LLM TPU
1.0.0

Proyek ini mewujudkan penyebaran berbagai生成式AI模型open source untuk menghitung chip BM1684X, terutama LLM. Model ini dikonversi menjadi bmodel melalui kompiler TPU-MLIR dan digunakan ke lingkungan PCIe atau lingkungan SOC menggunakan kode C ++. Saya menulis penjelasan tentang Zhihu, mengambil ChatGLM2-6B sebagai contoh, sehingga semua orang dapat memahami kode sumber: analisis proses chatglm2 dan penyebaran TPU-MLIR
Model yang digunakan adalah sebagai berikut (diatur dalam urutan abjad):
| Model | Int4 | Int8 | FP16/BF16 | Tautan Huggingface |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | LINK | ||
| Chatglm3-6b | ✅ | ✅ | ✅ | LINK |
| Chatglm4-9b | ✅ | ✅ | ✅ | LINK |
| Codefuse-7b | ✅ | ✅ | LINK | |
| Deepseek-6.7b | ✅ | ✅ | LINK | |
| Falcon-40b | ✅ | ✅ | LINK | |
| Phi-3-mini-4K | ✅ | ✅ | ✅ | LINK |
| Qwen-7b | ✅ | ✅ | ✅ | LINK |
| Qwen-14b | ✅ | ✅ | ✅ | LINK |
| Qwen-72b | ✅ | LINK | ||
| Qwen1.5-0.5b | ✅ | ✅ | ✅ | LINK |
| Qwen1.5-1.8b | ✅ | ✅ | ✅ | LINK |
| Qwen1.5-7b | ✅ | ✅ | ✅ | LINK |
| QWEN2-7B | ✅ | ✅ | ✅ | LINK |
| Qwen2.5-7b | ✅ | ✅ | ✅ | LINK |
| Llama2-7b | ✅ | ✅ | ✅ | LINK |
| Llama2-13b | ✅ | ✅ | ✅ | LINK |
| Llama3-8b | ✅ | ✅ | ✅ | LINK |
| Llama3.1-8b | ✅ | ✅ | ✅ | LINK |
| LWM-TEXT-CHAT | ✅ | ✅ | ✅ | LINK |
| Minicpm3-4b | ✅ | ✅ | LINK | |
| MISTRAL-7B-INSTRUCT | ✅ | ✅ | LINK | |
| Difusi stabil | ✅ | LINK | ||
| Difusi stabil XL | ✅ | LINK | ||
| WizardCoder-15b | ✅ | LINK | ||
| Yi-6b-chat | ✅ | ✅ | LINK | |
| Yi-34b-chat | ✅ | ✅ | LINK | |
| Qwen-vl-chat | ✅ | ✅ | LINK | |
| QWEN2-VL-CHAT | ✅ | ✅ | LINK | |
| Internvl2-4b | ✅ | ✅ | LINK | |
| Internvl2-2b | ✅ | ✅ | LINK | |
| Minicpm-v-2_6 | ✅ | ✅ | LINK | |
| Llama3.2-vision-11b | ✅ | ✅ | ✅ | LINK |
Jika Anda ingin mengetahui detail konversi dan kode sumber, Anda dapat pergi ke subdirektori model proyek ini untuk melihat detail penyebaran dari berbagai model.
Jika Anda tertarik dengan chip kami, Anda juga dapat menghubungi kami melalui situs web resmi Sophgo.
