VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Visente Ordonez (EMNLP 2021)
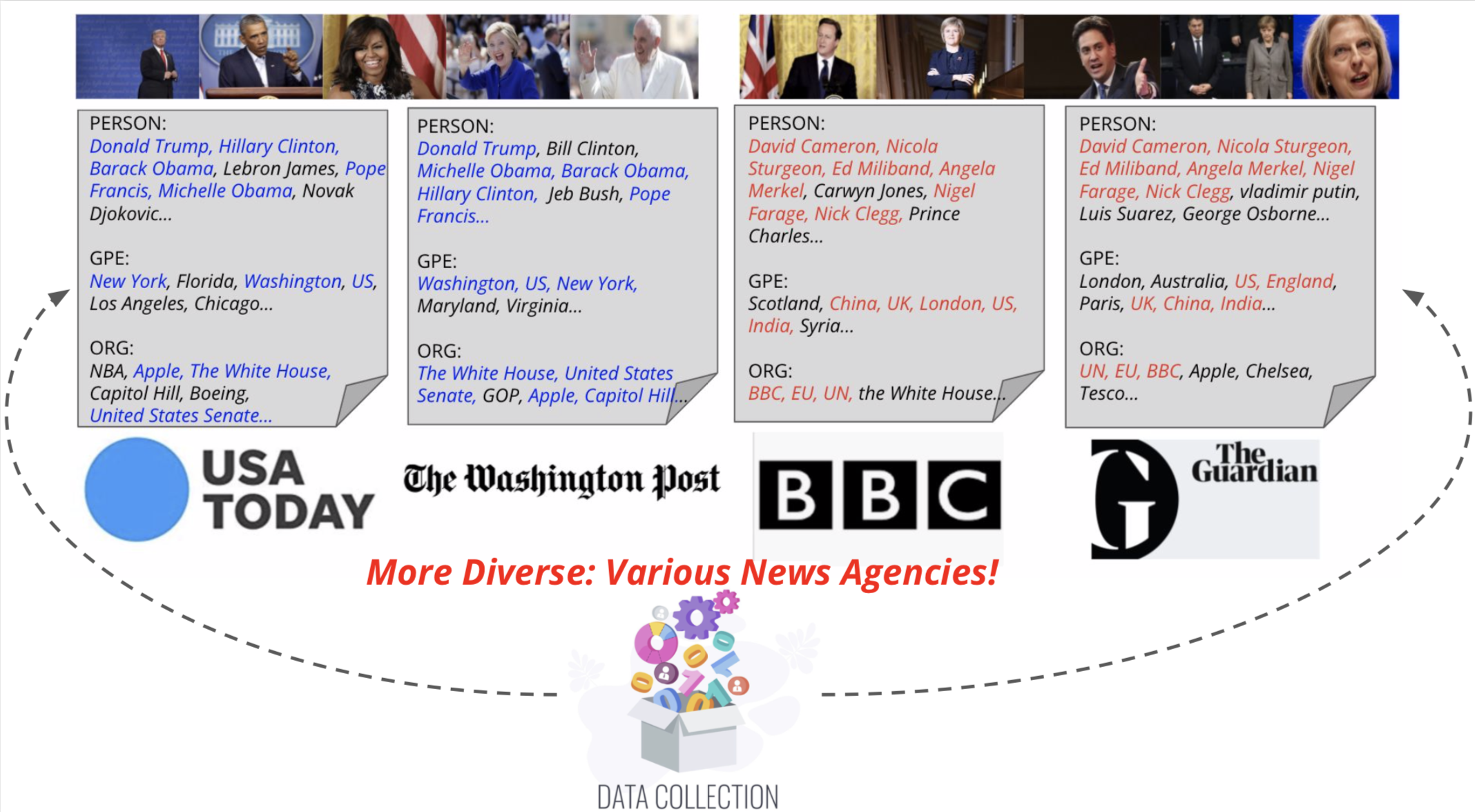
Мы предлагаем Visual News Captioner, модель, ориентированную на организацию, для задачи подписи изображения новостей. Мы также представляем Visual News, крупномасштабный эталон, состоящий из более чем миллиона новостных изображений, а также связанные новостные статьи, подписи изображений, информация о авторе и другие метаданные. В отличие от стандартной задачи подписания изображения, изображения новостей изображают ситуации, когда люди, местоположения и события имеют первостепенное значение. Наш предлагаемый метод может эффективно объединить визуальные и текстовые функции для создания подписей с более богатой информацией, такой как события и объекты. Более конкретно, основанная на архитектуре трансформатора, наша модель дополнительно оснащена новыми методами слияния мультимодальных функций и механизмом внимания, которые предназначены для более точного генерирования именных объектов. Наш метод использует гораздо меньше параметров, достигая немного лучших результатов прогнозирования, чем конкурирующие методы. Наш более крупный и более разнообразный набор данных о визуальных новостях дополнительно подчеркивает оставшиеся проблемы при подписании новостей.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
Код нашей модели находится в ./model.
