VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
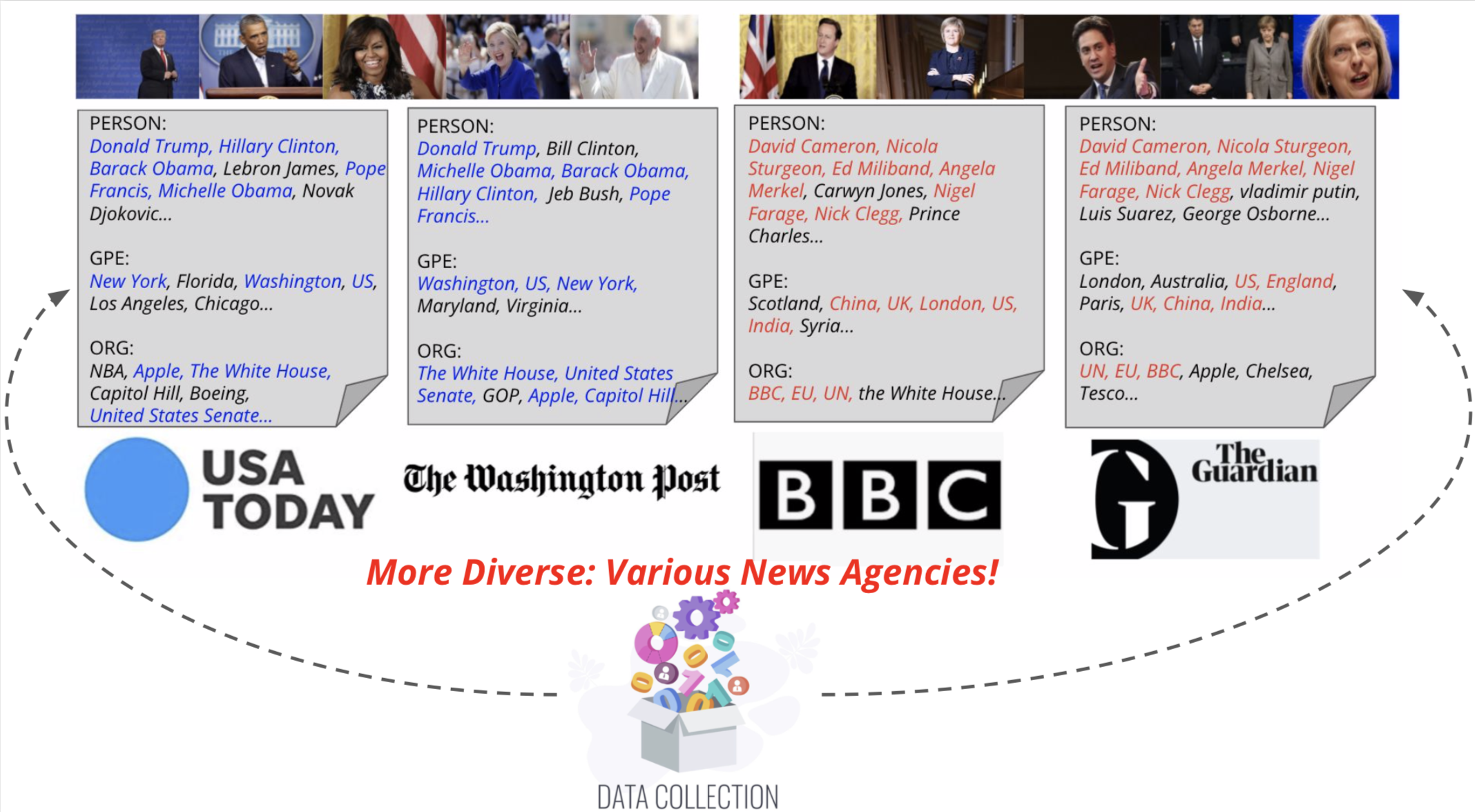
Kami mengusulkan captioner berita visual, model yang sadar entitas untuk tugas captioning gambar berita. Kami juga memperkenalkan Visual News, sebuah tolok ukur skala besar yang terdiri dari lebih dari satu juta gambar berita bersama dengan artikel berita terkait, keterangan gambar, informasi penulis, dan metadata lainnya. Berbeda dengan tugas captioning gambar standar, gambar berita menggambarkan situasi di mana orang, lokasi, dan peristiwa sangat penting. Metode yang kami usulkan dapat secara efektif menggabungkan fitur visual dan tekstual untuk menghasilkan teks dengan informasi yang lebih kaya seperti peristiwa dan entitas. Lebih khusus lagi, dibangun di atas arsitektur transformator, model kami selanjutnya dilengkapi dengan teknik fusi fitur multi-modal baru dan mekanisme perhatian, yang dirancang untuk menghasilkan entitas bernama lebih akurat. Metode kami menggunakan parameter yang jauh lebih sedikit sambil mencapai hasil prediksi yang sedikit lebih baik daripada metode yang bersaing. Dataset berita visual kami yang lebih besar dan lebih beragam menyoroti tantangan yang tersisa dalam menulis gambar berita.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
Kode model kami ada di ./model.
CUDA_VISIBLE_DEVICES=0 python main.py
Jika Anda memiliki pertanyaan, silakan email: [email protected] 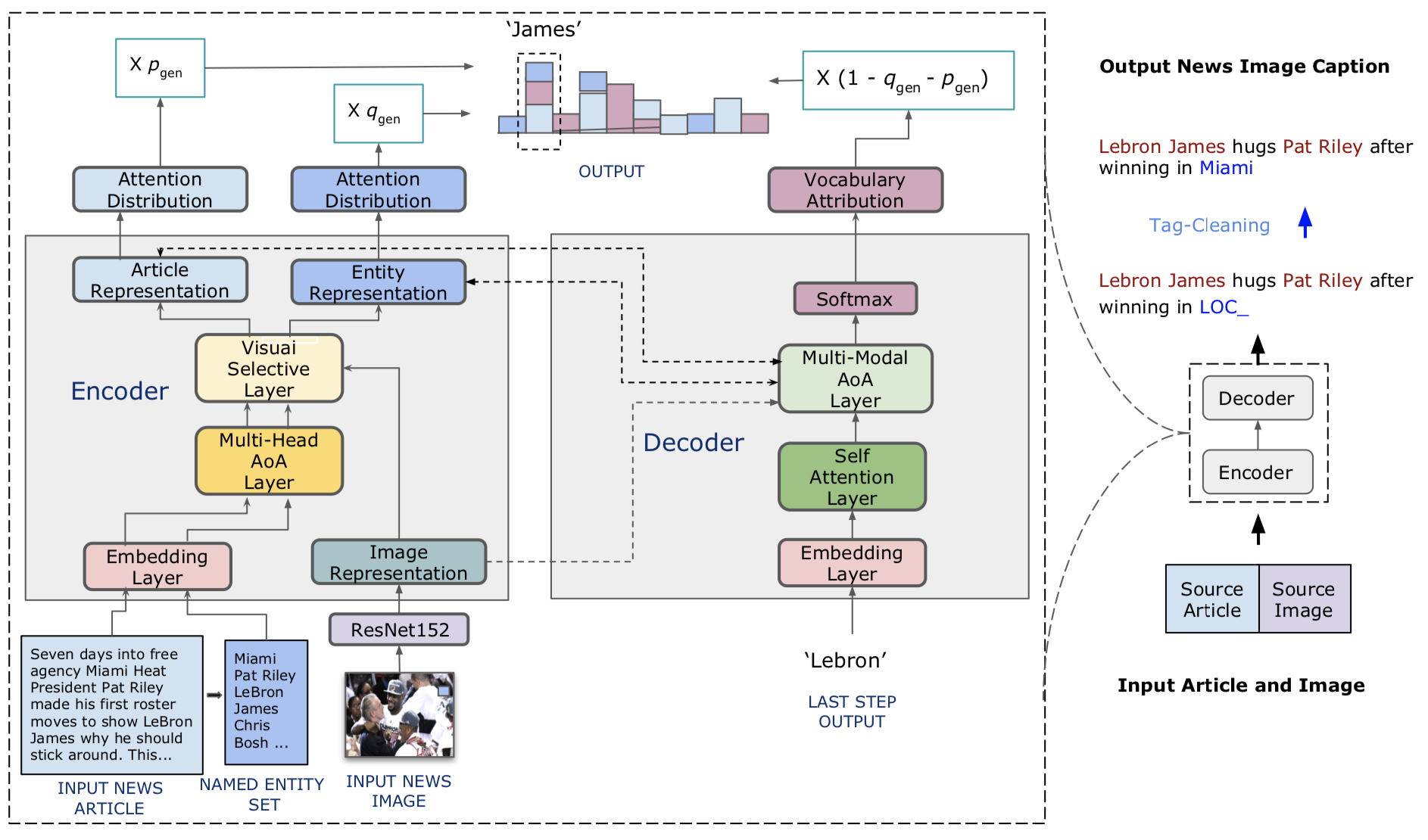
Jika Anda menemukan kertas/kode kami bermanfaat, harap pertimbangkan mengutip:


