VisualNews Repository
1.0.0
Fuxiao Liu, Yinghan Wang, Tianlu Wang, Vicente Ordonez (EMNLP 2021)
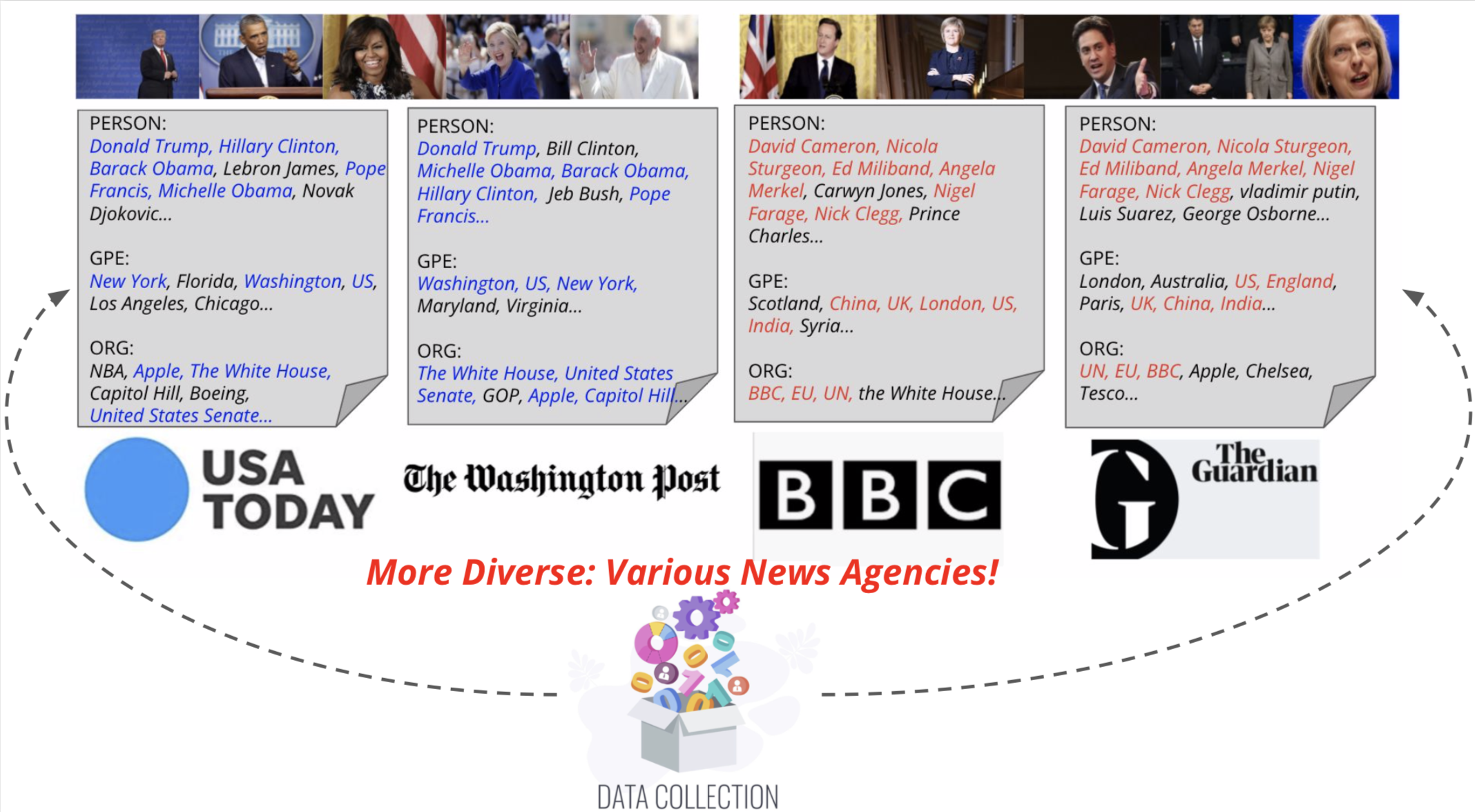
Wir schlagen visuelle Nachrichtenunterschriften vor, ein von entitätsbewusstes Modell für die Aufgabe der Nachrichtenbildunterschriften. Wir stellen auch visuelle Nachrichten vor, einen groß angelegten Benchmark, der aus mehr als einer Million Nachrichtenbildern zusammen mit zugehörigen Nachrichtenartikeln, Bildunterschriften, Autoreninformationen und anderen Metadaten besteht. Im Gegensatz zur Standardaufgabe zur Bildunterschrift zeigen Nachrichtenbilder Situationen, in denen Personen, Standorte und Ereignisse von größter Bedeutung sind. Unsere vorgeschlagene Methode kann visuelle und textuelle Funktionen effektiv kombinieren, um Bildunterschriften mit reicheren Informationen wie Ereignissen und Entitäten zu generieren. Insbesondere auf der Transformatorarchitektur basiert unser Modell weiter mit neuartigen multimodalen Fusionstechniken und Aufmerksamkeitsmechanismen, die so konzipiert sind, dass sie genauer genannte Entitäten generieren. Unsere Methode verwendet viel weniger Parameter und erzielte etwas bessere Vorhersageergebnisse als konkurrierende Methoden. In unserem größeren und vielfältigeren visuellen Nachrichtendatensatz werden die verbleibenden Herausforderungen bei der Bildunterschriftenbilder weiter hervorgehoben.
@misc{liu2020visualnews,
title={VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author={Fuxiao Liu and Yinghan Wang and Tianlu Wang and Vicente Ordonez},
year={2020},
eprint={2010.03743},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}
Der Code unseres Modells ist in ./Model.
CUDA_VISIBLE_DEVICES=0 python main.py
If you have any questions, please email: [email protected] 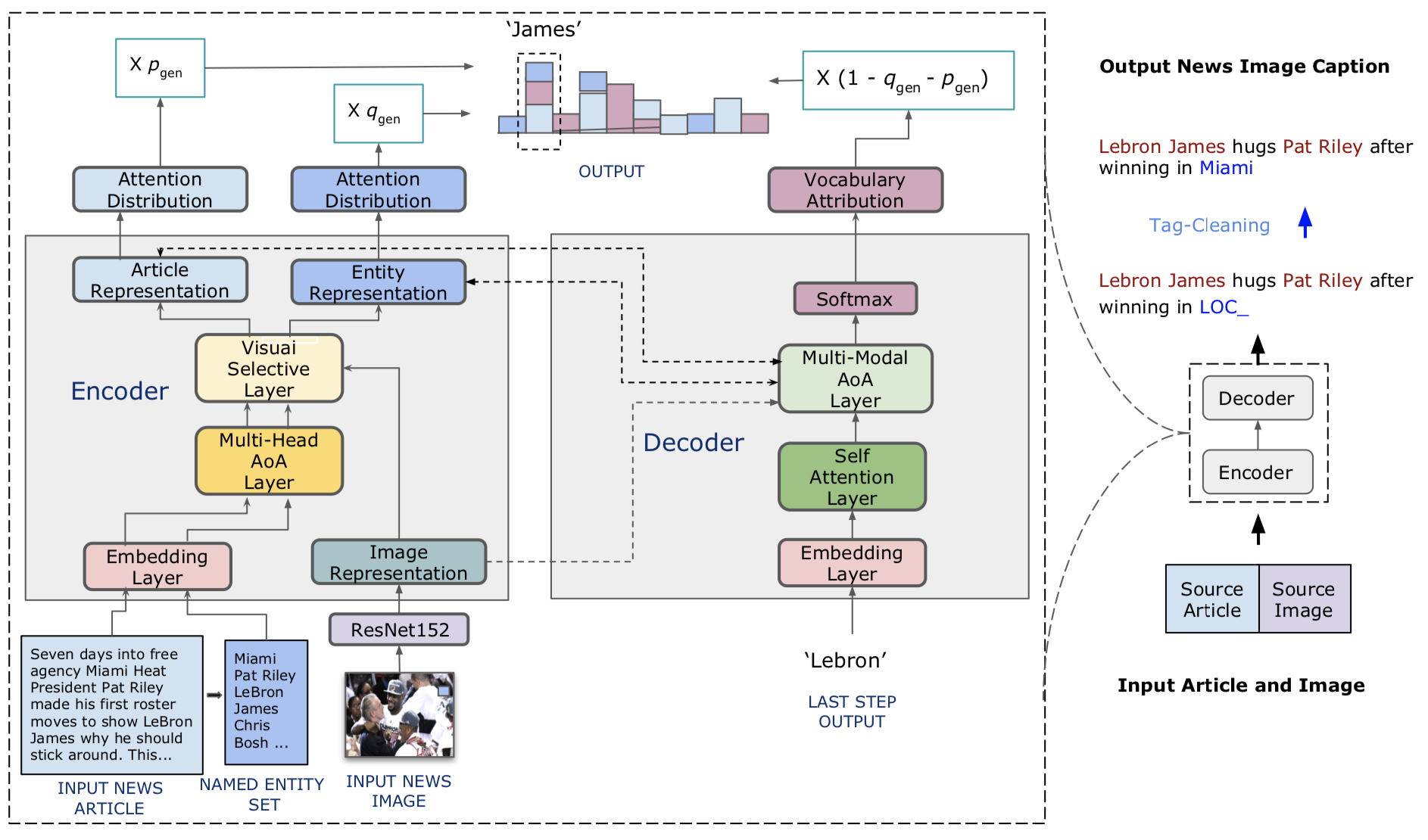
Wenn Sie unser Papier/Code nützlich finden, erwägen Sie bitte:


