LLM TPU
1.0.0

このプロジェクトは、主にLLMを計算するためのさまざまなオープンソース生成式AI模型の展開を実現します。このモデルは、TPU-MLIRコンパイラを介してBModelに変換され、C ++コードを使用してPCIE環境またはSOC環境に展開されます。 Zhihuについて説明を書きましたChatGLM2-6Bを例として取りました。
展開されたモデルは次のとおりです(アルファベット順に配置されています):
| モデル | INT4 | INT8 | FP16/BF16 | Huggingfaceリンク |
|---|---|---|---|---|
| Baichuan2-7b | ✅ | リンク | ||
| chatglm3-6b | ✅ | ✅ | ✅ | リンク |
| chatglm4-9b | ✅ | ✅ | ✅ | リンク |
| codefuse-7b | ✅ | ✅ | リンク | |
| deepseek-6.7b | ✅ | ✅ | リンク | |
| ファルコン-40b | ✅ | ✅ | リンク | |
| PHI-3-MINI-4K | ✅ | ✅ | ✅ | リンク |
| Qwen-7b | ✅ | ✅ | ✅ | リンク |
| QWEN-14B | ✅ | ✅ | ✅ | リンク |
| Qwen-72b | ✅ | リンク | ||
| QWEN1.5-0.5B | ✅ | ✅ | ✅ | リンク |
| QWEN1.5-1.8B | ✅ | ✅ | ✅ | リンク |
| QWEN1.5-7B | ✅ | ✅ | ✅ | リンク |
| QWEN2-7B | ✅ | ✅ | ✅ | リンク |
| QWEN2.5-7B | ✅ | ✅ | ✅ | リンク |
| llama2-7b | ✅ | ✅ | ✅ | リンク |
| llama2-13b | ✅ | ✅ | ✅ | リンク |
| llama3-8b | ✅ | ✅ | ✅ | リンク |
| llama3.1-8b | ✅ | ✅ | ✅ | リンク |
| lwm-text-chat | ✅ | ✅ | ✅ | リンク |
| MINICPM3-4B | ✅ | ✅ | リンク | |
| Mistral-7b-instruct | ✅ | ✅ | リンク | |
| 安定した拡散 | ✅ | リンク | ||
| 安定した拡散XL | ✅ | リンク | ||
| wizardcoder-15b | ✅ | リンク | ||
| yi-6b-chat | ✅ | ✅ | リンク | |
| yi-34b-chat | ✅ | ✅ | リンク | |
| qwen-vl-chat | ✅ | ✅ | リンク | |
| qwen2-vl-chat | ✅ | ✅ | リンク | |
| internvl2-4b | ✅ | ✅ | リンク | |
| internvl2-2b | ✅ | ✅ | リンク | |
| MINICPM-V-2_6 | ✅ | ✅ | リンク | |
| llama3.2-vision-11b | ✅ | ✅ | ✅ | リンク |
コンバージョンの詳細とソースコードを知りたい場合は、このプロジェクトのモデルサブディレクトリにアクセスして、さまざまなモデルの展開の詳細を表示できます。
チップに興味がある場合は、公式WebサイトのSophgoを通じてお問い合わせください。
LLM-TPUプロジェクトをクローンし、run.shスクリプトを実行します
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model llama2-7b詳細については、クイックスタートを参照してください
実行後の効果を次の図に示します
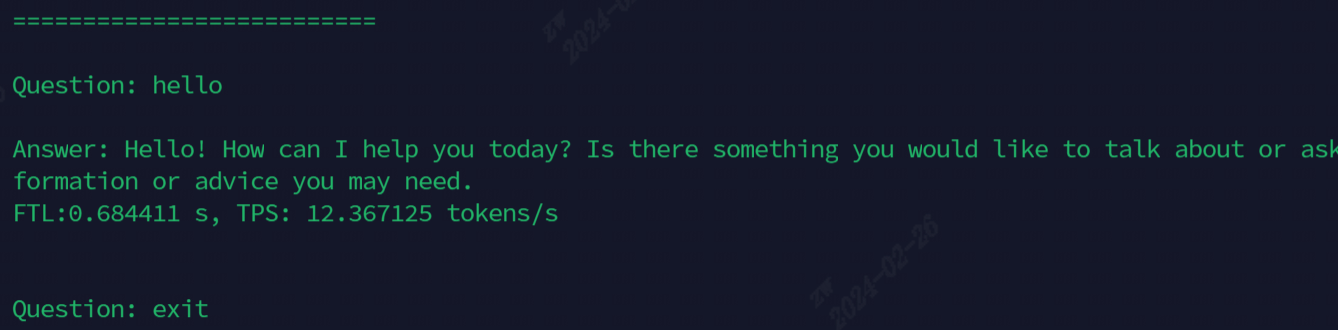
現在デモンストレーションに使用されているモデル、すべてのコマンドを次の表に示します
| モデル | Soc | PCIE |
|---|---|---|
| chatglm3-6b | ./run.sh - モデルchatglm3-6b -arch soc | ./run.sh - モデルchatglm3-6b -arch pcie |
| llama2-7b | ./run.sh - モデルllama2-7b -arch soc | ./run.sh - モデルllama2-7b -arch pcie |
| llama3-7b | ./run.sh - モデルllama3-7b -arch soc | ./run.sh - モデルllama3-7b -arch pcie |
| Qwen-7b | ./run.sh - モデルqwen-7b -arch soc | ./run.sh - モデルqwen-7b -arch pcie |
| QWEN1.5-1.8B | ./run.sh - モデルqwen1.5-1.8b -arch soc | ./run.sh - モデルqwen1.5-1.8b -arch pcie |
| QWEN2.5-7B | ./run.sh - モデルqwen2.5-7b -arch pcie | |
| lwm-text-chat | ./run.sh - model lwm-text-chat-arch soc | ./run.sh - model lwm-text-chat-arch pcie |
| wizardcoder-15b | ./run.sh - モデルwizardcoder-15b -arch soc | ./run.sh - model wizardcoder-15b -arch pcie |
| internvl2-4b | ./run.sh - モデルinternvl2-4b -arch soc | ./run.sh - モデルinternvl2-4b -arch pcie |
| MINICPM-V-2_6 | ./run.sh - モデルminicv2_6 -arch soc | ./run.sh - model minicmv2_6 -arch pcie |
高度な関数説明:
| 関数 | 目次 | 関数の説明 |
|---|---|---|
| マルチコア | chatglm3/parallel_demo | Chatglm3 2コアをサポートします |
| llama2/demo_parallel | サポートllama2 4/6/8コア | |
| qwen/demo_parallel | Qwen 4/6/8コアをサポートします | |
| qwen1_5/demo_parallel | サポートQWEN1_5 4/6/8コア | |
| 投機的サンプリング | qwen/jacobi_demo | lookaheaddecoding |
| qwen1_5/quiculative_sample_demo | 投機的サンプリング | |
| Prefillの再利用 | qwen/prompt_cache_demo | 一般的なシーケンスPrefillマルチプレックス |
| qwen/share_cache_demo | 一般的なシーケンスPrefillマルチプレックス | |
| qwen1_5/share_cache_demo | 一般的なシーケンスPrefillマルチプレックス | |
| モデル暗号化 | qwen/share_cache_demo | モデル暗号化 |
| qwen1_5/share_cache_demo | モデル暗号化 |
LLM-TPUのFAQと回答を参照してください


