LLM TPU
1.0.0

يدرك هذا المشروع نشر生成式AI模型المفتوحة المصدر المختلفة لحساب رقائق BM1684X ، وخاصة LLM. يتم تحويل النموذج إلى BModel من خلال برنامج التحويل البرمجي TPU-MLIR ونشره في بيئة PCIe أو بيئة SOC باستخدام رمز C ++. لقد كتبت شرحًا على Zhihu ، وأخذ ChatGLM2-6B كمثال ، حتى يتمكن الجميع من فهم الكود المصدري: تحليل عملية chatglm2 ونشر TPU-MLIR
النماذج المنشورة هي كما يلي (مرتبة بالترتيب الأبجدي):
| نموذج | int4 | int8 | FP16/BF16 | رابط Luggingface |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | وصلة | ||
| ChatGlm3-6b | ✅ | ✅ | ✅ | وصلة |
| ChatGlm4-9b | ✅ | ✅ | ✅ | وصلة |
| Codefuse-7b | ✅ | ✅ | وصلة | |
| Deepseek-6.7b | ✅ | ✅ | وصلة | |
| فالكون -40 ب | ✅ | ✅ | وصلة | |
| PHI-3-MINI-4K | ✅ | ✅ | ✅ | وصلة |
| Qwen-7b | ✅ | ✅ | ✅ | وصلة |
| Qwen-14b | ✅ | ✅ | ✅ | وصلة |
| Qwen-72b | ✅ | وصلة | ||
| Qwen1.5-0.5b | ✅ | ✅ | ✅ | وصلة |
| Qwen1.5-1.8b | ✅ | ✅ | ✅ | وصلة |
| Qwen1.5-7b | ✅ | ✅ | ✅ | وصلة |
| Qwen2-7b | ✅ | ✅ | ✅ | وصلة |
| Qwen2.5-7b | ✅ | ✅ | ✅ | وصلة |
| لاما 2-7 ب | ✅ | ✅ | ✅ | وصلة |
| Llama2-13b | ✅ | ✅ | ✅ | وصلة |
| Llama3-8b | ✅ | ✅ | ✅ | وصلة |
| llama3.1-8b | ✅ | ✅ | ✅ | وصلة |
| LWM-Text Chat | ✅ | ✅ | ✅ | وصلة |
| minicpm3-4b | ✅ | ✅ | وصلة | |
| MISTRAL-7B-instruct | ✅ | ✅ | وصلة | |
| انتشار مستقر | ✅ | وصلة | ||
| انتشار مستقر XL | ✅ | وصلة | ||
| WizardCoder-15B | ✅ | وصلة | ||
| yi-6b-chat | ✅ | ✅ | وصلة | |
| yi-34b-Chat | ✅ | ✅ | وصلة | |
| Qwen-VL-Chat | ✅ | ✅ | وصلة | |
| Qwen2-VL-Chat | ✅ | ✅ | وصلة | |
| internvl2-4b | ✅ | ✅ | وصلة | |
| internvl2-2b | ✅ | ✅ | وصلة | |
| minicpm-v-2_6 | ✅ | ✅ | وصلة | |
| llama3.2-vision-11b | ✅ | ✅ | ✅ | وصلة |
إذا كنت ترغب في معرفة تفاصيل التحويل والرمز المصدر ، فيمكنك الانتقال إلى النماذج الفرعية لهذا المشروع لعرض تفاصيل النشر للنماذج المختلفة.
إذا كنت مهتمًا بالرقائق الخاصة بنا ، فيمكنك أيضًا الاتصال بنا من خلال الموقع الرسمي Sophgo.
استنساخ مشروع LLM-TPU وتنفيذ البرنامج النصي Run.sh
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7bيرجى الرجوع إلى بدء التشغيل السريع للحصول على التفاصيل
يظهر التأثير بعد الجري في الشكل التالي
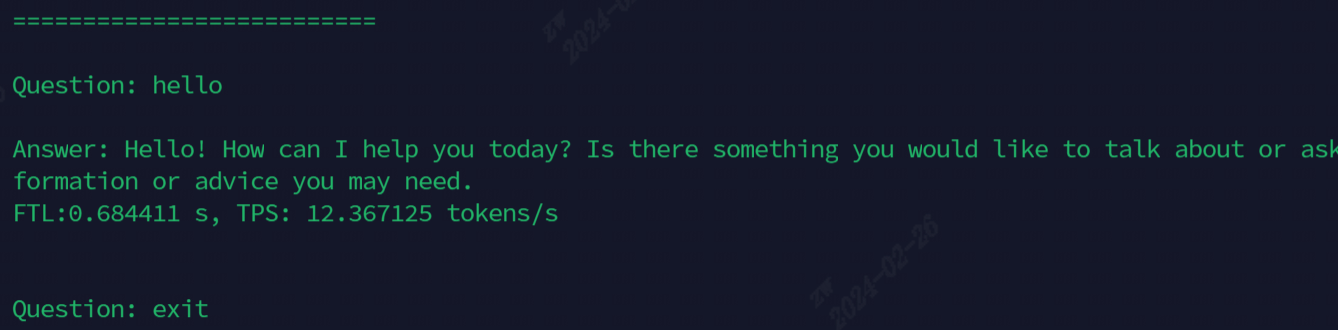
النماذج المستخدمة حاليًا للتظاهر ، يتم عرض جميع الأوامر في الجدول التالي
| نموذج | سوك | PCIE |
|---|---|---|
| ChatGlm3-6b | . | . |
| لاما 2-7 ب | ./run.sh-model llama2-7b-soc | . |
| لاما 3-7 ب | ./run.sh-model llama3-7b-Arch | . |
| Qwen-7b | . | . |
| Qwen1.5-1.8b | . | ./run.sh-model qwen1.5-1.8b-Arch PCIe |
| Qwen2.5-7b | . | |
| LWM-Text Chat | . | ./run.sh-model lwm-text-chat-arch pcie |
| WizardCoder-15B | . | . |
| internvl2-4b | ./run.sh-model internvl2-4b-arch | . |
| minicpm-v-2_6 | ./run.sh -minicv2_6 -آرك | ./run.sh -minicmv2_6 -Aarch PCIe |
وصف الوظيفة المتقدمة:
| وظيفة | جدول المحتويات | وصف الوظيفة |
|---|---|---|
| متعدد النواة | ChatGlm3/Parallel_demo | دعم chatglm3 2-core |
| llama2/demo_paralled | دعم Llama2 4/6/8 Core | |
| Qwen/Demo_paralled | دعم Qwen 4/6/8 النوى | |
| qwen1_5/demo_paralled | دعم QWEN1_5 4/6/8 النوى | |
| أخذ العينات المضاربة | Qwen/Jacobi_demo | lookaheaddecoding |
| QWEN1_5/CONSULATION_SAMPLE_DEMO | أخذ العينات المضاربة | |
| إعادة استخدام مسبق | qwen/prompr_cache_demo | تسلسل تسلسل مشترك premill |
| qwen/share_cache_demo | تسلسل تسلسل مشترك premill | |
| qwen1_5/share_cache_demo | تسلسل تسلسل مشترك premill | |
| تشفير النموذج | qwen/share_cache_demo | تشفير النموذج |
| qwen1_5/share_cache_demo | تشفير النموذج |
يرجى الرجوع إلى أسئلة وأجوبة LLM-TPU والإجابات


