languagemodels
1.0.0
Python -Bausteine, um große Sprachmodelle in nur 512 MB RAM zu erkunden
Dieses Paket ermöglicht es so einfach wie möglich mit großen Sprachmodellen aus Python. Alle Inferenz werden lokal durchgeführt, um Ihre Daten standardmäßig privat zu halten.
Dieses Paket kann mit dem folgenden Befehl installiert werden:
pip install languagemodelsNach der Installation sollten Sie in der Lage sein, mit dem Paket in Python wie folgt zu interagieren:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'Dies erfordert das Herunterladen einer erheblichen Datenmenge (~ 250 MB) im ersten Lauf. Modelle werden für die spätere Verwendung zwischengespeichert und nachfolgende Anrufe sollten schnell sein.
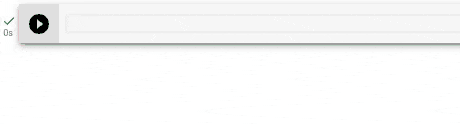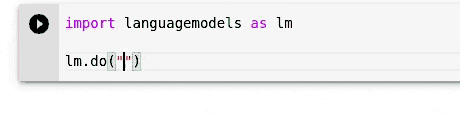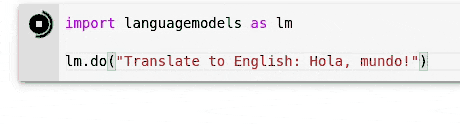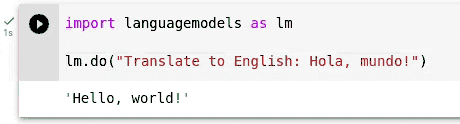
Hier sind einige Verwendungsbeispiele als Python -Replement -Sitzungen. Dies sollte in Repl, Notebooks oder traditionellen Skripten und Anwendungen funktionieren.
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'Die Ausgänge können auf Wunsch auf eine Liste von Auswahlmöglichkeiten beschränkt werden:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'Das Basismodell sollte schnell auf jedem System mit 512 MB Speicher ausgeführt werden. Diese Speichergrenze kann jedoch erhöht werden, um leistungsfähigere Modelle auszuwählen, die mehr Ressourcen konsumieren. Hier ist ein Beispiel:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'Wenn Sie eine Nvidia -GPU mit CUDA zur Verfügung haben, können Sie sich für die Inferenz verwenden:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'Helferfunktionen werden bereitgestellt, um Text aus externen Quellen abzurufen, mit denen der Umlaufkontext erweitert werden kann.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'Hier ist ein Beispiel, das zeigt, wie dies verwendet werden kann (verglichen mit früheren Chat -Beispielen):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'Semantische Suche wird bereitgestellt, um Dokumente abzurufen, die möglicherweise einen hilfreiche Kontext aus einem Dokumentgeschäft bieten.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'Vollständige Dokumentation
Dieses Paket übertrifft derzeit die Umarmung von transformers für die CPU -Inferenz dank der Int8 -Quantisierung und des Ctranslate2 -Backends. Die folgende Tabelle vergleicht die CPU -Inferenzleistung auf identischen Modellen unter Verwendung der besten verfügbaren Quantisierung eines 20 -Fragestestsatzes.
| Backend | Inferenzzeit | Speicher verwendet |
|---|---|---|
| Umarme Gesichtstransformatoren | 22s | 1,77 GB |
| Dieses Paket | 11s | 0,34 GB |
Beachten Sie, dass die Quantisierung die Ausgangsqualität geringfügig beeinträchtigt, aber auf dieser Ebene vernachlässigbar sein sollte.
Es werden vernünftige Standardmodelle bereitgestellt. Das Paket sollte sich im Laufe der Zeit verbessern, da stärkere Modelle verfügbar werden. Die verwendeten grundlegenden Modelle sind 1000x kleiner als die heute verwendeten Modelle. Sie sind nützlich als Lernwerkzeuge, funktionieren jedoch weit unter dem aktuellen Stand der Technik.
Hier sind die aktuellen Standardmodelle, die vom Paket für einen gelieferten max_ram -Wert verwendet werden:
| max_ram | Modellname | Parameter (b) |
|---|---|---|
| 0,5 | Lamini-Flan-T5-248m | 0,248 |
| 1.0 | Lamini-flan-T5-783m | 0,783 |
| 2.0 | Lamini-flan-T5-783m | 0,783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3,5-0106 | 7.0 |
Für den Codebettel werden die Modelle der Codet5+ verwendet.
Dieses Paket selbst ist für den kommerziellen Gebrauch lizenziert, die verwendeten Modelle sind jedoch möglicherweise nicht mit kommerzieller Verwendung kompatibel. Um dieses Paket kommerziell zu verwenden, können Sie Modelle nach Lizenztyp mit der Funktion require_model_license filtern.
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'Es wird empfohlen, zu bestätigen, dass die verwendeten Modelle die Lizenzanforderungen für Ihre Software erfüllen.
Eines der Ziele für dieses Paket ist es, ein unkompliziertes Werkzeug für Lernende und Pädagogen zu sein, die untersuchen, wie sich große Sprachmodelle mit der modernen Softwareentwicklung überschneiden. Es kann verwendet werden, um eine Reihe von Lernprojekten schwer zu heben:
Mehrere Beispielprogramme und Notizbücher sind im examples enthalten.


