languagemodels
1.0.0
Pythonビルディングブロックは、わずか512MBのRAMで大きな言語モデルを探索します
このパッケージは、Pythonの大規模な言語モデルを可能な限り簡単に使用します。すべての推論は、デフォルトでデータをプライベートに保つためにローカルで実行されます。
このパッケージは、次のコマンドを使用してインストールできます。
pip install languagemodelsインストールしたら、次のようにPythonのパッケージと対話できるはずです。
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'これには、最初の実行時にかなりの量のデータ(〜250MB)をダウンロードする必要があります。モデルは後で使用するためにキャッシュされ、その後の呼び出しは迅速になります。
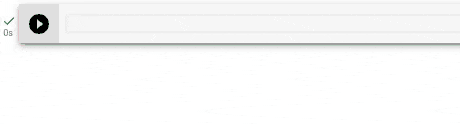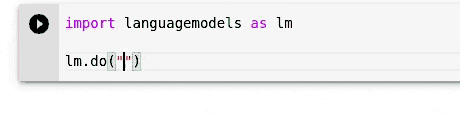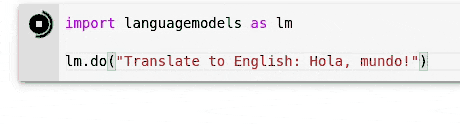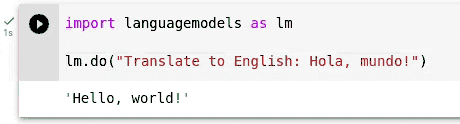
Python Repl Sessionsとしてのいくつかの使用例を以下に示します。これは、REPL、ノートブック、または従来のスクリプトやアプリケーションで機能するはずです。
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'出力は、必要に応じて選択肢のリストに制限できます。
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'ベースモデルは、512MBのメモリを備えたシステムで迅速に実行する必要がありますが、このメモリ制限を増やして、より多くのリソースを消費するより強力なモデルを選択できます。これが例です:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'CUDAが利用可能なNVIDIA GPUがある場合は、推論のためにGPUを使用することを選択できます。
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'ヘルパー関数は、迅速なコンテキストを増強するために使用できる外部ソースからテキストを取得するために提供されます。
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'これがどのように使用できるかを示す例を示します(以前のチャット例と比較してください):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'セマンティック検索は、ドキュメントストアから役立つコンテキストを提供する可能性のあるドキュメントを取得するために提供されます。
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'完全なドキュメント
現在、このパッケージは、INT8量子化とCTRASSLATE2バックエンドのおかげで、CPU推論のための抱き合ったフェイスtransformersを上回っています。次の表は、20の質問テストセットで最適な量子化を使用して、同一モデルのCPU推論パフォーマンスを比較しています。
| バックエンド | 推論時間 | 使用されるメモリ |
|---|---|---|
| フェイストランスを抱き締める | 22秒 | 1.77GB |
| このパッケージ | 11秒 | 0.34GB |
量子化は技術的に出力品質をわずかに損なうことに注意してくださいが、このレベルでは無視できるはずです。
賢明なデフォルトモデルが提供されます。より強力なモデルが利用可能になるにつれて、パッケージは時間の経過とともに改善されるはずです。使用されている基本モデルは、現在使用されている最大のモデルよりも1000倍小さいです。それらは学習ツールとして役立ちますが、現在の最新技術をはるかに下回っています。
提供されたmax_ram値のためにパッケージで使用されている現在のデフォルトモデルは次のとおりです。
| max_ram | モデル名 | パラメーター(b) |
|---|---|---|
| 0.5 | Lamini-Flan-T5-248m | 0.248 |
| 1.0 | Lamini-Flan-T5-783M | 0.783 |
| 2.0 | Lamini-Flan-T5-783M | 0.783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
コードの完了には、モデルのCodet5+シリーズが使用されます。
このパッケージ自体は商業用にライセンスされていますが、使用されるモデルは商業用使用と互換性がない場合があります。このパッケージを商業的に使用するために、 require_model_license関数を使用してライセンスタイプごとにモデルをフィルタリングできます。
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'使用したモデルがソフトウェアのライセンス要件を満たしていることを確認することをお勧めします。
このパッケージの目標の1つは、学習者と教育者が最新のソフトウェア開発とどの程度の言語モデルが交差するかを探るための簡単なツールになることです。多くの学習プロジェクトのために重い持ち上げを行うために使用できます。
いくつかのサンプルプログラムとノートブックは、 examplesディレクトリに含まれています。


