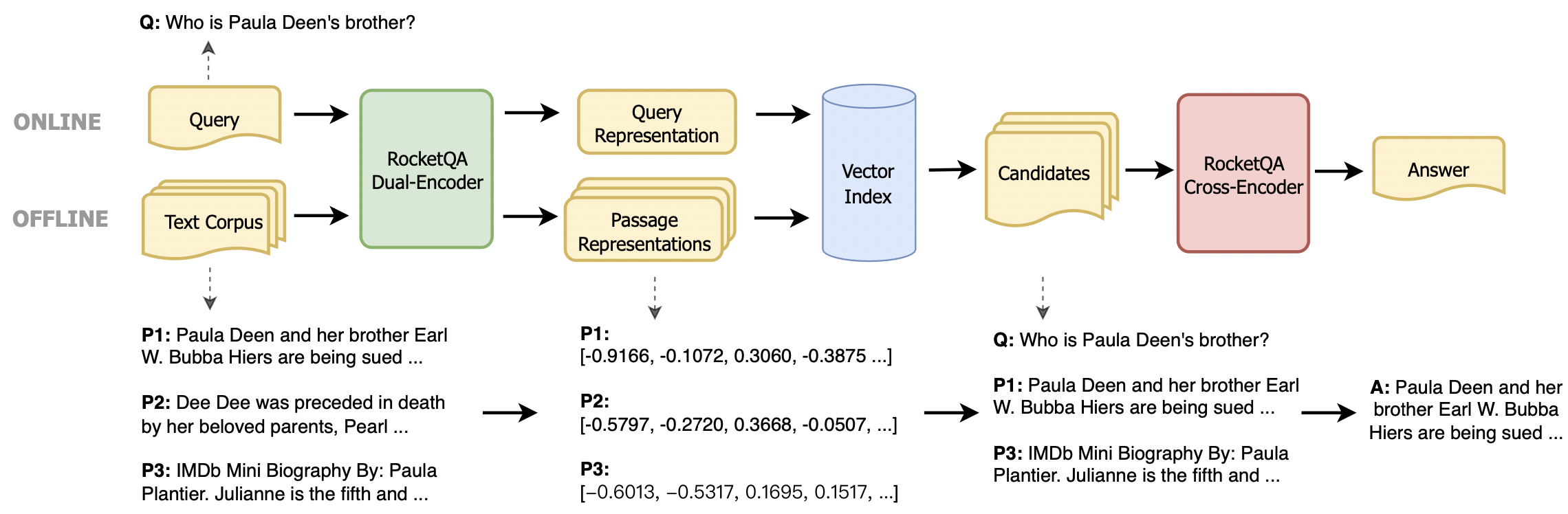
Fornecemos dois métodos de instalação: pacote de instalação do Python e ambiente de docker
Primeiro, instale o paddlepaddle.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddleSegundo, instale o pacote RocketQA (versão mais recente: 1.1.0):
$ pip install rocketqaNOTA: Este kit de ferramentas deve estar em execução no Python3.6+ com o PaddlePaddle 2.0+.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bashConsulte os exemplos abaixo, você pode criar e executar seu próprio mecanismo de pesquisa com várias linhas de código. Também fornecemos um playground com JupyTanotebook. Experimente o Rocketqa imediatamente no seu navegador!
Jina é uma estrutura de busca neural nativa em nuvem para criar aplicativos de pesquisa de aprendizado profundo e escalonáveis em minutos. Aqui está um exemplo simples para construir um mecanismo de pesquisa baseado em Jina e Rocketqa.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cliPor favor, veja o exemplo de Jina para saber mais.
Também fornecemos um exemplo simples construído sobre o FAISS.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyVocê também pode integrar facilmente o RocketQA em sua própria tarefa. Fornecemos dois tipos de modelos, o codificador duplo baseado em Ernie para recuperação de respostas e o codificador cruzado baseado em Ernie para renomeamento de respostas. Para executar nossos modelos, você pode usar as seguintes funções.
rocketqa.available_models()Retorna os nomes dos modelos Rocketqa disponíveis. Para saber mais sobre os modelos disponíveis, consulte o comentário do código.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)Retorna o modelo especificado pelo parâmetro de entrada. Ele pode inicializar o codificador duplo e o codificador cruzado. Ao definir o parâmetro de entrada, você pode carregar os modelos RocketQA retornados por "Disponível_models ()" ou seus próprios pontos de verificação.
O codificador duplo retornado por "load_model ()" suporta as seguintes funções:
model.encode_query(query: List[str])Dada uma lista de consultas, retorna seus vetores de representação codificados pelo modelo.
model.encode_para(para: List[str], title: List[str])Dada uma lista de parágrafos e seus títulos correspondentes (opcional), retorna seus vetores de representações codificados pelo modelo.
model.matching(query: List[str], para: List[str], title: List[str])Dada uma lista de consultas e parágrafos (e títulos), retorna suas pontuações correspondentes (produto DOT entre dois vetores de representação).
model.train(train_set: str, epoch: int, save_model_path: str, args) Dados os hyperparameters train_set , epoch e save_model_path , você pode treinar seu próprio modelo de codificador duplo ou Finetune nossos modelos. Outras configurações como save_steps e learning_rate também podem ser definidas no args . Consulte os exemplos/exemplo.py para obter detalhes.
O codificador cruzado retornado por "load_model ()" suporta a seguinte função:
model.matching(query: List[str], para: List[str], title: List[str])Dada uma lista de consultas e parágrafos (e títulos), retorna suas pontuações correspondentes (a probabilidade de o parágrafo ser a resposta certa da consulta).
model.train(train_set: str, epoch: int, save_model_path: str, args) Dados os hyperparameters train_set , epoch e save_model_path , você pode treinar seu próprio modelo de codificador cruzado ou Finetune nossos modelos. Outras configurações como save_steps e learning_rate também podem ser definidas no args . Consulte os exemplos/exemplo.py para obter detalhes.
Seguindo os exemplos abaixo, você pode recuperar as representações vetoriais de seus documentos e conectar o RocketQA às suas próprias tarefas.
Para executar os modelos RocketQA, você deve definir o model de parâmetro em 'load_model ()' com o nome do modelo RocketQA retornado por 'disponível_models ()'.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) Para treinar seus próprios modelos, você pode usar a função train() com seu conjunto de dados e parâmetros. Os dados de treinamento contêm 4 colunas: consulta, título, parágrafo, etiqueta (0 ou 1), separadas por " t". Para obter detalhes sobre parâmetros e conjunto de dados, consulte './examples/example.py'
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) Para executar seus próprios modelos, você deve definir model de parâmetro em 'load_model ()' com um arquivo de configuração JSON.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )Config é um arquivo json como este
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
examples de pastas fornecem mais detalhes.
Se você achar os modelos Rocketqa V1 úteis, sinta-se à vontade para citar nossa publicação Rocketqa: uma abordagem de treinamento otimizada para recuperar densas passagens para respostas de perguntas de domínio aberto
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
Se você achar os modelos de pares úteis, sinta-se à vontade para citar nosso par de publicação: alavancando a relação de similaridade centrada na passagem para melhorar a recuperação de passagem densa
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Se você achar os modelos Rocketqa V2 úteis, sinta-se à vontade para citar nossa publicação RocketQav2: um método de treinamento conjunto para recuperação de passagem densa e renomeamento de passagem
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Se você achar útil o conjunto de dados de recuperação do Dureader, sinta-se à vontade para citar nossa publicação Dureader_retrieval: um benchmark chinês em larga escala para recuperação de passagem do mecanismo de busca na web
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
Se você achar nossa pesquisa útil para o seu trabalho, cite a seguinte recuperação de texto densa em papel com base em modelos de idiomas pré -treinados: uma pesquisa
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
Este repositório é fornecido sob a licença Apache-2.0.
Para obter ajuda ou problemas usando o RocketQA, envie um problema do GitHub.
Para outra comunicação ou cooperação, entre em contato com Jing Liu ([email protected]) ou digitalize o seguinte código QR.



