LLM TPU
1.0.0

이 프로젝트는 주로 LLM을 계산하기위한 다양한 오픈 소스生成式AI模型의 배포를 인식합니다. 이 모델은 TPU-MLIR 컴파일러를 통해 Bmodel로 변환되고 C ++ 코드를 사용하여 PCIE 환경 또는 SOC 환경에 배포됩니다. Zhihu에 대한 설명을 썼고 ChatGLM2-6B 예로 들어 소스 코드 : ChatGLM2 프로세스 분석 및 TPU-MLIR 배포를 이해할 수 있도록했습니다.
배포 된 모델은 다음과 같습니다 (알파벳 순서로 배열) :
| 모델 | int4 | int8 | FP16/BF16 | 포옹 페이스 링크 |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | 링크 | ||
| chatglm3-6b | ✅ | ✅ | ✅ | 링크 |
| chatglm4-9b | ✅ | ✅ | ✅ | 링크 |
| Codefuse-7b | ✅ | ✅ | 링크 | |
| Deepseek-6.7b | ✅ | ✅ | 링크 | |
| 팔콘 -40b | ✅ | ✅ | 링크 | |
| PHI-3-MINI-4K | ✅ | ✅ | ✅ | 링크 |
| Qwen-7b | ✅ | ✅ | ✅ | 링크 |
| Qwen-14b | ✅ | ✅ | ✅ | 링크 |
| Qwen-72b | ✅ | 링크 | ||
| Qwen1.5-0.5b | ✅ | ✅ | ✅ | 링크 |
| Qwen1.5-1.8b | ✅ | ✅ | ✅ | 링크 |
| Qwen1.5-7b | ✅ | ✅ | ✅ | 링크 |
| QWEN2-7B | ✅ | ✅ | ✅ | 링크 |
| Qwen2.5-7b | ✅ | ✅ | ✅ | 링크 |
| llama2-7b | ✅ | ✅ | ✅ | 링크 |
| llama2-13b | ✅ | ✅ | ✅ | 링크 |
| llama3-8b | ✅ | ✅ | ✅ | 링크 |
| llama3.1-8b | ✅ | ✅ | ✅ | 링크 |
| LWM-TEXT-Chat | ✅ | ✅ | ✅ | 링크 |
| Minicpm3-4b | ✅ | ✅ | 링크 | |
| Mistral-7B- 비축 | ✅ | ✅ | 링크 | |
| 안정적인 확산 | ✅ | 링크 | ||
| 안정적인 확산 XL | ✅ | 링크 | ||
| 마법사 -15b | ✅ | 링크 | ||
| Yi-6B-Chat | ✅ | ✅ | 링크 | |
| Yi-34B-Chat | ✅ | ✅ | 링크 | |
| Qwen-VL-Chat | ✅ | ✅ | 링크 | |
| QWEN2-VL-Chat | ✅ | ✅ | 링크 | |
| Internvl2-4b | ✅ | ✅ | 링크 | |
| Internvl2-2B | ✅ | ✅ | 링크 | |
| Minicpm-V-2_6 | ✅ | ✅ | 링크 | |
| llama3.2-vision-11b | ✅ | ✅ | ✅ | 링크 |
변환 세부 사항 및 소스 코드를 알고 싶다면이 프로젝트의 모델 하위 디렉토리로 이동하여 다양한 모델의 배포 세부 사항을 볼 수 있습니다.
칩에 관심이 있으시면 공식 웹 사이트 Sophgo를 통해 저희에게 연락 할 수도 있습니다.
LLM-TPU 프로젝트를 복제하고 run.sh 스크립트를 실행하십시오
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7b자세한 내용은 빠른 시작을 참조하십시오
실행 후 효과는 다음 그림에 표시됩니다.
