RocketQA
1.0.0

Ces dernières années, les Retrievers denses basés sur des modèles de langage pré-formés ont réalisé des progrès remarquables. Pour faciliter davantage de développeurs à l'aide de technologies de pointe, ce référentiel fournit une boîte à outils facile à utiliser pour l'exécution et le réglage fin des retrievers dense de la pointe de la technologie, à savoir Rocketqa . Cette boîte à outils présente les avantages suivants:
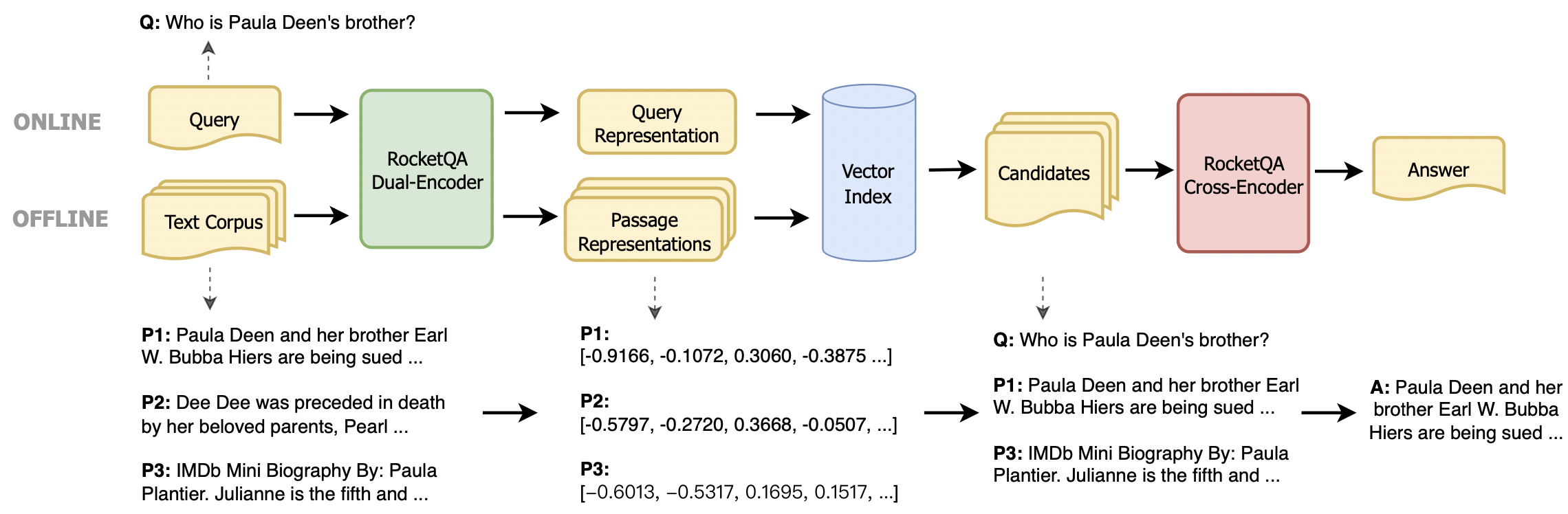
Nous fournissons deux méthodes d'installation: package d'installation Python et environnement Docker
Tout d'abord, installez paddlepaddle.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddleDeuxièmement, installer le package Rocketqa (dernière version: 1.1.0):
$ pip install rocketqaRemarque: Cette boîte à outils doit fonctionner sur Python3.6 + avec Paddlepaddle 2.0+.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bashReportez-vous aux exemples ci-dessous, vous pouvez créer et exécuter votre propre moteur de recherche avec plusieurs lignes de code. Nous fournissons également un terrain de jeu avec Jupyternotebook. Essayez immédiatement Rocketqa dans votre navigateur!
Jina est un cadre de recherche neuronale natif du cloud pour créer des applications de recherche de recherche en profondeur de profondeur évolutives en quelques minutes. Voici un exemple simple pour construire un moteur de recherche basé sur Jina et Rocketqa.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cliVeuillez consulter l'exemple de Jina pour en savoir plus.
Nous fournissons également un exemple simple construit sur Faish.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyVous pouvez également facilement intégrer Rocketqa dans votre propre tâche. Nous fournissons deux types de modèles, le double encodeur basé sur Ernie pour la récupération des réponses et l'encodeur croisé basé sur Ernie pour la réévaluation des réponses. Pour exécuter nos modèles, vous pouvez utiliser les fonctions suivantes.
rocketqa.available_models()Renvoie les noms des modèles Rocketqa disponibles. Pour en savoir plus sur les modèles disponibles, veuillez consulter le commentaire du code.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)Renvoie le modèle spécifié par le paramètre d'entrée. Il peut initialiser à la fois le double codeur et l'encodeur croisé. En définissant le paramètre d'entrée, vous pouvez charger les modèles RocketQA renvoyés par "Disponible_models ()" ou vos propres points de contrôle.
Le double encodeur renvoyé par "load_model ()" prend en charge les fonctions suivantes:
model.encode_query(query: List[str])Compte tenu d'une liste de requêtes, renvoie leurs vecteurs de représentation codés par modèle.
model.encode_para(para: List[str], title: List[str])Étant donné une liste de paragraphes et leurs titres correspondants (facultatif), renvoie leurs vecteurs de représentations codés par le modèle.
model.matching(query: List[str], para: List[str], title: List[str])Étant donné une liste de requêtes et de paragraphes (et de titres), renvoie leurs scores de correspondance (produit DOT entre deux vecteurs de représentation).
model.train(train_set: str, epoch: int, save_model_path: str, args) Compte tenu des hyperparamètres train_set , epoch et save_model_path , vous pouvez former votre propre modèle d'encodeur double ou FineTune nos modèles. D'autres paramètres comme save_steps et learning_rate peuvent également être définis dans args . Veuillez vous référer à des exemples / example.py pour le détail.
Cross-Encoder renvoyé par "load_model ()" prend en charge la fonction suivante:
model.matching(query: List[str], para: List[str], title: List[str])Compte tenu d'une liste de requêtes et de paragraphes (et de titres), renvoie leurs scores correspondants (probabilité que le paragraphe soit la bonne réponse de la requête).
model.train(train_set: str, epoch: int, save_model_path: str, args) Compte tenu des hyperparamètres train_set , epoch et save_model_path , vous pouvez former votre propre modèle d'encodeur croisé ou Finetune nos modèles. D'autres paramètres comme save_steps et learning_rate peuvent également être définis dans args . Veuillez vous référer à des exemples / example.py pour le détail.
En suivant les exemples ci-dessous, vous pouvez récupérer les représentations vectorielles de vos documents et connecter Rocketqa à vos propres tâches.
Pour exécuter des modèles ROCKETQA, vous devez définir le model de paramètre dans 'LOAD_MODEL ()' avec le nom du modèle ROCKETQA renvoyé par 'Disponible_Models ()'.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) Pour former vos propres modèles, vous pouvez utiliser la fonction train() avec votre ensemble de données et vos paramètres. Les données de formation contient 4 colonnes: requête, titre, para, étiquette (0 ou 1), séparées par " t". Pour plus de détails sur les paramètres et l'ensemble de données, veuillez vous référer à './examples/example.py'
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) Pour exécuter vos propres modèles, vous devez définir model de paramètre dans 'LOAD_MODEL ()' avec un fichier de configuration JSON.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )Config est un fichier JSON comme celui-ci
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
examples de dossiers fournissent plus de détails.
Si vous trouvez des modèles Rocketqa V1 utiles, n'hésitez pas à citer notre publication Rocketqa: une approche de formation optimisée de la récupération de passage dense pour la question de la question du domaine ouvert
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
Si vous trouvez des modèles de paires utiles, n'hésitez pas à citer notre paire de publication: tirant parti de la relation de similitude centrée sur le passage pour améliorer la récupération de passage dense
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Si vous trouvez des modèles Rocketqa V2 utiles, n'hésitez pas à citer notre publication RocketQav2: une méthode de formation conjointe pour la récupération de passage dense et le recommandation de passage
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Si vous trouvez un ensemble de données de récupération DureReader utile, n'hésitez pas à citer notre publication DUREREDER_RETRIEVAL: une référence chinoise à grande échelle pour la récupération de passage à partir de moteurs de recherche Web
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
Si vous trouvez notre enquête utile pour votre travail, veuillez citer la récupération de texte dense de l'article suivant basé sur des modèles de langue pré-étendue: une enquête
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
Ce référentiel est fourni sous la licence Apache-2.0.
Pour obtenir de l'aide ou des problèmes à l'aide de RocketQA, veuillez soumettre un problème GitHub.
Pour une autre communication ou coopération, veuillez contacter Jing Liu ([email protected]) ou numériser le code QR suivant.



