languagemodels
1.0.0
Blok bangunan Python untuk mengeksplorasi model bahasa besar hanya dalam 512MB RAM
Paket ini membuat menggunakan model bahasa besar dari Python sesederhana mungkin. Semua inferensi dilakukan secara lokal untuk menjaga data Anda tetap pribadi secara default.
Paket ini dapat diinstal menggunakan perintah berikut:
pip install languagemodelsSetelah diinstal, Anda harus dapat berinteraksi dengan paket di Python sebagai berikut:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'Ini akan membutuhkan pengunduhan sejumlah besar data (~ 250MB) pada proses pertama. Model akan di -cache untuk digunakan nanti dan panggilan selanjutnya harus cepat.
Berikut adalah beberapa contoh penggunaan sebagai sesi replikan Python. Ini harus berfungsi di repl, notebook, atau dalam skrip dan aplikasi tradisional.
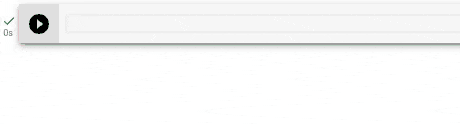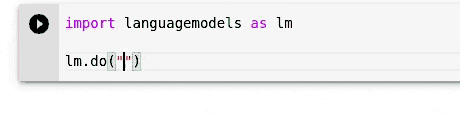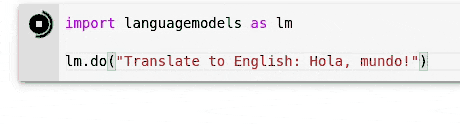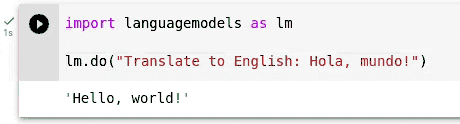
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'Output dapat dibatasi pada daftar pilihan jika diinginkan:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'Model dasar harus berjalan dengan cepat pada sistem apa pun dengan memori 512MB, tetapi batas memori ini dapat ditingkatkan untuk memilih model yang lebih kuat yang akan mengonsumsi lebih banyak sumber daya. Inilah contohnya:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'Jika Anda memiliki GPU NVIDIA dengan CUDA tersedia, Anda dapat memilih menggunakan GPU untuk inferensi:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'Fungsi helper disediakan untuk mengambil teks dari sumber eksternal yang dapat digunakan untuk menambah konteks yang cepat.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'Berikut contoh yang menunjukkan bagaimana ini dapat digunakan (bandingkan dengan contoh obrolan sebelumnya):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'Pencarian semantik disediakan untuk mengambil dokumen yang dapat memberikan konteks yang bermanfaat dari toko dokumen.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'Dokumentasi lengkap
Paket ini saat ini mengungguli memeluk transformers wajah untuk inferensi CPU berkat kuantisasi int8 dan backend Ctranslate2. Tabel berikut membandingkan kinerja inferensi CPU pada model yang identik menggunakan kuantisasi terbaik yang tersedia pada set uji 20 pertanyaan.
| Backend | Waktu kesimpulan | Memori yang digunakan |
|---|---|---|
| Memeluk transformator wajah | 22S | 1.77GB |
| Paket ini | 11S | 0.34GB |
Perhatikan bahwa kuantisasi secara teknis merusak kualitas keluaran sedikit, tetapi harus diabaikan pada level ini.
Model default yang masuk akal disediakan. Paket harus meningkat dari waktu ke waktu ketika model yang lebih kuat tersedia. Model dasar yang digunakan adalah 1000x lebih kecil dari model terbesar yang digunakan saat ini. Mereka berguna sebagai alat pembelajaran, tetapi berkinerja jauh di bawah keadaan seni saat ini.
Berikut adalah model default saat ini yang digunakan oleh paket untuk nilai max_ram yang disediakan:
| MAX_RAM | Nama model | Parameter (b) |
|---|---|---|
| 0,5 | LAMINI-FLAN-T5-248M | 0.248 |
| 1.0 | Lamini-Flan-T5-783M | 0.783 |
| 2.0 | Lamini-Flan-T5-783M | 0.783 |
| 4.0 | Flan-Alpaca-GPT4-XL | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
Untuk penyelesaian kode, serangkaian model CODET5+ digunakan.
Paket ini sendiri dilisensikan untuk penggunaan komersial, tetapi model yang digunakan mungkin tidak kompatibel dengan penggunaan komersial. Untuk menggunakan paket ini secara komersial, Anda dapat memfilter model berdasarkan jenis lisensi menggunakan fungsi require_model_license .
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'Disarankan untuk mengonfirmasi bahwa model yang digunakan memenuhi persyaratan lisensi untuk perangkat lunak Anda.
Salah satu tujuan untuk paket ini adalah menjadi alat langsung bagi pelajar dan pendidik yang mengeksplorasi bagaimana model bahasa besar bersinggungan dengan pengembangan perangkat lunak modern. Ini dapat digunakan untuk melakukan pengangkatan berat untuk sejumlah proyek pembelajaran:
Beberapa contoh program dan buku catatan disertakan dalam direktori examples .


