VisualNews Repository
1.0.0
Fuxiao Liu,Yinghan Wang,Tianlu Wang,Vicente Ordonez(EMNLP 2021)
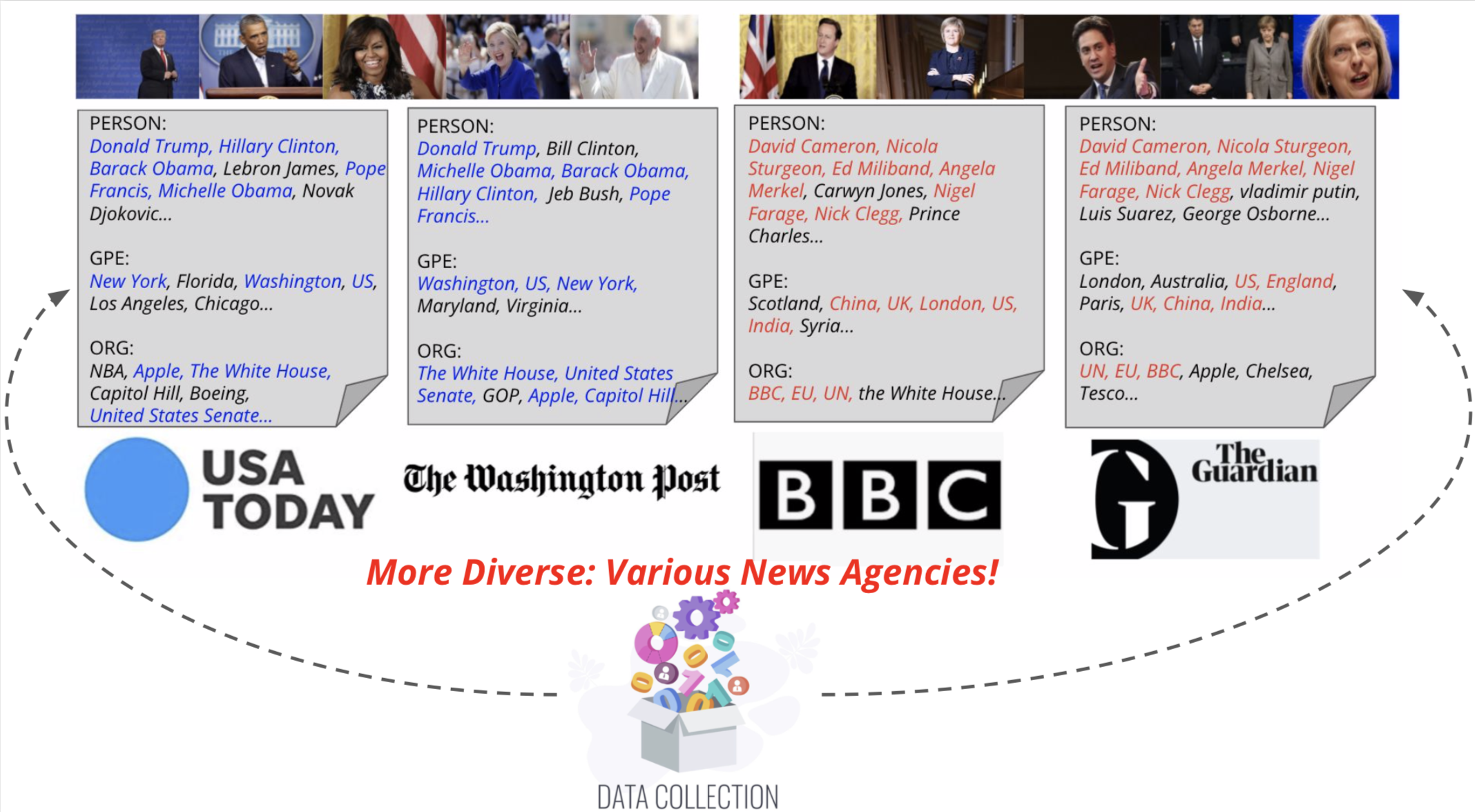
我們提出了視覺新聞字幕儀,這是一種實體感知的新聞圖像字幕任務的模型。我們還介紹了視覺新聞,這是一個大規模的基準,包括超過一百萬個新聞圖像以及相關的新聞文章,圖像標題,作者信息和其他元數據。與標準圖像字幕任務不同,新聞圖像描繪了人們,位置和事件至關重要的情況。我們提出的方法可以有效地結合視覺和文本功能,以生成字幕以及更豐富的信息,例如事件和實體。更具體地說,是基於變壓器體系結構的,我們的模型進一步配備了新型的多模式特徵融合技術和注意力機制,這些功能和注意力機制旨在更準確地生成命名實體。我們的方法利用了比競爭方法更少的參數,同時實現了預測結果稍好。我們更大,更多樣化的視覺新聞數據集進一步突出了標題為新聞圖像的剩餘挑戰。
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
我們模型的代碼在./model中。
CUDA_VISIBLE_DEVICES=0 python main.py
如有任何疑問,請發送電子郵件至[email protected] 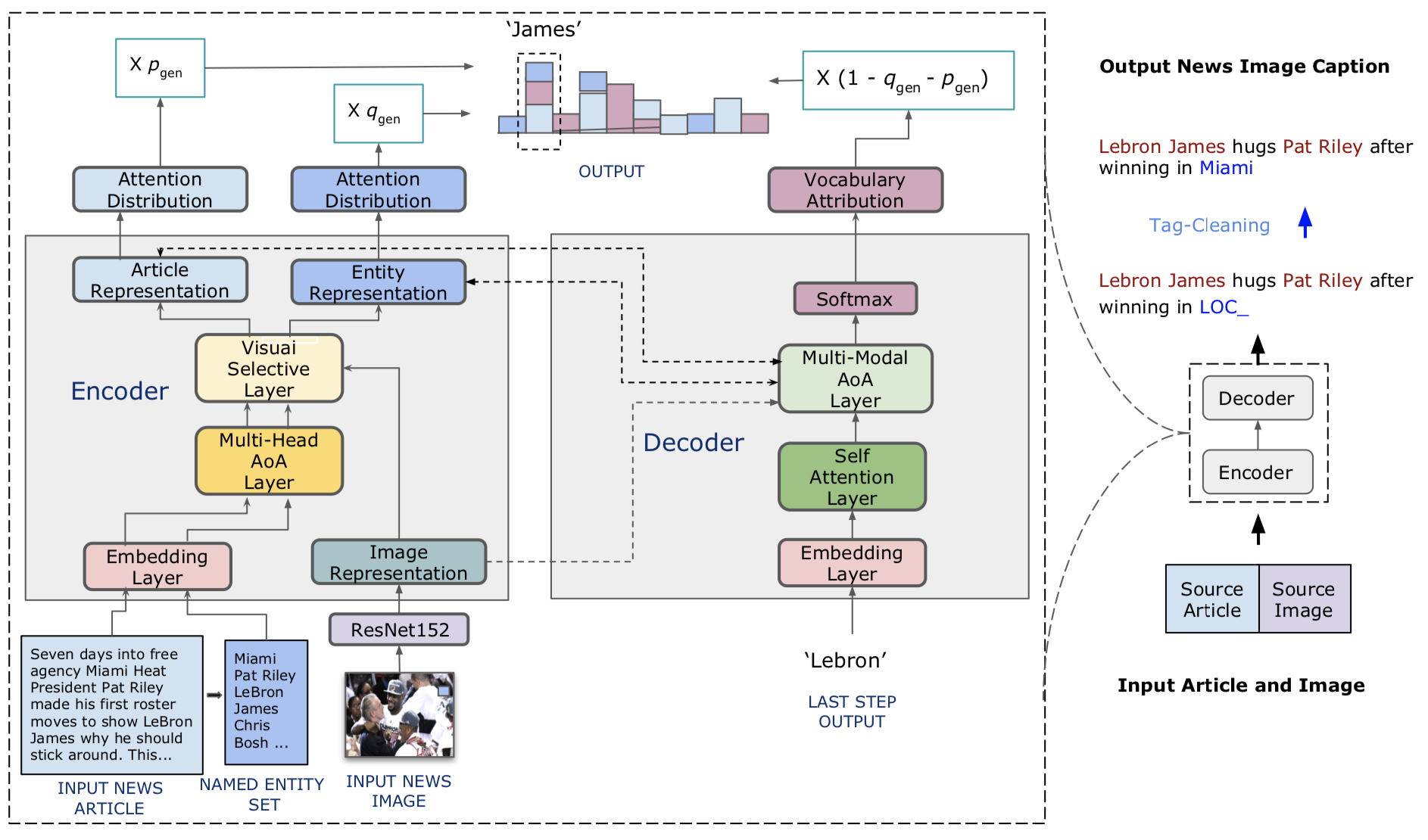
如果您發現我們的論文/代碼有用,請考慮引用:


