RocketQA
1.0.0

En los últimos años, los densos retrievers basados en modelos de lenguaje previamente capacitados han logrado un progreso notable. Para facilitar más desarrolladores utilizando tecnologías de vanguardia, este repositorio proporciona un kit de herramientas fácil de usar para ejecutar y ajustar a los densos retrievers de última generación, a saber, Rocketqa . Este kit de herramientas tiene las siguientes ventajas:
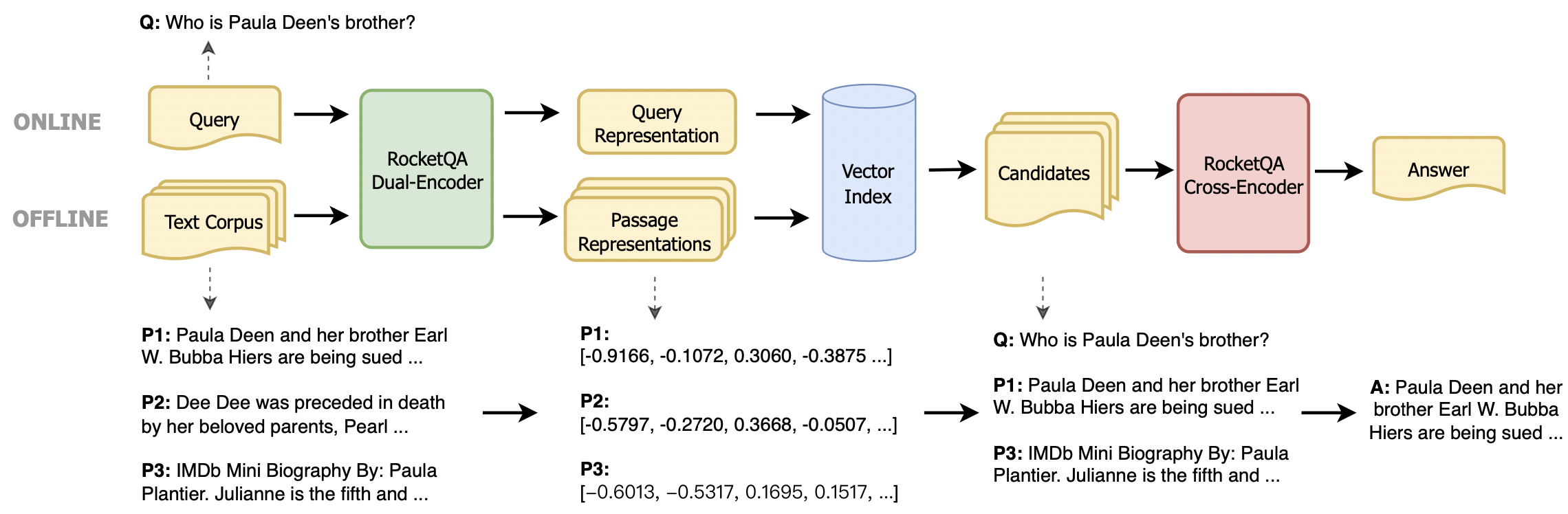
Proporcionamos dos métodos de instalación: paquete de instalación de Python y entorno Docker
Primero, instale paddlepaddle.
# GPU version:
$ pip install paddlepaddle-gpu
# CPU version:
$ pip install paddlepaddleSegundo, instale el paquete Rocketqa (última versión: 1.1.0):
$ pip install rocketqaNota: Este kit de herramientas debe estar ejecutándose en Python3.6+ con Paddlepaddle 2.0+.
docker pull rocketqa/rocketqa
docker run -it docker.io/rocketqa/rocketqa bashConsulte los ejemplos a continuación, puede construir y ejecutar su propio motor de búsqueda con varias líneas de código. También proporcionamos un patio de recreo con JupyternoteBook. ¡Prueba Rocketqa de inmediato en tu navegador!
Jina es un marco de búsqueda neuronal nativa de la nube para construir aplicaciones de búsqueda de aprendizaje profundo y escalable en minutos. Aquí hay un ejemplo simple para construir un motor de búsqueda basado en Jina y Rocketqa.
cd examples/jina_example
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
# JINA will automaticlly start a web service for you
python3 app.py index toy_data/test.tsv
# Try some questions related to the indexed Documents
python3 app.py query_cliVea el ejemplo de Jina para saber más.
También proporcionamos un ejemplo simple construido en FAISS.
cd examples/faiss_example/
pip3 install -r requirements.txt
# Generate vector representations and build a libray for your Documents
python3 index.py zh ../data/dureader.para test_index
# Start a web service on http://localhost:8888/rocketqa
python3 rocketqa_service.py zh ../data/dureader.para test_index
# Try some questions related to the indexed Documents
python3 query.pyTambién puede integrar fácilmente Rocketqa en su propia tarea. Proporcionamos dos tipos de modelos, el codificador dual con sede en Ernie para la recuperación de respuestas y el codificador cruzado con sede en Ernie para el reanimiento de las respuestas. Para ejecutar nuestros modelos, puede usar las siguientes funciones.
rocketqa.available_models()Devuelve los nombres de los modelos Rocketqa disponibles. Para saber más sobre los modelos disponibles, consulte el comentario del código.
rocketqa.load_model(model, use_cuda=False, device_id=0, batch_size=1)Devuelve el modelo especificado por el parámetro de entrada. Puede inicializar tanto el codificador dual como el codificador cruzado. Al establecer el parámetro de entrada, puede cargar los modelos Rocketqa devueltos por "Disponible_Models ()" o sus propios puntos de control.
Dual-coder devuelto por "load_model ()" admite las siguientes funciones:
model.encode_query(query: List[str])Dada una lista de consultas, devuelve sus vectores de representación codificados por modelo.
model.encode_para(para: List[str], title: List[str])Dada una lista de párrafos y sus títulos correspondientes (opcionales), devuelve sus vectores de representaciones codificados por modelo.
model.matching(query: List[str], para: List[str], title: List[str])Dada una lista de consultas y párrafos (y títulos), devuelve sus puntajes coincidentes (producto DOT entre dos vectores de representación).
model.train(train_set: str, epoch: int, save_model_path: str, args) Dado el HyperParameters train_set , epoch y save_model_path , puede entrenar su propio modelo de codificador dual o Finetune nuestros modelos. Otras configuraciones como save_steps y learning_rate también se pueden configurar en args . Consulte Ejemplos/Ejemplo.py para obtener detalles.
Cross-Endoder devuelto por "load_model ()" admite la siguiente función:
model.matching(query: List[str], para: List[str], title: List[str])Dada una lista de consultas y párrafos (y títulos), devuelve sus puntajes coincidentes (probabilidad de que el párrafo sea la respuesta correcta de la consulta).
model.train(train_set: str, epoch: int, save_model_path: str, args) Dado el HyperParameters train_set , epoch y save_model_path , puede entrenar su propio modelo de codificador cruzado o Finetune nuestros modelos. Otras configuraciones como save_steps y learning_rate también se pueden configurar en args . Consulte Ejemplos/Ejemplo.py para obtener detalles.
Siguiendo los ejemplos a continuación, puede recuperar las representaciones vectoriales de sus documentos y conectar Rocketqa con sus propias tareas.
