languagemodels
1.0.0
Python Builts Blocks para explorar modelos de idiomas grandes en tan solo 512 MB de RAM
Este paquete hace que el uso de modelos de idiomas grandes de Python sea lo más simple posible. Toda la inferencia se realiza localmente para mantener sus datos privados de forma predeterminada.
Este paquete se puede instalar utilizando el siguiente comando:
pip install languagemodelsUna vez instalado, debería poder interactuar con el paquete en Python de la siguiente manera:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'Esto requerirá descargar una cantidad significativa de datos (~ 250 MB) en la primera ejecución. Los modelos se almacenarán en caché para su uso posterior y las llamadas posteriores deben ser rápidas.
Aquí hay algunos ejemplos de uso como las sesiones de Python Reply. Esto debería funcionar en Repl, cuadernos o en scripts y aplicaciones tradicionales.
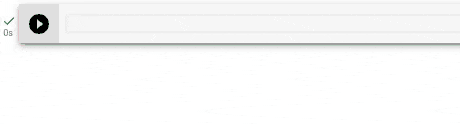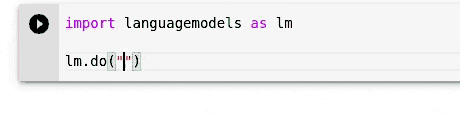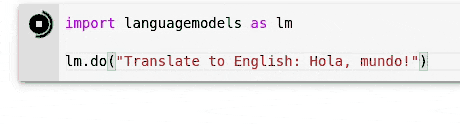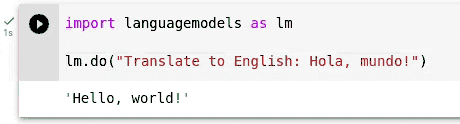
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'Las salidas pueden restringirse a una lista de opciones si lo desea:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'El modelo base debe ejecutarse rápidamente en cualquier sistema con 512 MB de memoria, pero este límite de memoria se puede aumentar para seleccionar modelos más potentes que consuman más recursos. Aquí hay un ejemplo:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'Si tiene una GPU NVIDIA con CUDA disponible, puede optar por usar la GPU para inferencia:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'Se proporcionan funciones auxiliares para recuperar el texto de fuentes externas que pueden usarse para aumentar el contexto inmediato.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'Aquí hay un ejemplo que muestra cómo se puede usar (comparar con el ejemplo de chat anterior):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'Se proporciona una búsqueda semántica para recuperar documentos que pueden proporcionar un contexto útil de una tienda de documentos.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'Documentación completa
Este paquete actualmente supera a transformers faciales de abrazos para la inferencia de la CPU gracias a la cuantización INT8 y al backend Ctranslate2. La siguiente tabla compara el rendimiento de la inferencia de la CPU en modelos idénticos utilizando la mejor cuantización disponible en un conjunto de pruebas de 20 preguntas.
| Backend | Tiempo de inferencia | Memoria utilizada |
|---|---|---|
| Abrazando los transformadores de la cara | 22 años | 1.77GB |
| Este paquete | 11s | 0.34 GB |
Tenga en cuenta que la cuantización da una ligera calidad de salida, pero debe ser insignificante en este nivel.
Se proporcionan modelos predeterminados sensibles. El paquete debería mejorar con el tiempo a medida que los modelos más fuertes estén disponibles. Los modelos básicos utilizados son 1000X más pequeños que los modelos más grandes en uso en la actualidad. Son útiles como herramientas de aprendizaje, pero se desempeñan muy por debajo del estado actual del arte.
Aquí están los modelos predeterminados actuales utilizados por el paquete para un valor max_ram suministrado:
| max_ram | Nombre del modelo | Parámetros (b) |
|---|---|---|
| 0.5 | Lamini-flan-t5-248m | 0.248 |
| 1.0 | Lamini-flan-t5-783m | 0.783 |
| 2.0 | Lamini-flan-t5-783m | 0.783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
Para las terminaciones de código, se utilizan la serie Codet5+ de modelos.
Este paquete en sí tiene licencia para uso comercial, pero los modelos utilizados pueden no ser compatibles con el uso comercial. Para usar este paquete comercialmente, puede filtrar los modelos por tipo de licencia utilizando la función require_model_license .
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'Se recomienda confirmar que los modelos utilizados cumplen con los requisitos de licencia para su software.
Uno de los objetivos para este paquete es ser una herramienta directa para estudiantes y educadores que exploran cómo los grandes modelos de idiomas se cruzan con el desarrollo moderno de software. Se puede usar para hacer el trabajo pesado para una serie de proyectos de aprendizaje:
Varios programas de ejemplo y cuadernos se incluyen en el directorio examples .


