languagemodels
1.0.0
Python的構建塊,以探索大型語言模型,僅為512MB RAM
該軟件包使使用Python的大型語言模型盡可能簡單。所有推論都是在本地執行的,以默認情況下將數據私有化。
可以使用以下命令安裝此軟件包:
pip install languagemodels安裝後,您應該能夠與Python中的軟件包進行交互,如下所示:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'這將需要在第一次運行中下載大量數據(〜250MB)。模型將被緩存以供以後使用,隨後的呼叫應很快。
以下是一些用法示例,例如Python repl會議。這應該在repl,筆記本或傳統腳本和應用程序中起作用。
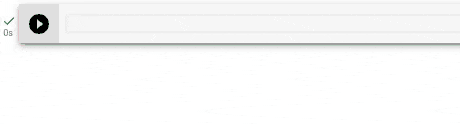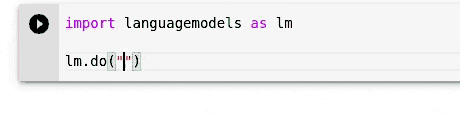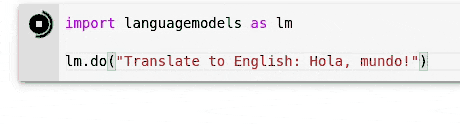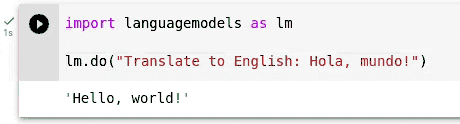
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'如果需要,則可以將輸出限制為選擇列表:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'基本模型應在任何具有512MB內存的系統上快速運行,但是可以增加此內存限制以選擇更強大的模型,以消耗更多資源。這是一個例子:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'如果您有可用CUDA的NVIDIA GPU,則可以選擇使用GPU進行推理:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'提供了輔助功能以從外部來源檢索可用於增強提示上下文的文本。
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'這是一個示例,顯示如何使用它(與以前的聊天示例進行比較):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'提供語義搜索以檢索可能提供文檔商店中有用上下文的文檔。
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'完整的文檔
由於INT8量化和Ctranslate2後端,該軟件包目前的表現優於CPU推理的Face transformers表現。下表使用20個問題測試集上的最佳可用量化在相同模型上比較了CPU推理性能。
| 後端 | 推理時間 | 使用的內存 |
|---|---|---|
| 擁抱面部變壓器 | 22s | 1.77GB |
| 這個包 | 11s | 0.34GB |
請注意,量化在技術上確實略微損害了產出質量,但在此級別應該可以忽略不計。
提供了明智的默認模型。隨著更強大的模型可用,該軟件包應隨著時間的推移而改善。所使用的基本型號比當今使用的最大型號小1000倍。它們作為學習工具很有用,但遠低於當前的最新狀態。
以下是該軟件包使用的當前默認模型,用於提供的max_ram值:
| max_ram | 模型名稱 | 參數(b) |
|---|---|---|
| 0.5 | Lamini-Flan-T5-248M | 0.248 |
| 1.0 | Lamini-Flan-T5-783M | 0.783 |
| 2.0 | Lamini-Flan-T5-783M | 0.783 |
| 4.0 | Flan-Alpaca-gpt4-Xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
對於代碼完成,使用CODET5+系列模型。
此軟件包本身已獲得商業用途的許可,但是所使用的模型可能與商業用途不兼容。為了商業使用此軟件包,您可以使用require_model_license函數通過許可類型過濾模型。
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'建議確認使用的模型滿足您軟件的許可要求。
該軟件包的目標之一是成為學習者和教育工作者的直接工具,以探索大型語言模型與現代軟件開發相交的方式。它可用於為許多學習項目做繁重的工作:
examples目錄中包含了幾個示例程序和筆記本。