Para ejecutar modelos Rocketqa, debe establecer el model de parámetro en 'Load_model ()' con el nombre del modelo Rocketqa devuelto por 'disponible_models ()'.
import rocketqa
query_list = [ "trigeminal definition" ]
para_list = [
"Definition of TRIGEMINAL. : of or relating to the trigeminal nerve.ADVERTISEMENT. of or relating to the trigeminal nerve. ADVERTISEMENT." ]
# init dual encoder
dual_encoder = rocketqa . load_model ( model = "v1_marco_de" , use_cuda = True , device_id = 0 , batch_size = 16 )
# encode query & para
q_embs = dual_encoder . encode_query ( query = query_list )
p_embs = dual_encoder . encode_para ( para = para_list )
# compute dot product of query representation and para representation
dot_products = dual_encoder . matching ( query = query_list , para = para_list ) Para capacitar a sus propios modelos, puede usar la función train() con su conjunto de datos y parámetros. Los datos de entrenamiento contienen 4 columnas: consulta, título, párr. Para obtener detalles sobre los parámetros y el conjunto de datos, consulte './examples/example.py'
import rocketqa
# init cross encoder, and set device and batch_size
cross_encoder = rocketqa . load_model ( model = "zh_dureader_ce" , use_cuda = True , device_id = 0 , batch_size = 32 )
# finetune cross encoder based on "zh_dureader_ce_v2"
cross_encoder . train ( './examples/data/cross.train.tsv' , 2 , 'ce_models' , save_steps = 1000 , learning_rate = 1e-5 , log_folder = 'log_ce' ) Para ejecutar sus propios modelos, debe establecer model de parámetros en 'load_model ()' con un archivo de configuración JSON.
import rocketqa
# init cross encoder
cross_encoder = rocketqa . load_model ( model = "./examples/ce_models/config.json" , use_cuda = True , device_id = 0 , batch_size = 16 )
# compute relevance of query and para
relevance = cross_encoder . matching ( query = query_list , para = para_list )config es un archivo json como este
{
"model_type": "cross_encoder",
"max_seq_len": 384,
"model_conf_path": "zh_config.json",
"model_vocab_path": "zh_vocab.txt",
"model_checkpoint_path": ${YOUR_MODEL},
"for_cn": true,
"share_parameter": 0
}
examples de carpetas proporcionan más detalles.
Si encuentra útiles los modelos Rocketqa V1, no dude en citar nuestra publicación Rocketqa: un enfoque de entrenamiento optimizado para la recuperación densa del pasaje para la respuesta de preguntas de dominio abierto
@inproceedings{rocketqa_v1,
title="RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering",
author="Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang",
year="2021",
booktitle = "In Proceedings of NAACL"
}
Si encuentra útiles los modelos de pares, no dude en citar nuestro par de publicaciones: aprovechando la relación de similitud centrada en el paso para mejorar la recuperación densa del pasaje
@inproceedings{rocketqa_pair,
title="PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval",
author="Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of ACL Findings"
}
Si encuentra útiles a los modelos Rocketqa V2, no dude en citar nuestra publicación Rocketqav2: un método de entrenamiento conjunto para la recuperación de pasos densos y el reanimación de pasaje
@inproceedings{rocketqa_v2,
title="RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking",
author="Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang and Ji-Rong Wen",
year="2021",
booktitle = "In Proceedings of EMNLP"
}
Si le resulta útil el conjunto de datos de recuperación de Dureader, no dude en citar nuestra publicación Dureader_retrieval: un punto de referencia chino a gran escala para la recuperación de pasaje del motor de búsqueda web
@inproceedings{DuReader_retrieval,
title="DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine",
author="Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, Qiaoqiao She, Jing Liu, Hua Wu and Haifeng Wang",
booktitle = "In Proceedings of EMNLP"
year="2022"
}
Si encuentra útil nuestra encuesta para su trabajo, cite la siguiente recuperación de texto denso en papel basada en modelos de lenguaje previos a la aparición: una encuesta
@article{DRSurvey,
title={Dense Text Retrieval based on Pretrained Language Models: A Survey},
author={Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen},
year={2022},
journal={arXiv preprint arXiv:2211.14876}
}
Este repositorio se proporciona bajo la licencia Apache-2.0.
Para obtener ayuda o problemas con Rocketqa, envíe un problema de GitHub.
Para otra comunicación o cooperación, comuníquese con Jing Liu ([email protected]) o escanee el siguiente código QR.