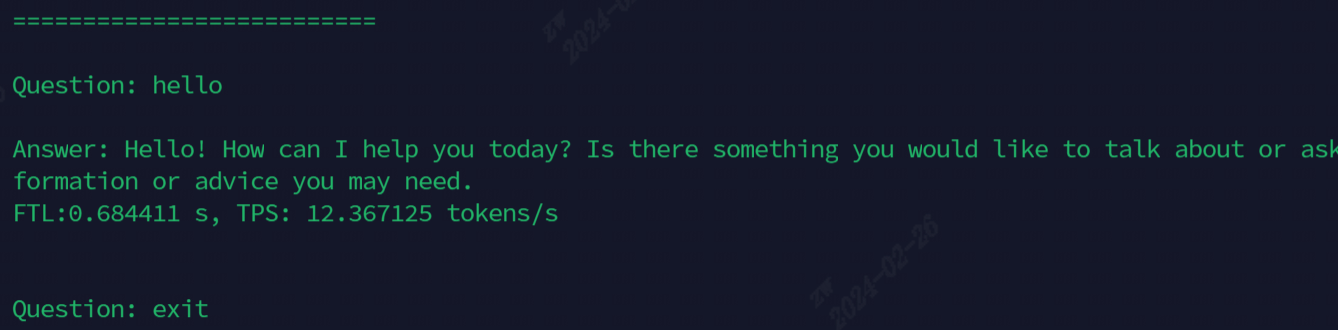
현재 데모에 사용되는 모델, 모든 명령은 다음 표에 나와 있습니다.
| 모델 | 사회 | PCIE |
|---|---|---|
| chatglm3-6b | ./run.sh-모델 Chatglm3-6b -arch soc | ./run.sh-모델 chatglm3-6b -arch pcie |
| llama2-7b | ./run.sh-- 모델 llama2-7b-아치 Soc | ./run.sh-모델 llama2-7b-아치 pcie |
| llama3-7b | ./run.sh-모델 llama3-7b -arch soc | ./run.sh-모델 llama3-7b-아치 pcie |
| Qwen-7b | ./run.sh-모델 Qwen-7b -arch Soc | ./run.sh-모델 Qwen-7b-Arch Pcie |
| Qwen1.5-1.8b | ./run.sh-모델 Qwen1.5-1.8b-아치 Soc | ./run.sh-모델 qwen1.5-1.8b-아치 pcie |
| Qwen2.5-7b | ./run.sh-모델 qwen2.5-7b -arch pcie | |
| LWM-TEXT-Chat | ./run.sh-모델 LWM-TEXT-Chat -arch Soc | ./run.sh-모델 LWM-TEXT-CHAT -ARCH PCIE |
| 마법사 -15b | ./run.sh-- 모들 마법사-모더-15B -arch soc | ./run.sh-- 모드 마법사 -15B-아치 PCIE |
| Internvl2-4b | ./run.sh-모델 인턴 vl2-4b -arch soc | ./run.sh-모델 인턴 vl2-4b -arch pcie |
| Minicpm-V-2_6 | ./run.sh-- 모드 minicv2_6 -arch soc | ./run.sh -모드 minicmv2_6 -arch pcie |
고급 기능 설명 :
| 기능 | 목차 | 기능 설명 |
|---|---|---|
| 멀티 코어 | chatglm3/parallel_demo | chatglm3 2 코어 지원 |
| llama2/demo_parallel | llama2 4/6/8 코어를 지원합니다 | |
| Qwen/demo_parallel | Qwen 4/6/8 코어 지원 | |
| qwen1_5/demo_parallel | Qwen1_5 4/6/8 코어를 지원합니다 | |
| 투기 샘플링 | Qwen/Jacobi_demo | LookaheadDecoding |
| QWEN1_5/SPECULATIVE_SALLE_DEMO | 투기 샘플링 | |
| 사전 재사용 | qwen/prompt_cache_demo | 일반적인 시퀀스 프리안 다중화 |
| qwen/share_cache_demo | 일반적인 시퀀스 프리안 다중화 | |
| qwen1_5/share_cache_demo | 일반적인 시퀀스 프리안 다중화 | |
| 모델 암호화 | qwen/share_cache_demo | 모델 암호화 |
| qwen1_5/share_cache_demo | 모델 암호화 |
LLM-TPU FAQ 및 답변을 참조하십시오


