languagemodels
1.0.0
Python Building Blocks para explorar grandes modelos de linguagem em apenas 512 MB de RAM
Este pacote torna o uso de grandes modelos de linguagem do Python o mais simples possível. Toda a inferência é realizada localmente para manter seus dados privados por padrão.
Este pacote pode ser instalado usando o seguinte comando:
pip install languagemodelsDepois de instalado, você poderá interagir com o pacote em Python da seguinte maneira:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'Isso exigirá o download de uma quantidade significativa de dados (~ 250 MB) na primeira execução. Os modelos serão armazenados em cache para uso posterior e as chamadas subsequentes devem ser rápidas.
Aqui estão alguns exemplos de uso como sessões de replicação do Python. Isso deve funcionar no Repl, notebooks ou em scripts e aplicativos tradicionais.
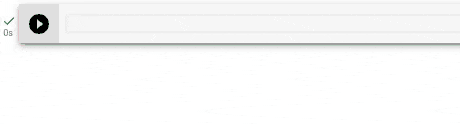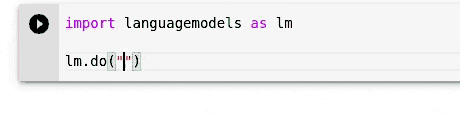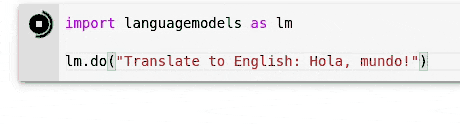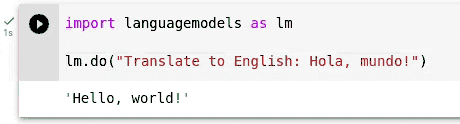
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'As saídas podem ser restritas a uma lista de opções, se desejar:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'O modelo básico deve ser executado rapidamente em qualquer sistema com 512 MB de memória, mas esse limite de memória pode ser aumentado para selecionar modelos mais poderosos que consumirão mais recursos. Aqui está um exemplo:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'Se você possui uma GPU da NVIDIA com CUDA disponível, poderá optar por usar a GPU para inferência:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'As funções auxiliares são fornecidas para recuperar o texto de fontes externas que podem ser usadas para aumentar o contexto rápido.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'Aqui está um exemplo mostrando como isso pode ser usado (compare com o exemplo de bate -papo anterior):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'A pesquisa semântica é fornecida para recuperar documentos que podem fornecer um contexto útil de uma loja de documentos.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'Documentação completa
Atualmente, este pacote supera transformers de face abraçados para inferência da CPU, graças à quantização do INT8 e ao back -end do CTRANSLATE2. A tabela a seguir compara o desempenho da inferência da CPU em modelos idênticos usando a melhor quantização disponível em um conjunto de testes de 20 perguntas.
| Back -end | Tempo de inferência | Memória usada |
|---|---|---|
| Abraçando transformadores de rosto | 22s | 1,77 GB |
| Este pacote | 11s | 0,34 GB |
Observe que a quantização tecnicamente prejudica a qualidade da saída ligeiramente, mas deve ser insignificante nesse nível.
Modelos padrão sensatos são fornecidos. O pacote deve melhorar com o tempo à medida que os modelos mais fortes se tornam disponíveis. Os modelos básicos utilizados são 1000x menores que os maiores modelos em uso atualmente. Eles são úteis como ferramentas de aprendizado, mas têm um desempenho muito abaixo do estado atual da arte.
Aqui estão os modelos padrão atuais usados pelo pacote para um valor max_ram fornecido:
| max_ram | Nome do modelo | Parâmetros (B) |
|---|---|---|
| 0,5 | Lamini-FLAN-T5-248M | 0,248 |
| 1.0 | Lamini-FLAN-T5-783M | 0,783 |
| 2.0 | Lamini-FLAN-T5-783M | 0,783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
Para conclusões do código, a série de modelos CodeT5+ é usada.
Este pacote em si é licenciado para uso comercial, mas os modelos utilizados podem não ser compatíveis com o uso comercial. Para usar este pacote comercialmente, você pode filtrar modelos por tipo de licença usando a função require_model_license .
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'Recomenda -se confirmar que os modelos usados atendem aos requisitos de licenciamento para o seu software.
Um dos objetivos deste pacote é ser uma ferramenta direta para alunos e educadores que exploram como os grandes modelos de idiomas se cruzam com o desenvolvimento moderno de software. Pode ser usado para fazer o levantamento pesado de vários projetos de aprendizado:
Vários programas de exemplo e notebooks estão incluídos no diretório examples .


