VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
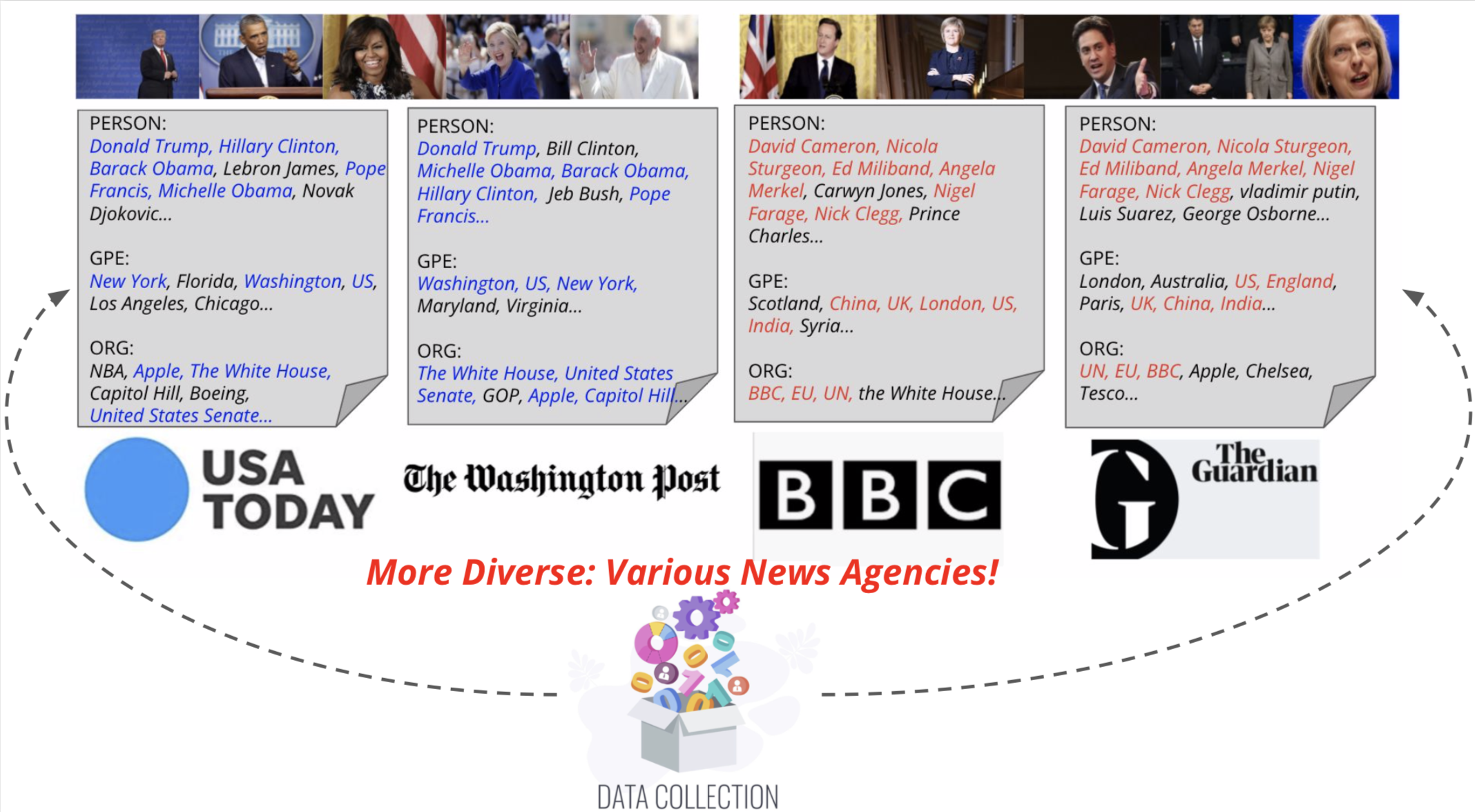
우리는 뉴스 이미지 캡션 작업을위한 엔티티 인식 모델 인 Visual News Captioner를 제안합니다. 또한 관련 뉴스 기사, 이미지 캡션, 저자 정보 및 기타 메타 데이터와 함께 백만 개 이상의 뉴스 이미지로 구성된 대규모 벤치 마크 인 Visual News를 소개합니다. 표준 이미지 캡션 작업과 달리 뉴스 이미지는 사람, 위치 및 이벤트가 가장 중요한 상황을 나타냅니다. 제안 된 방법은 시각적 및 텍스트 기능을 효과적으로 결합하여 캡션을 이벤트 및 엔티티와 같은 더 풍부한 정보로 생성 할 수 있습니다. 보다 구체적으로, Transformer Architecture를 기반으로 한 우리의 모델에는 새로운 멀티 모달 기능 Fusion 기술 및주의 메커니즘이 더욱 정확하게 장착되어 있으며,이 모델에는 명명 된 엔티티를보다 정확하게 생성하도록 설계되었습니다. 우리의 방법은 경쟁하는 방법보다 약간 더 나은 예측 결과를 달성하면서 훨씬 적은 매개 변수를 사용합니다. 우리의 더 크고 더 다양한 Visual News 데이터 세트는 캡션 뉴스 이미지의 나머지 과제를 강조합니다.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
우리 모델의 코드는 ./model에 있습니다.
