VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
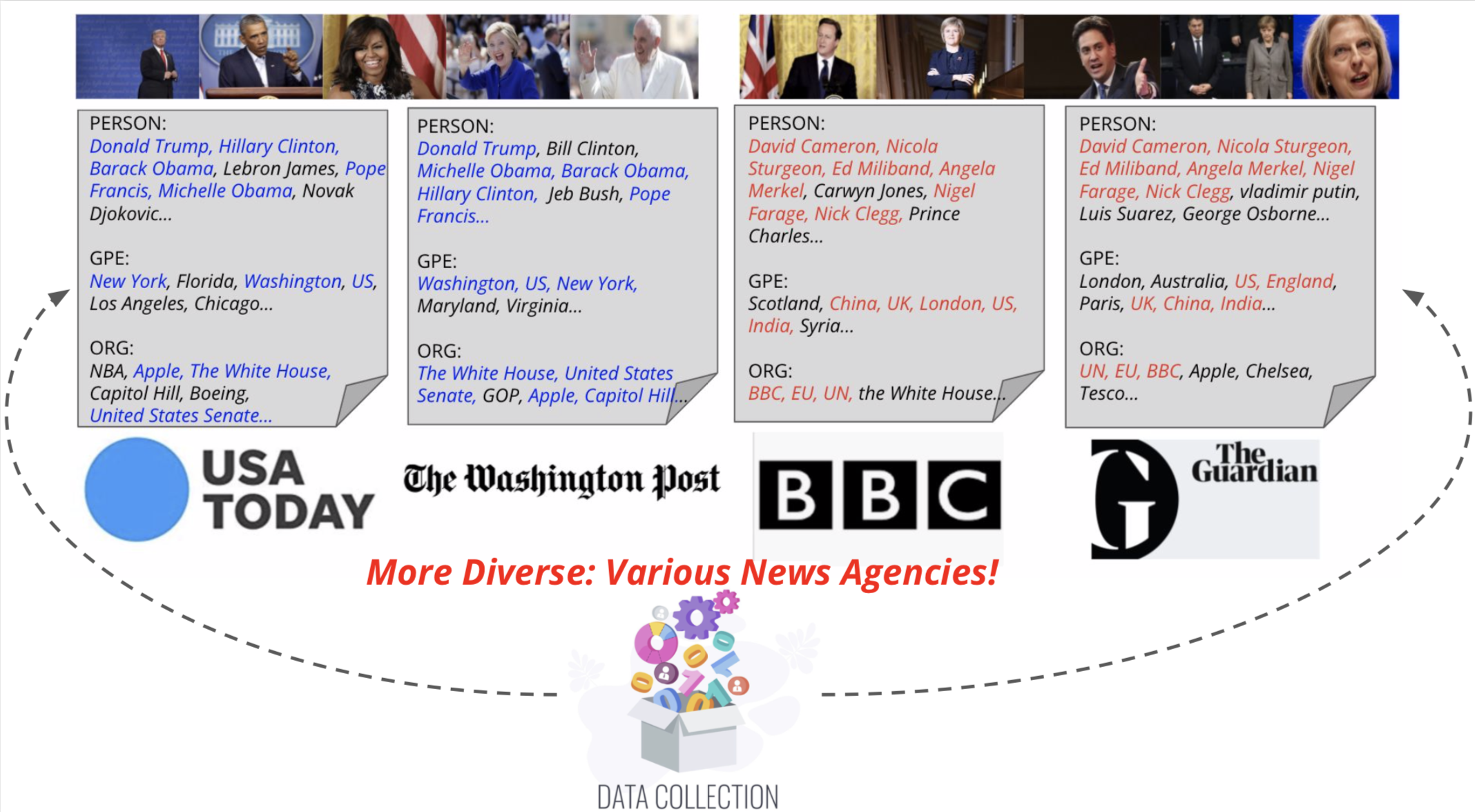
Propomos legendadores de notícias visuais, um modelo de consciência de entidade para a tarefa de legendas de imagens de notícias. Também introduzimos o Visual News, um benchmark em larga escala, composto por mais de um milhão de imagens de notícias, juntamente com artigos de notícias associados, legendas de imagens, informações do autor e outros metadados. Ao contrário da tarefa de legenda de imagem padrão, as imagens de notícias descrevem situações em que pessoas, locais e eventos são de suma importância. Nosso método proposto pode combinar efetivamente recursos visuais e textuais para gerar legendas com informações mais ricas, como eventos e entidades. Mais especificamente, construído sobre a arquitetura do transformador, nosso modelo está mais equipado com novas técnicas de fusão de recursos multimodais e mecanismos de atenção, projetados para gerar entidades nomeadas com mais precisão. Nosso método utiliza muito menos parâmetros e, ao mesmo tempo, alcançar resultados de previsão um pouco melhores do que os métodos concorrentes. Nosso conjunto de dados de notícias visuais maiores e mais diversificado destaca ainda mais os desafios restantes na legenda de imagens de notícias.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
O código do nosso modelo está em ./Model.
CUDA_VISIBLE_DEVICES=0 python main.py
Se você tiver alguma dúvida, envie um email: [email protected] 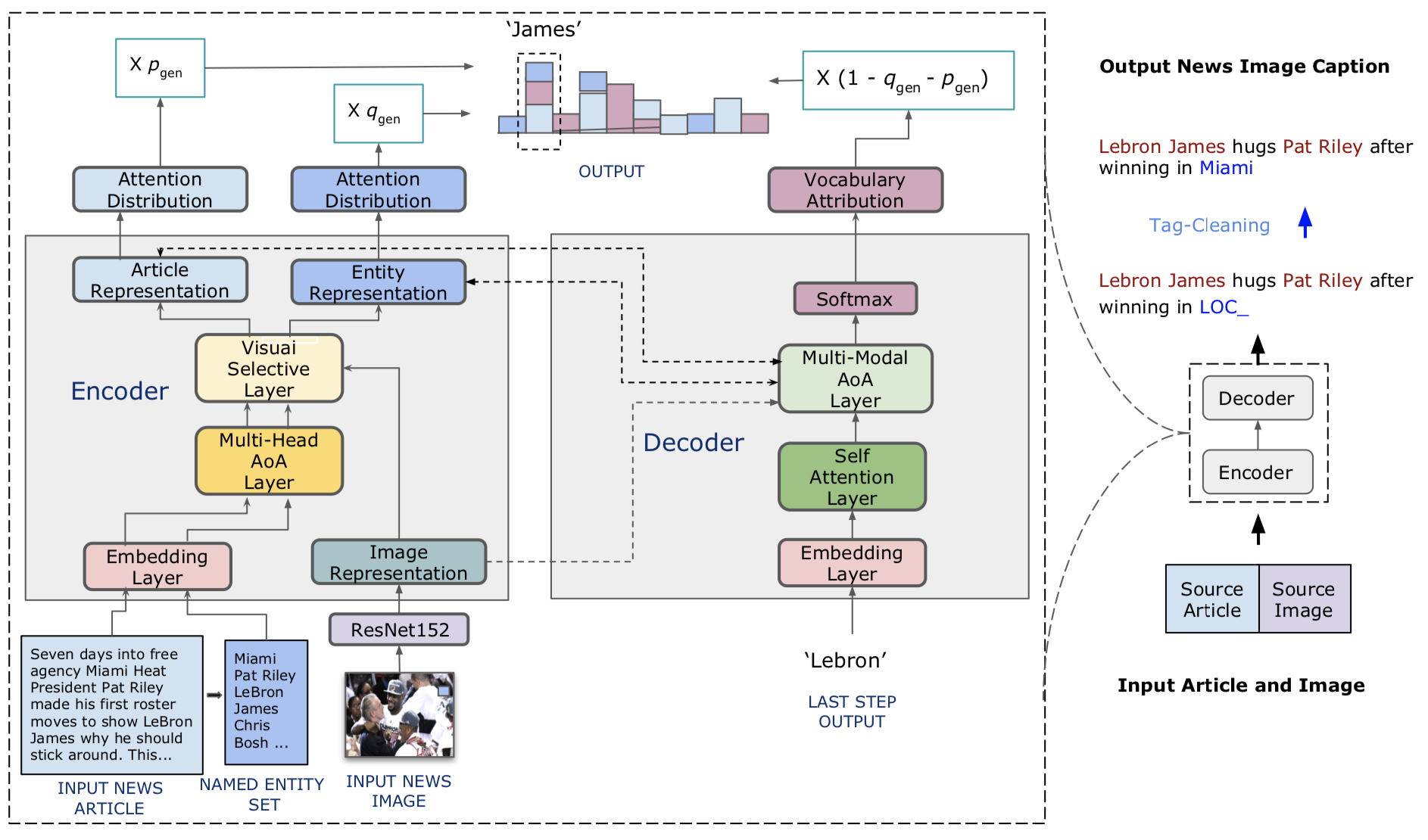
Se você achar útil nosso papel/código, considere citar:


