languagemodels
1.0.0
512MB의 RAM만의 큰 언어 모델을 탐색하는 파이썬 빌딩 블록
이 패키지는 Python의 대형 언어 모델을 가능한 한 간단하게 사용합니다. 모든 추론은 기본적으로 데이터를 비공개로 유지하기 위해 로컬로 수행됩니다.
이 패키지는 다음 명령을 사용하여 설치할 수 있습니다.
pip install languagemodels설치되면 다음과 같이 Python의 패키지와 상호 작용할 수 있어야합니다.
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'이를 위해서는 첫 번째 실행에 상당한 양의 데이터 (~ 250MB)를 다운로드해야합니다. 나중에 사용하기 위해 모델이 캐시되며 후속 통화는 빠릅니다.
Python Reply Sessions와 같은 몇 가지 사용 예는 다음과 같습니다. 이것은 REP, 노트북 또는 전통적인 스크립트 및 응용 프로그램에서 작동해야합니다.
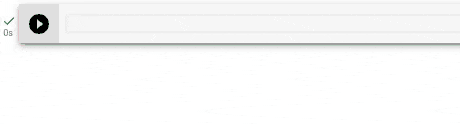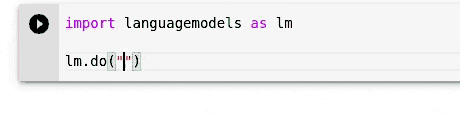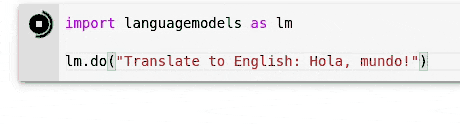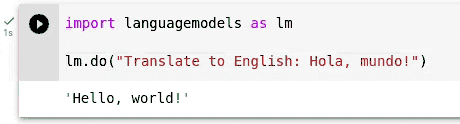
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'원하는 경우 출력은 선택 목록으로 제한 될 수 있습니다.
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'기본 모델은 512MB의 메모리가있는 모든 시스템에서 빠르게 실행되어야하지만이 메모리 제한을 증가시켜 더 많은 리소스를 소비 할보다 강력한 모델을 선택할 수 있습니다. 예는 다음과 같습니다.
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'CUDA가 포함 된 NVIDIA GPU가있는 경우 추론을 위해 GPU를 사용하도록 선택할 수 있습니다.
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'헬퍼 기능은 프롬프트 컨텍스트를 보강하는 데 사용할 수있는 외부 소스에서 텍스트를 검색하기 위해 제공됩니다.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'다음은 사용 방법을 보여주는 예입니다 (이전 채팅 예제와 비교) :
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'Semantic Search는 문서 저장소에서 유용한 컨텍스트를 제공 할 수있는 문서를 검색하기 위해 제공됩니다.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'전체 문서
이 패키지는 현재 Int8 Quantization 및 Ctranslate2 백엔드 덕분에 CPU 추론을위한 포옹 얼굴 transformers 보다 우수합니다. 다음 표는 20 개의 질문 테스트 세트에서 가장 많이 사용 가능한 양자화를 사용하여 동일한 모델에서 CPU 추론 성능을 비교합니다.
| 백엔드 | 추론 시간 | 사용 된 메모리 |
|---|---|---|
| 포옹 얼굴 변압기 | 22S | 1.77GB |
| 이 패키지 | 11s | 0.34GB |
양자화는 기술적으로 출력 품질에 약간 해를 끼치지만이 수준에서는 무시할 수 있어야합니다.
현명한 기본 모델이 제공됩니다. 강력한 모델을 사용할 수있게되면서 패키지는 시간이 지남에 따라 향상되어야합니다. 사용 된 기본 모델은 오늘날 사용중인 가장 큰 모델보다 1000 배 작습니다. 그것들은 학습 도구로 유용하지만 현재의 최신 상태보다 훨씬 낮습니다.
다음은 패키지에서 제공된 max_ram 값에 사용 된 현재 기본 모델입니다.
| max_ram | 모델 이름 | 매개 변수 (b) |
|---|---|---|
| 0.5 | lamini-flan-t5-248m | 0.248 |
| 1.0 | lamini-flan-t5-783m | 0.783 |
| 2.0 | lamini-flan-t5-783m | 0.783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
코드 완료의 경우 Codet5+ 일련의 모델이 사용됩니다.
이 패키지 자체는 상업용 용도로 라이센스가 부여되지만 사용 된 모델은 상업용 사용과 호환되지 않을 수 있습니다. 이 패키지를 상업적으로 사용하려면 require_model_license 함수를 사용하여 라이센스 유형별로 모델을 필터링 할 수 있습니다.
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'사용 된 모델이 소프트웨어의 라이센스 요구 사항을 충족하는지 확인하는 것이 좋습니다.
이 패키지의 목표 중 하나는 최신 언어 모델이 현대 소프트웨어 개발과 어떻게 교차하는지 탐구하는 학습자와 교육자에게 간단한 도구가되는 것입니다. 여러 학습 프로젝트를 위해 무거운 리프팅을하는 데 사용될 수 있습니다.
몇 가지 예제 프로그램과 노트북이 examples 디렉토리에 포함되어 있습니다.


