LLM TPU
1.0.0

Ce projet réalise le déploiement de divers生成式AI模型open source pour calculer les puces BM1684X, principalement LLM. Le modèle est converti en BModel via le compilateur TPU-MLIR et déployé dans un environnement PCIe ou un environnement SOC en utilisant le code C ++. J'ai écrit une explication sur Zhihu, en prenant ChatGLM2-6B à titre d'exemple, afin que tout le monde puisse comprendre le code source: analyse de processus ChatGLM2 et déploiement TPU-Mlir
Les modèles déployés sont les suivants (organisé par ordre alphabétique):
| Modèle | Int4 | Int8 | FP16 / BF16 | Lien de câlins |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | LIEN | ||
| Chatglm3-6b | ✅ | ✅ | ✅ | LIEN |
| Chatglm4-9b | ✅ | ✅ | ✅ | LIEN |
| Codefuse-7b | ✅ | ✅ | LIEN | |
| Deepseek-6.7b | ✅ | ✅ | LIEN | |
| Falcon-40b | ✅ | ✅ | LIEN | |
| PHI-3-MINI-4K | ✅ | ✅ | ✅ | LIEN |
| Qwen-7b | ✅ | ✅ | ✅ | LIEN |
| Qwen-14b | ✅ | ✅ | ✅ | LIEN |
| Qwen-72b | ✅ | LIEN | ||
| Qwen1.5-0.5b | ✅ | ✅ | ✅ | LIEN |
| Qwen1.5-1.8b | ✅ | ✅ | ✅ | LIEN |
| Qwen1.5-7b | ✅ | ✅ | ✅ | LIEN |
| Qwen2-7b | ✅ | ✅ | ✅ | LIEN |
| Qwen2.5-7b | ✅ | ✅ | ✅ | LIEN |
| Llama2-7b | ✅ | ✅ | ✅ | LIEN |
| Llama2-13b | ✅ | ✅ | ✅ | LIEN |
| Llama3-8b | ✅ | ✅ | ✅ | LIEN |
| Lama3.1-8b | ✅ | ✅ | ✅ | LIEN |
| Chat lwm-text | ✅ | ✅ | ✅ | LIEN |
| MINICPM3-4B | ✅ | ✅ | LIEN | |
| Mistral-7B-Istruct | ✅ | ✅ | LIEN | |
| Diffusion stable | ✅ | LIEN | ||
| Diffusion stable xl | ✅ | LIEN | ||
| WizardCoder-15b | ✅ | LIEN | ||
| YI-6B-CHAT | ✅ | ✅ | LIEN | |
| YI-34B-CHAT | ✅ | ✅ | LIEN | |
| Qwen-vl-chat | ✅ | ✅ | LIEN | |
| Qwen2-vl-chat | ✅ | ✅ | LIEN | |
| Intervl2-4b | ✅ | ✅ | LIEN | |
| Intervl2-2b | ✅ | ✅ | LIEN | |
| Minicpm-v-2_6 | ✅ | ✅ | LIEN | |
| LLAMA3.2-VISION-11B | ✅ | ✅ | ✅ | LIEN |
Si vous souhaitez connaître les détails de la conversion et le code source, vous pouvez accéder au sous-répertoire des modèles de ce projet pour afficher les détails de déploiement de divers modèles.
Si vous êtes intéressé par nos puces, vous pouvez également nous contacter via le site officiel Sophgo.
Clone le projet LLM-TPU et exécutez le script run.sh
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7bVeuillez vous référer au démarrage rapide pour plus de détails
L'effet après l'exécution est illustré dans la figure suivante
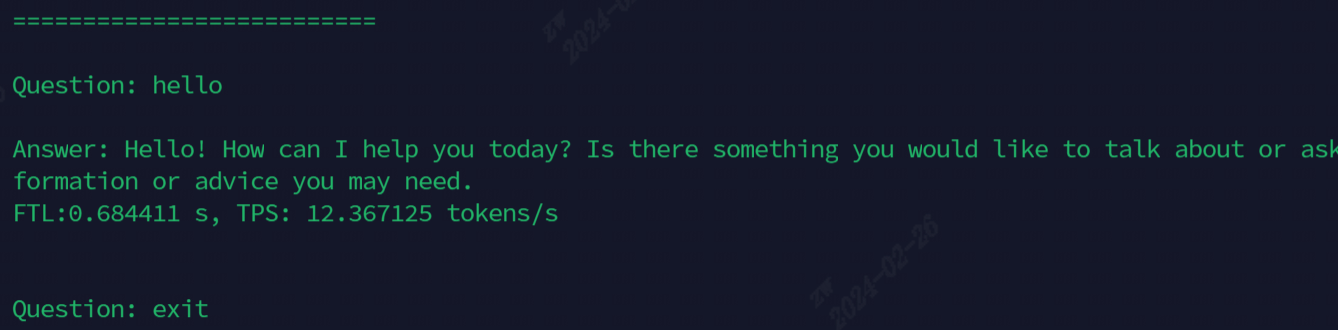
Les modèles actuellement utilisés pour la démonstration, toutes les commandes sont présentées dans le tableau suivant
| Modèle | Soc | Pie |
|---|---|---|
| Chatglm3-6b | ./run.sh --model chatglm3-6b - ararch soc | ./run.sh --model chatglm3-6b - arch PCIe |
| Llama2-7b | ./run.sh --model llama2-7b - ararch soc | ./run.sh --model llama2-7b - arch PCIe |
| LLAMA3-7B | ./run.sh --model llama3-7b - ararch soc | ./run.sh --model llama3-7b - arch PCIe |
| Qwen-7b | ./run.sh --model qwen-7b - ararch soc | ./run.sh --model qwen-7b - arch PCIe |
| Qwen1.5-1.8b | ./run.sh --model qwen1.5-1.8b - ararch soc | ./run.sh --model qwen1.5-1.8b - arch PCIe |
| Qwen2.5-7b | ./run.sh --model qwen2.5-7b - arch PCIe | |
| Chat lwm-text | ./run.sh --model lwm-text-chat --arch soc | ./run.sh --model lwm-text-chat - archi |
| WizardCoder-15b | ./run.sh --model wizardcoder-15b - ararch soc | ./run.sh --model wizardcoder-15b - Arch PCIe |
| Intervl2-4b | ./run.sh --model intervl2-4b - ararch soc | ./run.sh --model Internvl2-4b - Arch PCIe |
| Minicpm-v-2_6 | ./run.sh --model MINICV2_6 - ARCH SOC | ./run.sh --model MINICMV2_6 - ARCH PCIE |
Description de la fonction avancée:
| Fonction | Table des matières | Description de la fonction |
|---|---|---|
| Multi-cœurs | ChatGlm3 / parallel_demo | Prise en charge de ChatGlm3 2-Core |
| LLAMA2 / Demo_Parallel | Support Llama2 4/6/8 Core | |
| Qwen / Demo_Parallel | Support Qwen 4/6/8 CORE | |
| Qwen1_5 / Demo_Parallel | Support Qwen1_5 4/6/8 CORE | |
| Échantillonnage spéculatif | Qwen / jacobi_demo | Lookaheaddecoding |
| Qwen1_5 / spéculative_sample_demo | Échantillonnage spéculatif | |
| Pré-rempli | Qwen / prompt_cache_demo | Multiplexage de préfacturation de séquence commune |
| Qwen / share_cache_demo | Multiplexage de préfacturation de séquence commune | |
| Qwen1_5 / share_cache_demo | Multiplexage de préfacturation de séquence commune | |
| Cryptage modèle | Qwen / share_cache_demo | Cryptage modèle |
| Qwen1_5 / share_cache_demo | Cryptage modèle |
Veuillez vous référer aux FAQ et réponses LLM-TPU


