LLM TPU
1.0.0

Este proyecto se da cuenta de la implementación de varios生成式AI模型de código abierto para calcular chips BM1684X, principalmente LLM. El modelo se convierte en Bmodel a través del compilador TPU-MLIR y se implementa en un entorno PCIe o un entorno SOC que utiliza el código C ++. Escribí una explicación sobre Zhihu, tomando ChatGLM2-6B como ejemplo, para que todos puedan entender el código fuente: análisis de procesos chatglm2 e implementación de tpu-mlir
Los modelos implementados son los siguientes (organizados en orden alfabético):
| Modelo | Int4 | Int8 | FP16/BF16 | Enlace de Huggingface |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | ENLACE | ||
| Chatglm3-6b | ✅ | ✅ | ✅ | ENLACE |
| Chatglm4-9b | ✅ | ✅ | ✅ | ENLACE |
| CodeFuse-7b | ✅ | ✅ | ENLACE | |
| Deepseek-6.7b | ✅ | ✅ | ENLACE | |
| Falcon-40b | ✅ | ✅ | ENLACE | |
| Phi-3-mini-4k | ✅ | ✅ | ✅ | ENLACE |
| Qwen-7b | ✅ | ✅ | ✅ | ENLACE |
| Qwen-14b | ✅ | ✅ | ✅ | ENLACE |
| Qwen-72b | ✅ | ENLACE | ||
| QWEN1.5-0.5B | ✅ | ✅ | ✅ | ENLACE |
| Qwen1.5-1.8b | ✅ | ✅ | ✅ | ENLACE |
| Qwen1.5-7b | ✅ | ✅ | ✅ | ENLACE |
| Qwen2-7b | ✅ | ✅ | ✅ | ENLACE |
| Qwen2.5-7b | ✅ | ✅ | ✅ | ENLACE |
| Llama2-7b | ✅ | ✅ | ✅ | ENLACE |
| Llama2-13b | ✅ | ✅ | ✅ | ENLACE |
| Llama3-8b | ✅ | ✅ | ✅ | ENLACE |
| Llama3.1-8b | ✅ | ✅ | ✅ | ENLACE |
| LWM-Text-chat | ✅ | ✅ | ✅ | ENLACE |
| Minicpm3-4b | ✅ | ✅ | ENLACE | |
| Mistral-7B-Instructo | ✅ | ✅ | ENLACE | |
| Difusión estable | ✅ | ENLACE | ||
| Difusión estable XL | ✅ | ENLACE | ||
| WizardCoder-15B | ✅ | ENLACE | ||
| Yi-6b-chat | ✅ | ✅ | ENLACE | |
| Yi-34b-chat | ✅ | ✅ | ENLACE | |
| Qwen-vl-chat | ✅ | ✅ | ENLACE | |
| Qwen2-vl-chat | ✅ | ✅ | ENLACE | |
| Intervl2-4b | ✅ | ✅ | ENLACE | |
| Intervl2-2b | ✅ | ✅ | ENLACE | |
| Minicpm-v-2_6 | ✅ | ✅ | ENLACE | |
| Llama3.2-visión-11b | ✅ | ✅ | ✅ | ENLACE |
Si desea conocer los detalles de conversión y el código fuente, puede ir al subdirectorio de modelos de este proyecto para ver los detalles de implementación de varios modelos.
Si está interesado en nuestros chips, también puede contactarnos a través del sitio web oficial Sophgo.
Clon el proyecto LLM-TPU y ejecute el script run.sh
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7bConsulte el inicio rápido para obtener más detalles
El efecto después de correr se muestra en la siguiente figura
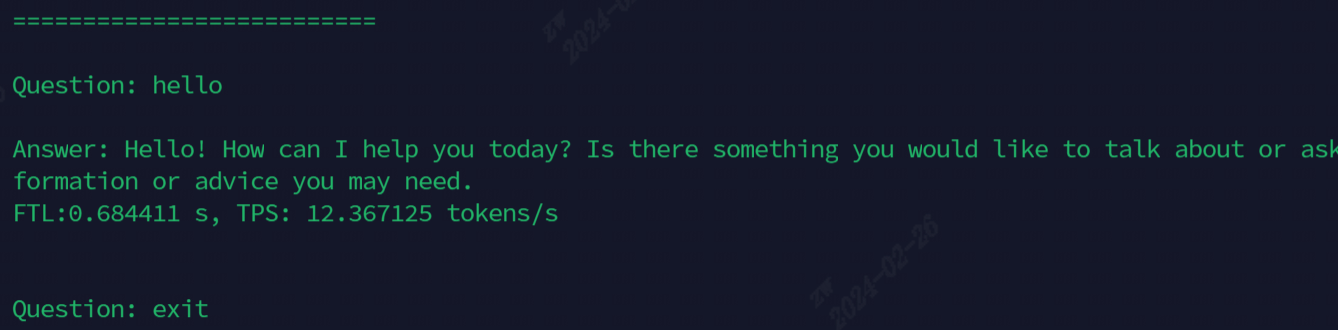
Los modelos utilizados actualmente para la demostración, todos los comandos se muestran en la siguiente tabla
| Modelo | Sociedad | Pítico |
|---|---|---|
| Chatglm3-6b | ./run.sh--Model ChatGlm3-6b-Arch Soc | ./run.sh --model chatglm3-6b --arch pcie |
| Llama2-7b | ./run.sh--Model Llama2-7b-Arch Soc | ./run.sh--Model Llama2-7b-Arch PCIe |
| Llama3-7b | ./run.sh--Model Llama3-7b-Arch Soc | ./run.sh--Model Llama3-7b-Arch PCIe |
| Qwen-7b | ./run.sh--Model Qwen-7b-Arch Soc | ./run.sh--Model Qwen-7b-Arch PCIe |
| Qwen1.5-1.8b | ./run.sh--Model Qwen1.5-1.8b-Arch Soc | ./run.sh--Model Qwen1.5-1.8b-Arch PCIe |
| Qwen2.5-7b | ./run.sh--Model Qwen2.5-7b-Arch PCIe | |
| LWM-Text-chat | ./run.sh --model lwm-text-chat --arch soc | ./run.sh --model lwm-text-chat --arch pcie |
| WizardCoder-15B | ./run.sh--Model WizardCoder-15b-Arch Soc | ./run.sh--Model WizardCoder-15b-Arch PCIe |
| Intervl2-4b | ./run.sh--Model Internvl2-4b-Arch Soc | ./run.sh--Model Internvl2-4b-Arch PCIe |
| Minicpm-v-2_6 | ./run.sh - -Model Minicv2_6 -Arch Soc | ./run.sh --model minicmv2_6 --arch pcie |
Descripción de la función avanzada:
| Función | Tabla de contenido | Descripción de la función |
|---|---|---|
| Multicore | Chatglm3/parallel_demo | Soporte de chatglm3 de 2 núcleos |
| Llama2/Demo_parallel | Soporte LLAMA2 4/6/8 Core | |
| Qwen/demo_parallel | Soporte QWen 4/6/8 núcleos | |
| Qwen1_5/demo_parallel | Soporte QWEN1_5 4/6/8 núcleos | |
| Muestreo especulativo | Qwen/jacobi_demo | LookAheadDecoding |
| Qwen1_5/especulativo_sample_demo | Muestreo especulativo | |
| reutilización de pregramación | QWEN/ARD_CACHE_DEMO | Multiplexación de la secuencia común de la secuencia |
| Qwen/share_cache_demo | Multiplexación de la secuencia común de la secuencia | |
| Qwen1_5/share_cache_demo | Multiplexación de la secuencia común de la secuencia | |
| Encriptación de modelos | Qwen/share_cache_demo | Encriptación de modelos |
| Qwen1_5/share_cache_demo | Encriptación de modelos |
Consulte las preguntas frecuentes y respuestas de LLM-TPU