Klon proyek LLM-TPU dan jalankan skrip run.sh
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7bSilakan merujuk ke Mulai Cepat untuk detailnya
Efek setelah berjalan ditunjukkan pada gambar berikut
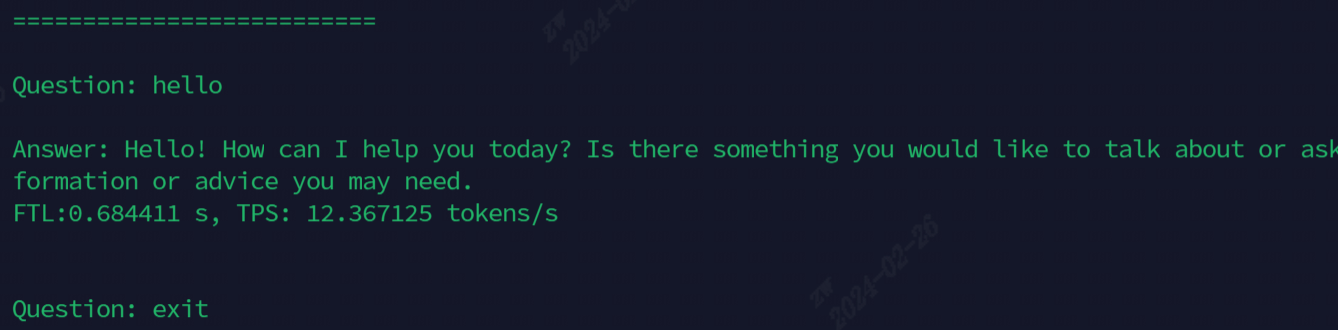
Model yang saat ini digunakan untuk demonstrasi, semua perintah ditampilkan di tabel berikut
| Model | Soc | PCIE |
|---|---|---|
| Chatglm3-6b | ./run.sh --codel chatglm3-6b --arch soc | ./run.sh-Model chatglm3-6b --ch pcie |
| Llama2-7b | ./run.sh-Model llama2-7b --ch Soc | ./run.sh-Model llama2-7b --ch pcie |
| Llama3-7b | ./run.sh-Model llama3-7b --ch Soc | ./run.sh-Model llama3-7b --ch pcie |
| Qwen-7b | ./run.sh-Model Qwen-7b --arch Soc | ./run.sh-Model Qwen-7b --ch pcie |
| Qwen1.5-1.8b | ./run.sh-Model Qwen1.5-1.8b --ch Soc | ./run.sh-Model Qwen1.5-1.8b --ch pcie |
| Qwen2.5-7b | ./run.sh-Model qwen2.5-7b --ch pcie | |
| LWM-TEXT-CHAT | ./run.sh--Model lwm-text-chat --ch Soc | ./run.sh --ding lwm-text-chat --ch pcie |
| WizardCoder-15b | ./run.sh --ding WizardCoder-15b --ch Soc | ./run.sh --ding WizardCoder-15b --ch pcie |
| Internvl2-4b | ./run.sh--Model Internvl2-4b --ch Soc | ./run.sh--Model Internvl2-4b --ch pcie |
| Minicpm-v-2_6 | ./run.sh -Model minicv2_6 --ch Soc | ./run.sh - -Model minicmv2_6 --ch pcie |
Deskripsi Fungsi Lanjutan:
| Fungsi | Daftar isi | Deskripsi fungsi |
|---|---|---|
| Multi-core | Chatglm3/parallel_demo | Dukung chatglm3 2-core |
| Llama2/demo_parallel | Dukungan LLAMA2 4/6/8 Core | |
| QWEN/DEMO_PARALLEL | Dukung Qwen 4/6/8 core | |
| Qwen1_5/demo_parallel | Dukung QWEN1_5 4/6/8 Core | |
| Pengambilan sampel spekulatif | Qwen/jacobi_demo | Lookaheaddecoding |
| Qwen1_5/speculative_sample_demo | Pengambilan sampel spekulatif | |
| Prefill Reuse | Qwen/prompt_cache_demo | Urutan Umum Prefill Multiplexing |
| Qwen/share_cache_demo | Urutan Umum Prefill Multiplexing | |
| Qwen1_5/share_cache_demo | Urutan Umum Prefill Multiplexing | |
| Enkripsi model | Qwen/share_cache_demo | Enkripsi model |
| Qwen1_5/share_cache_demo | Enkripsi model |
Silakan merujuk ke FAQ dan Jawaban LLM-TPU


