VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
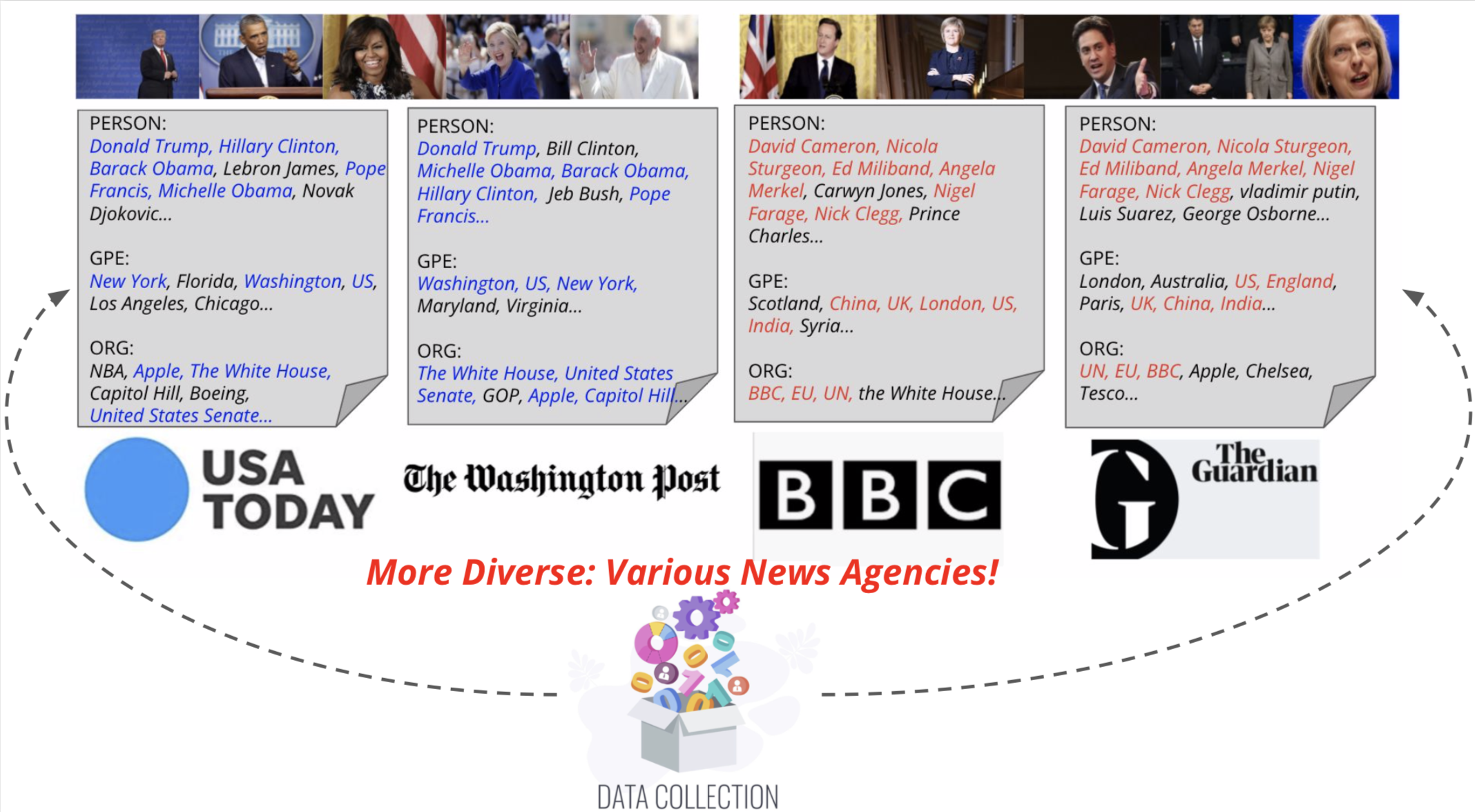
Nous proposons Visual News Le Sweetaire, un modèle conscient de l'entité pour la tâche du sous-titrage de l'image. Nous présentons également Visual News, une référence à grande échelle composée de plus d'un million d'images d'actualités ainsi que des articles de presse associés, des légendes d'image, des informations sur les auteurs et d'autres métadonnées. Contrairement à la tâche de sous-titrage d'image standard, les images d'actualités décrivent des situations où les personnes, les emplacements et les événements sont d'une importance capitale. Notre méthode proposée peut combiner efficacement les fonctionnalités visuelles et textuelles pour générer des légendes avec des informations plus riches telles que les événements et les entités. Plus précisément, construit sur l'architecture du transformateur, notre modèle est en outre équipé de nouvelles techniques de fusion de caractéristiques multimodales et des mécanismes d'attention, qui sont conçus pour générer plus précisément entités nommées. Notre méthode utilise beaucoup moins de paramètres tout en obtenant des résultats de prédiction légèrement meilleurs que les méthodes concurrentes. Notre ensemble de données visuelles plus vastes et plus diversifié met en évidence les défis restants dans les images d'information de sous-titrage.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
Le code de notre modèle est dans ./Model.
CUDA_VISIBLE_DEVICES=0 python main.py
Si vous avez des questions, veuillez envoyer un courriel: [email protected] 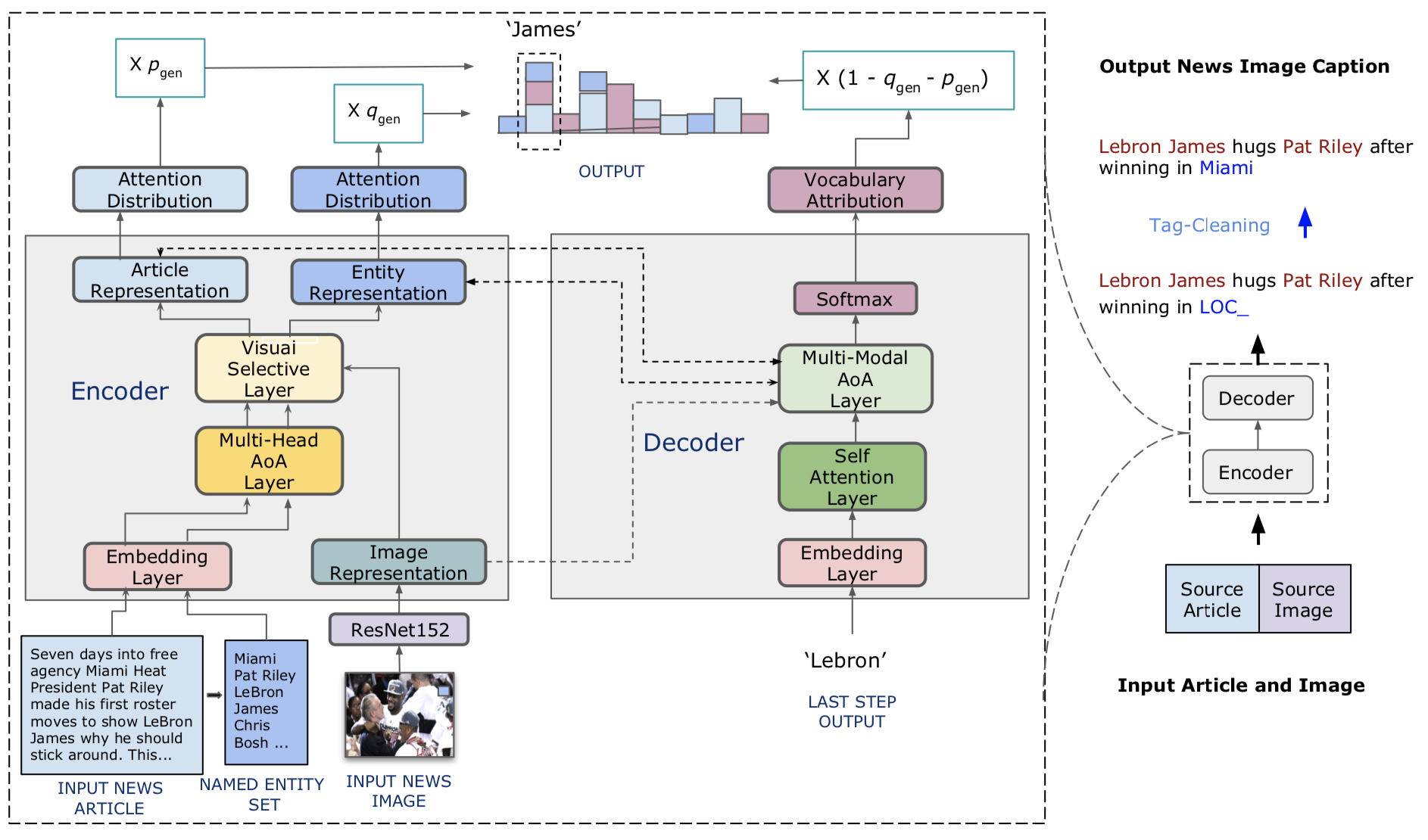
Si vous trouvez notre papier / code utile, veuillez envisager de citer:


