LLM TPU
1.0.0

本項目實現算能BM1684X芯片部署各類開源生成式AI模型,其中以LLM為主。通過TPU-MLIR編譯器將模型轉換成bmodel,並採用c++代碼將其部署到PCIE環境或者SoC環境。在知乎上寫了一篇解讀,以ChatGLM2-6B為例,方便大家理解源碼:ChatGLM2流程解析與TPU-MLIR部署
已部署過的模型如下(按照首字母順序排列):
| Model | INT4 | INT8 | FP16/BF16 | Huggingface Link |
|---|---|---|---|---|
| Baichuan2-7B | ✅ | LINK | ||
| ChatGLM3-6B | ✅ | ✅ | ✅ | LINK |
| ChatGLM4-9B | ✅ | ✅ | ✅ | LINK |
| CodeFuse-7B | ✅ | ✅ | LINK | |
| DeepSeek-6.7B | ✅ | ✅ | LINK | |
| Falcon-40B | ✅ | ✅ | LINK | |
| Phi-3-mini-4k | ✅ | ✅ | ✅ | LINK |
| Qwen-7B | ✅ | ✅ | ✅ | LINK |
| Qwen-14B | ✅ | ✅ | ✅ | LINK |
| Qwen-72B | ✅ | LINK | ||
| Qwen1.5-0.5B | ✅ | ✅ | ✅ | LINK |
| Qwen1.5-1.8B | ✅ | ✅ | ✅ | LINK |
| Qwen1.5-7B | ✅ | ✅ | ✅ | LINK |
| Qwen2-7B | ✅ | ✅ | ✅ | LINK |
| Qwen2.5-7B | ✅ | ✅ | ✅ | LINK |
| Llama2-7B | ✅ | ✅ | ✅ | LINK |
| Llama2-13B | ✅ | ✅ | ✅ | LINK |
| Llama3-8B | ✅ | ✅ | ✅ | LINK |
| Llama3.1-8B | ✅ | ✅ | ✅ | LINK |
| LWM-Text-Chat | ✅ | ✅ | ✅ | LINK |
| MiniCPM3-4B | ✅ | ✅ | LINK | |
| Mistral-7B-Instruct | ✅ | ✅ | LINK | |
| Stable Diffusion | ✅ | LINK | ||
| Stable Diffusion XL | ✅ | LINK | ||
| WizardCoder-15B | ✅ | LINK | ||
| Yi-6B-chat | ✅ | ✅ | LINK | |
| Yi-34B-chat | ✅ | ✅ | LINK | |
| Qwen-VL-Chat | ✅ | ✅ | LINK | |
| Qwen2-VL-Chat | ✅ | ✅ | LINK | |
| InternVL2-4B | ✅ | ✅ | LINK | |
| InternVL2-2B | ✅ | ✅ | LINK | |
| MiniCPM-V-2_6 | ✅ | ✅ | LINK | |
| Llama3.2-Vision-11B | ✅ | ✅ | ✅ | LINK |
如果您想要知道轉換細節和源碼,可以到本項目models子目錄查看各類模型部署細節。
如果您對我們的芯片感興趣,也可以通過官網SOPHGO聯繫我們。
克隆LLM-TPU項目,並執行run.sh腳本
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7b詳細請參考Quick Start
跑通後效果如下圖所示
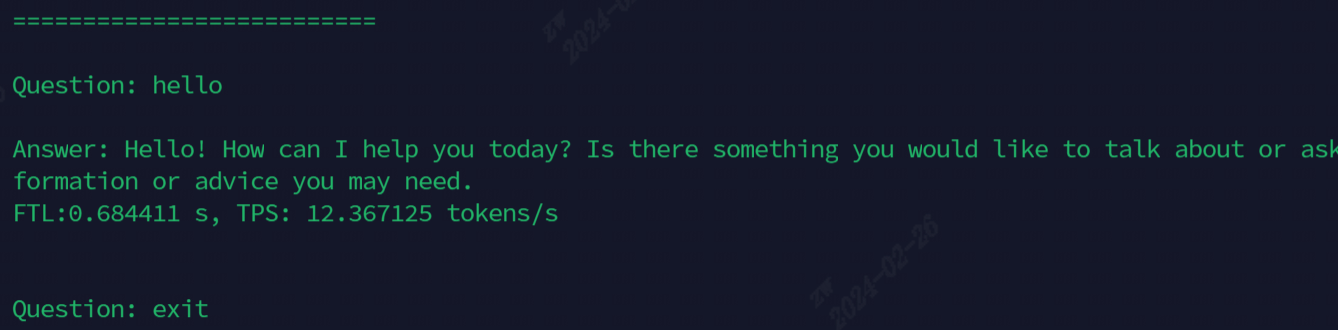
目前用於演示的模型,全部命令如下表所示
| Model | SoC | PCIE |
|---|---|---|
| ChatGLM3-6B | ./run.sh --model chatglm3-6b --arch soc | ./run.sh --model chatglm3-6b --arch pcie |
| Llama2-7B | ./run.sh --model llama2-7b --arch soc | ./run.sh --model llama2-7b --arch pcie |
| Llama3-7B | ./run.sh --model llama3-7b --arch soc | ./run.sh --model llama3-7b --arch pcie |
| Qwen-7B | ./run.sh --model qwen-7b --arch soc | ./run.sh --model qwen-7b --arch pcie |
| Qwen1.5-1.8B | ./run.sh --model qwen1.5-1.8b --arch soc | ./run.sh --model qwen1.5-1.8b --arch pcie |
| Qwen2.5-7B | ./run.sh --model qwen2.5-7b --arch pcie | |
| LWM-Text-Chat | ./run.sh --model lwm-text-chat --arch soc | ./run.sh --model lwm-text-chat --arch pcie |
| WizardCoder-15B | ./run.sh --model wizardcoder-15b --arch soc | ./run.sh --model wizardcoder-15b --arch pcie |
| InternVL2-4B | ./run.sh --model internvl2-4b --arch soc | ./run.sh --model internvl2-4b --arch pcie |
| MiniCPM-V-2_6 | ./run.sh --model minicpmv2_6 --arch soc | ./run.sh --model minicpmv2_6 --arch pcie |
進階功能說明:
| 功能 | 目錄 | 功能說明 |
|---|---|---|
| 多芯 | ChatGLM3/parallel_demo | 支持ChatGLM3 2芯 |
| Llama2/demo_parallel | 支持Llama2 4/6/8芯 | |
| Qwen/demo_parallel | 支持Qwen 4/6/8芯 | |
| Qwen1_5/demo_parallel | 支持Qwen1_5 4/6/8芯 | |
| 投機採樣 | Qwen/jacobi_demo | LookaheadDecoding |
| Qwen1_5/speculative_sample_demo | 投機採樣 | |
| prefill復用 | Qwen/prompt_cache_demo | 公共序列prefill復用 |
| Qwen/share_cache_demo | 公共序列prefill復用 | |
| Qwen1_5/share_cache_demo | 公共序列prefill復用 | |
| 模型加密 | Qwen/share_cache_demo | 模型加密 |
| Qwen1_5/share_cache_demo | 模型加密 |
請參考LLM-TPU常見問題及解答