CUDA_VISIBLE_DEVICES=0 python main.py
Если у вас есть какие -либо вопросы, пожалуйста, напишите: [email protected] 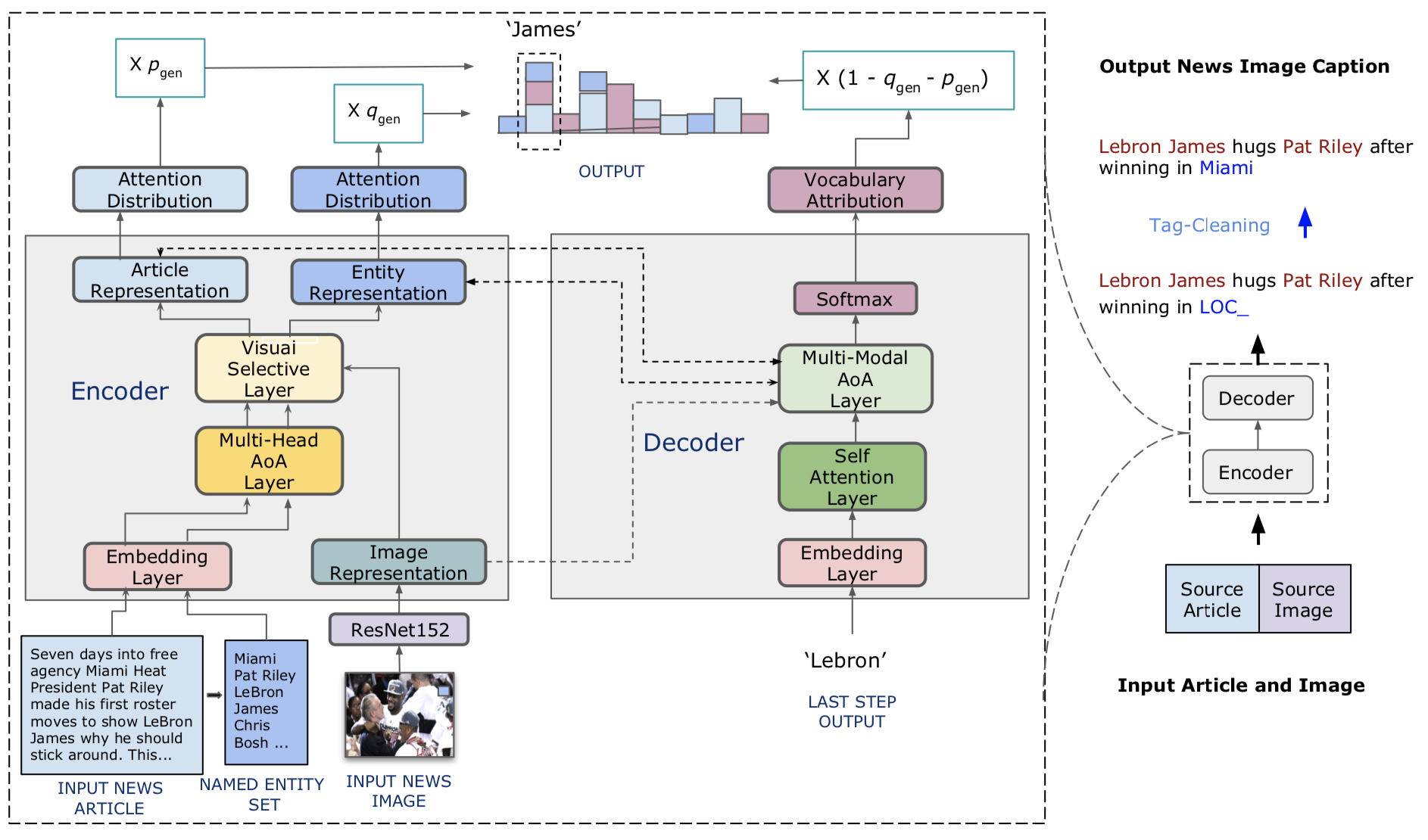
Если вы найдете нашу статью/код полезной, пожалуйста, рассмотрите возможность ссылаться на:


