languagemodels
1.0.0
Python Building Blocs pour explorer de grands modèles de langue en aussi peu que 512 Mo de RAM
Ce package rend l'utilisation de grands modèles de langage de Python aussi simple que possible. Toute l'inférence est effectuée localement pour garder vos données privées par défaut.
Ce package peut être installé à l'aide de la commande suivante:
pip install languagemodelsUne fois installé, vous devriez pouvoir interagir avec le package en python comme suit:
> >> import languagemodels as lm
> >> lm . do ( "What color is the sky?" )
'The color of the sky is blue.'Cela nécessitera le téléchargement d'une quantité importante de données (~ 250 Mo) lors de la première exécution. Les modèles seront mis en cache pour une utilisation ultérieure et les appels suivants devraient être rapides.
Voici quelques exemples d'utilisation en tant que sessions de remplacement Python. Cela devrait fonctionner dans les REP, les cahiers ou les scripts et applications traditionnels.
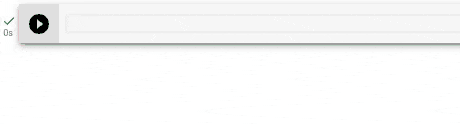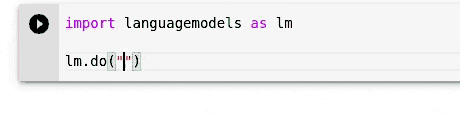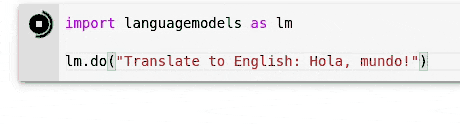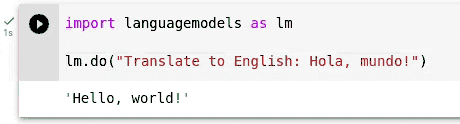
> >> import languagemodels as lm
> >> lm . do ( "Translate to English: Hola, mundo!" )
'Hello, world!'
> >> lm . do ( "What is the capital of France?" )
'Paris.'Les sorties peuvent être limitées à une liste de choix si vous le souhaitez:
> >> lm . do ( "Is Mars larger than Saturn?" , choices = [ "Yes" , "No" ])
'No'Le modèle de base doit fonctionner rapidement sur n'importe quel système avec 512 Mo de mémoire, mais cette limite de mémoire peut être augmentée pour sélectionner des modèles plus puissants qui consomment plus de ressources. Voici un exemple:
> >> import languagemodels as lm
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'You have 8 apples.'
> >> lm . config [ "max_ram" ] = "4gb"
4.0
> >> lm . do ( "If I have 7 apples then eat 5, how many apples do I have?" )
'I have 2 apples left.'Si vous avez un GPU NVIDIA avec CUDA disponible, vous pouvez vous opposer à l'utilisation du GPU pour l'inférence:
> >> import languagemodels as lm
> >> lm . config [ "device" ] = "auto" > >> import languagemodels as lm
> >> lm . complete ( "She hid in her room until" )
'she was sure she was safe'Des fonctions d'assistance sont fournies pour récupérer du texte à partir de sources externes qui peuvent être utilisées pour augmenter le contexte de l'invite.
> >> import languagemodels as lm
> >> lm . get_wiki ( 'Chemistry' )
' Chemistry is the scientific study ...
>> > lm . get_weather ( 41.8 , - 87.6 )
' Partly cloudy with a chance of rain ...
>> > lm . get_date ()
'Friday, May 12, 2023 at 09:27AM'Voici un exemple montrant comment cela peut être utilisé (par rapport à l'exemple de chat précédent):
> >> lm . do ( f"It is { lm . get_date () } . What time is it?" )
'The time is 12:53PM.'Une recherche sémantique est fournie pour récupérer des documents qui peuvent fournir un contexte utile dans un magasin de documents.
> >> import languagemodels as lm
> >> lm . store_doc ( lm . get_wiki ( "Python" ), "Python" )
> >> lm . store_doc ( lm . get_wiki ( "C language" ), "C" )
> >> lm . store_doc ( lm . get_wiki ( "Javascript" ), "Javascript" )
> >> lm . get_doc_context ( "What does it mean for batteries to be included in a language?" )
' From Python document : It is often described as a "batteries included" language due to its comprehensive standard library . Guido van Rossum began working on Python in the late 1980 s as a successor to the ABC programming language and first released it in 1991 as Python 0.9 .
From C document : It was designed to be compiled to provide low - level access to memory and language constructs that map efficiently to machine instructions , all with minimal runtime support .'Documentation complète
Ce package surpasse actuellement transformers de face étreintes pour l'inférence CPU grâce à la quantification INT8 et au backend CTRANSLATE2. Le tableau suivant compare les performances d'inférence du CPU sur des modèles identiques en utilisant la meilleure quantification disponible sur un ensemble de tests de questions.
| Backend | Temps d'inférence | Mémoire utilisée |
|---|---|---|
| Transformeurs de face étreintes | 22 | 1,77 Go |
| Ce package | 11 | 0,34 Go |
Notez que la quantification nuise techniquement à la qualité de la sortie légèrement, mais elle doit être négligeable à ce niveau.
Des modèles par défaut raisonnables sont fournis. Le package devrait s'améliorer avec le temps à mesure que des modèles plus forts deviennent disponibles. Les modèles de base utilisés sont 1000x plus petits que les plus grands modèles utilisés aujourd'hui. Ils sont utiles comme outils d'apprentissage, mais se produisent bien en dessous de l'état actuel de l'art.
Voici les modèles par défaut actuels utilisés par le package pour une valeur max_ram fournie:
| max_ram | Nom du modèle | Paramètres (b) |
|---|---|---|
| 0,5 | Lamini-Flan-T5-248M | 0,248 |
| 1.0 | Lamini-Flan-T5-783m | 0,783 |
| 2.0 | Lamini-Flan-T5-783m | 0,783 |
| 4.0 | flan-alpaca-gpt4-xl | 3.0 |
| 8.0 | OpenChat-3.5-0106 | 7.0 |
Pour les compléments de code, la série de modèles CODET5 + est utilisée.
Ce package lui-même est sous licence pour une utilisation commerciale, mais les modèles utilisés peuvent ne pas être compatibles avec une utilisation commerciale. Afin d'utiliser ce package commercialement, vous pouvez filtrer les modèles par type de licence à l'aide de la fonction require_model_license .
> >> import languagemodels as lm
> >> lm . config [ 'instruct_model' ]
'LaMini-Flan-T5-248M-ct2-int8'
> >> lm . require_model_license ( "apache|bsd|mit" )
> >> lm . config [ 'instruct_model' ]
'flan-t5-base-ct2-int8'Il est recommandé de confirmer que les modèles utilisés répondent aux exigences de licence pour votre logiciel.
L'un des objectifs de ce package est d'être un outil simple pour les apprenants et les éducateurs explorant la façon dont les grands modèles de langue se croisent avec le développement de logiciels moderne. Il peut être utilisé pour faire le gros du travail pour un certain nombre de projets d'apprentissage:
Plusieurs exemples de programmes et ordinateurs portables sont inclus dans le répertoire examples .