CUDA_VISIBLE_DEVICES=0 python main.py
궁금한 점이 있으면 이메일 : [email protected] 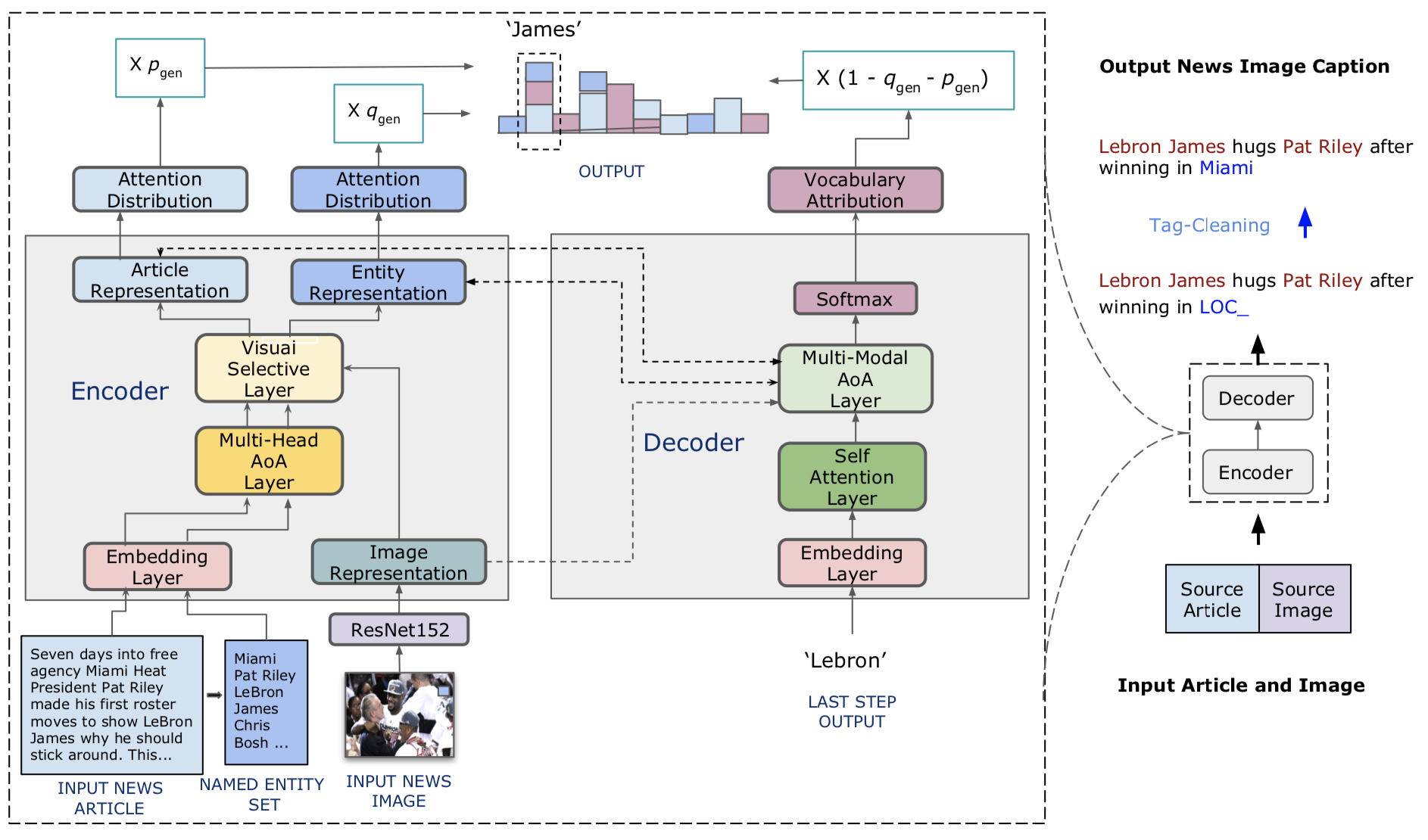
우리의 종이/코드가 유용하다고 생각되면 다음을 고려하십시오.


