VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
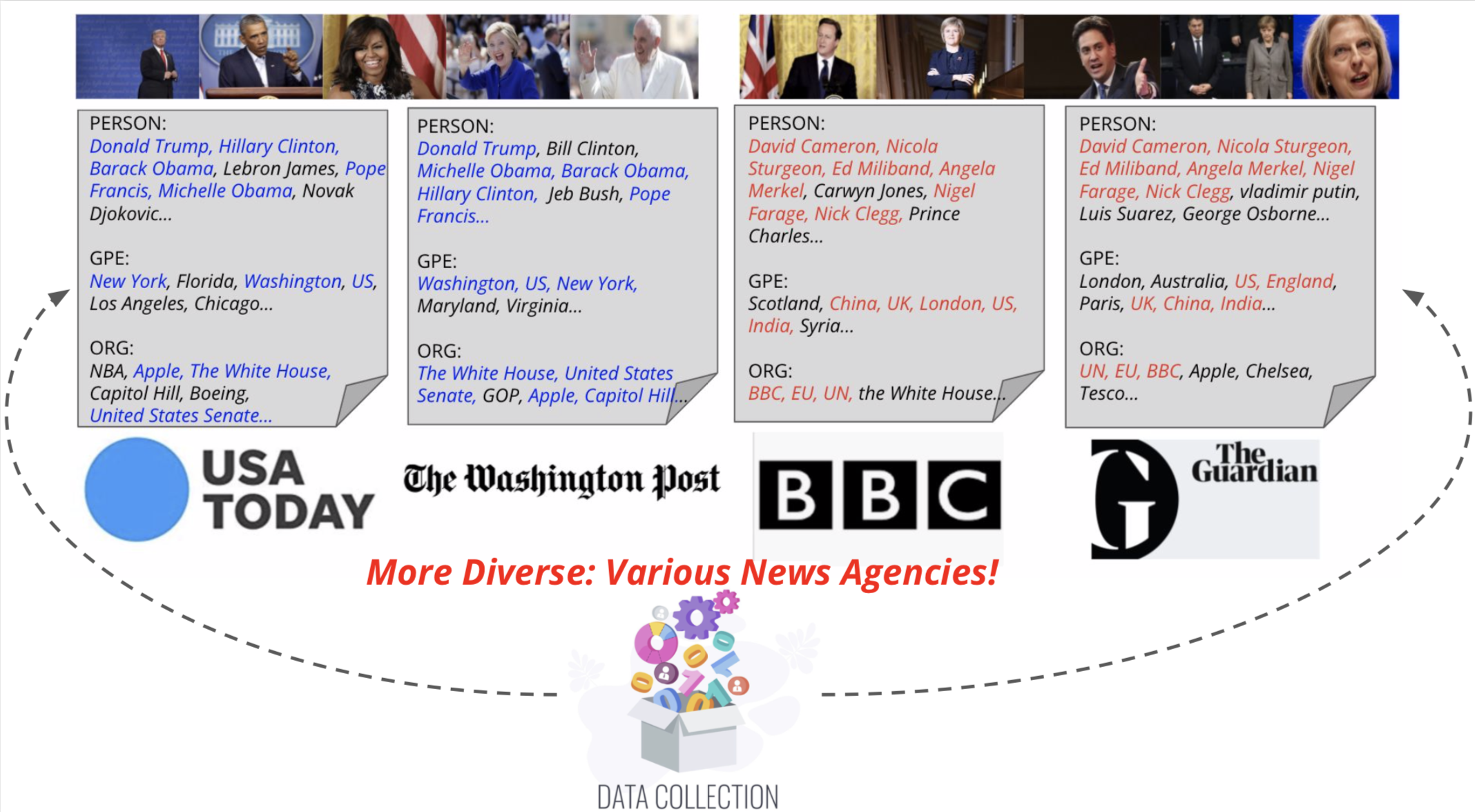
Proponemos Visual News Crimtioner, un modelo consciente de la entidad para la tarea de subtitulación de imágenes de noticias. También presentamos noticias visuales, un punto de referencia a gran escala que consta de más de un millón de imágenes de noticias junto con artículos de noticias asociados, subtítulos de imágenes, información del autor y otros metadatos. A diferencia de la tarea de subtítulos de imágenes estándar, las imágenes de noticias representan situaciones en las que las personas, las ubicaciones y los eventos son de suma importancia. Nuestro método propuesto puede combinar efectivamente las características visuales y textuales para generar subtítulos con información más rica, como eventos y entidades. Más específicamente, basado en la arquitectura del transformador, nuestro modelo está más equipado con nuevas técnicas de fusión de características multimodales y mecanismos de atención, que están diseñados para generar entidades nombradas con mayor precisión. Nuestro método utiliza muchos menos parámetros al tiempo que logra resultados de predicción ligeramente mejores que los métodos competitivos. Nuestro conjunto de datos de noticias visuales más grandes y más diversos resalta aún más los desafíos restantes en el subtítulos de las imágenes de las noticias.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
El código de nuestro modelo está en ./model.
CUDA_VISIBLE_DEVICES=0 python main.py
Si tiene alguna pregunta, envíe un correo electrónico: [email protected] 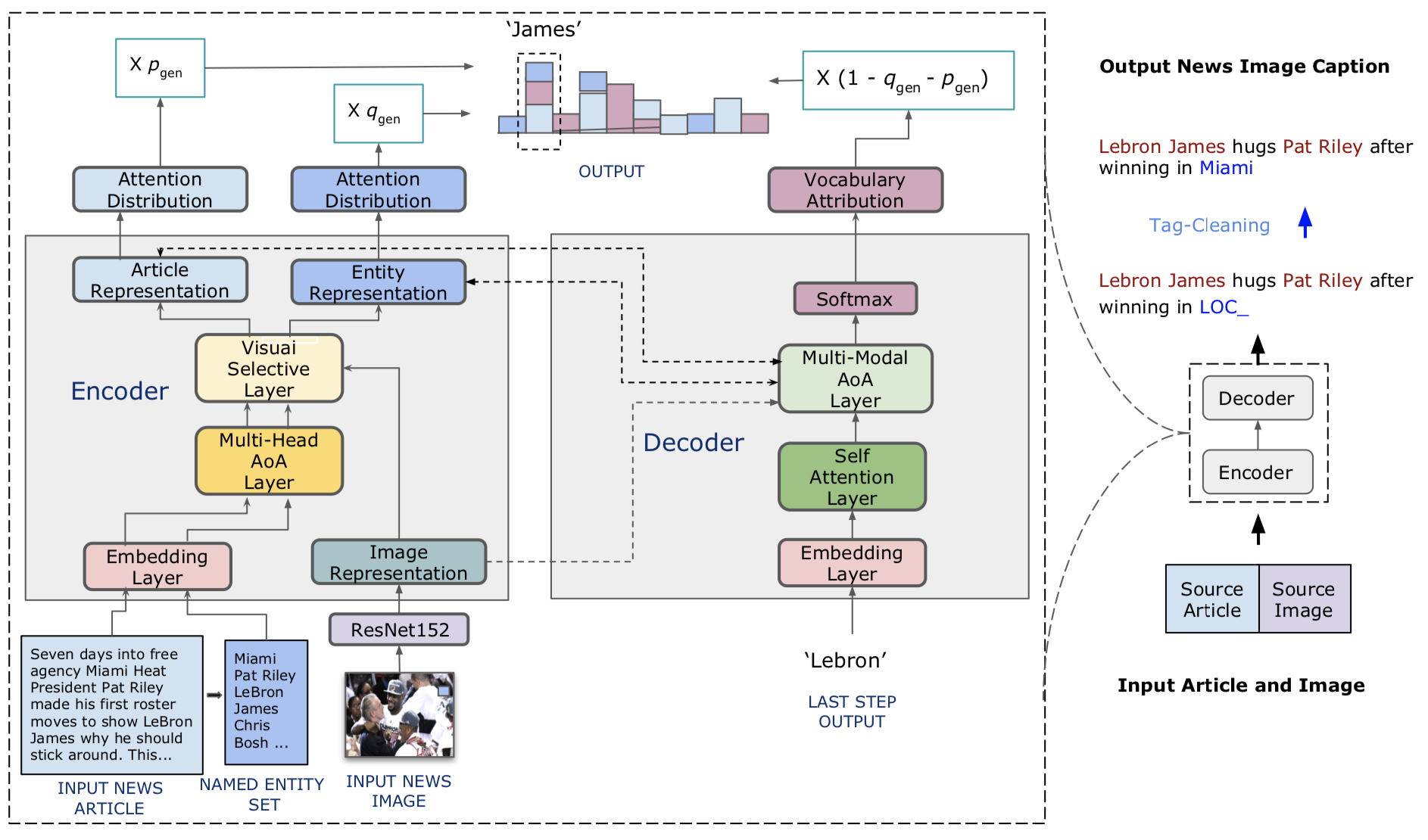
Si encuentra útil nuestro documento/código, considere citar:


