AICoverGen
1.0.0
使用YouTube視頻或本地音頻文件的任何RVC V2訓練的AI語音來創建封面的自動管道。對於可能想在其AI助手/聊天機器人/VTUBER中添加歌唱功能的開發人員,或者想听聽自己喜歡的角色唱自己喜歡的歌曲的人。
展示櫃:https://www.youtube.com/watch?v=2qzue4wm7cm
設置指南:https://www.youtube.com/watch?v=pdlhk4vvhqk
WebUI正在不斷開發和測試中,但是您可以立即在本地和Colab上嘗試一下!
通過在AICoverGen目錄中打開命令行窗口並運行以下命令來安裝並提取任何新的要求和更改。
pip install -r requirements.txt
git pull
對於Colab用戶,只需在COLAB筆記本的頂部導航欄中單擊Runtime ,然後在下拉菜單中Disconnect and delete runtime 。然後按照筆記本中的說明運行WebUI。
對於那些沒有足夠強大的NVIDIA GPU的人,您可以使用Google Colab嘗試使用Aicovergen。
對於那些在幾分鐘後與Google CoLab筆記本上遇到問題的人,這是不使用webUI的替代方案。
對於那些想在本地運行的人,請遵循下面的設置指南。
請按照此處的說明在計算機上安裝GIT。另外,如果還沒有,請遵循本指南安裝Python版本3.9 。使用其他版本的Python可能會導致依賴性衝突。
請按照此處的說明在計算機上安裝FFMPEG。
請按照此處的說明進行安裝並將其添加到Windows路徑環境中。
打開命令行窗口並運行這些命令以克隆整個存儲庫,並安裝所需的其他依賴項。
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
運行以下命令以下載所需的MDXNET人聲分離模型和Hubert Base模型。
python src/download_models.py
要運行Aicovergen WebUI,請運行以下命令。
python src/webui.py
| 旗幟 | 描述 |
|---|---|
-h , --help | 顯示此幫助消息並退出。 |
--share | 創建一個公共網址。這對於在Google Colab上運行Web UI很有用。 |
--listen | 使Web UI從您的本地網絡達到。 |
--listen-host LISTEN_HOST | 服務器將使用的主機名。 |
--listen-port LISTEN_PORT | 服務器將使用的偵聽端口。 |
一旦出現以下輸出消息Running on local URL: http://127.0.0.1:7860出現,您可以單擊鏈接以使用WebUI打開選項卡。
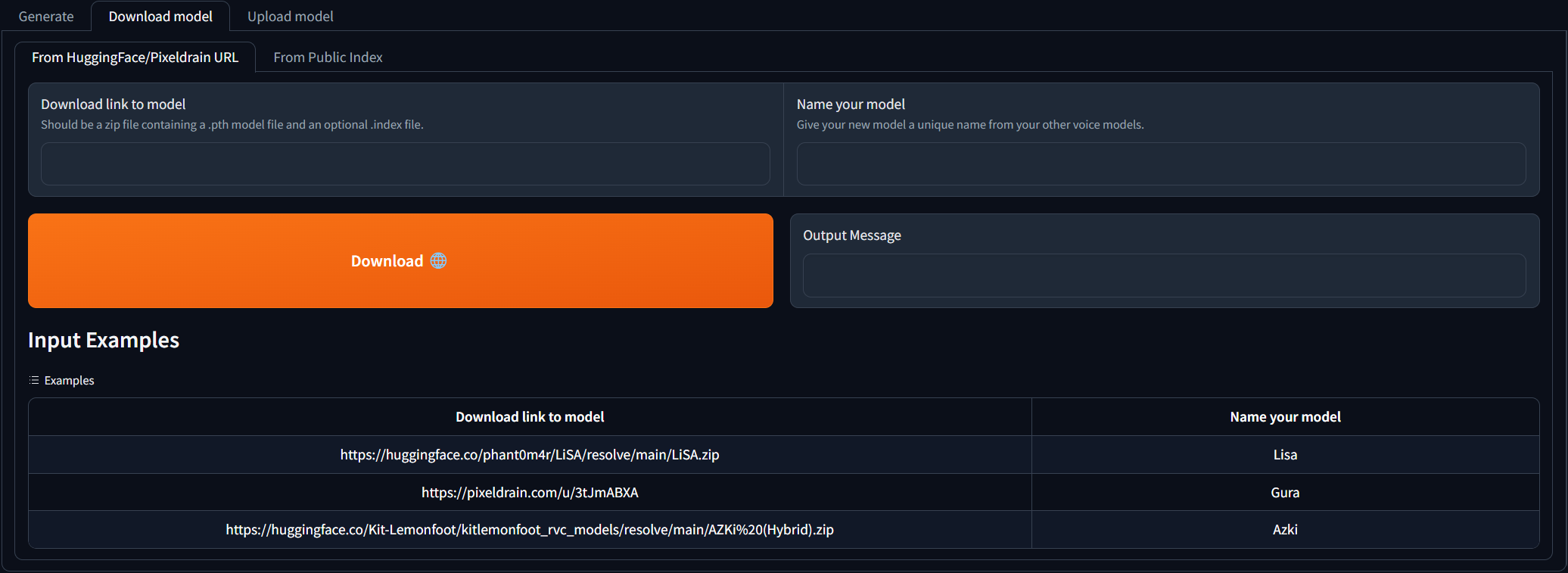
導航到Download model選項卡,然後將下載鏈接粘貼到RVC型號,並為其提供唯一的名稱。您可以搜索已訓練的語音模型可下載的AI Hub Discord。您可以參考下載鏈接的外觀示例。下載的zip文件應包含.pth模型文件和可選的.Index文件。
填寫兩個輸入字段後,只需單擊Download !一旦輸出消息說[NAME] Model successfully downloaded! ,單擊“刷新型號”按鈕後,您應該能夠在Generate選項卡中使用它!
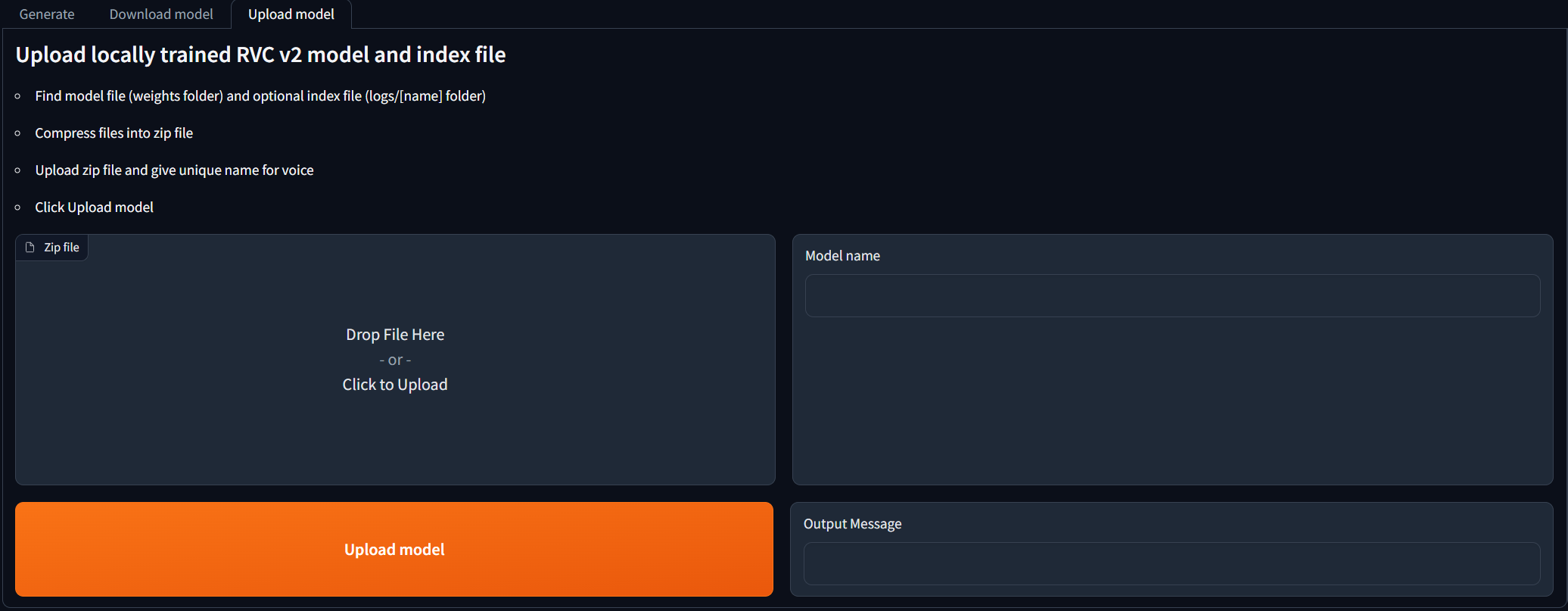
對於在當地訓練RVC V2型號並且想在AI封面幾代中使用它們的人。導航到Upload model選項卡,然後按照說明進行操作。一旦輸出消息說[NAME] Model successfully uploaded! ,單擊“刷新型號”按鈕後,您應該能夠在Generate選項卡中使用它!
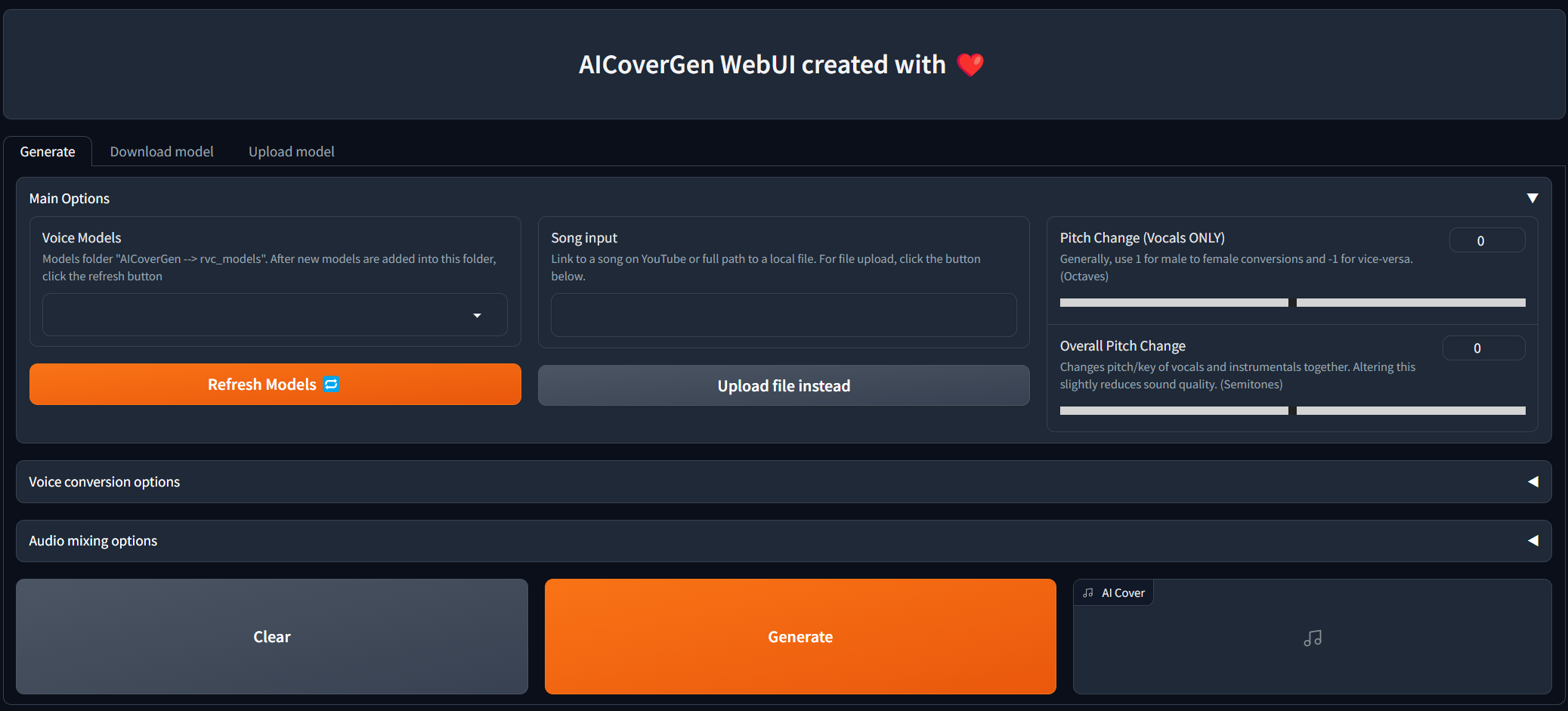
Update 。填寫所有主要選項後,單擊Generate ,並且AI生成的封面應在不到幾分鐘的時間內出現,具體取決於您的GPU。
解壓縮(如果需要),然後將.pth和.index文件傳輸到RVC_Models目錄中的新文件夾。每個文件夾只能包含一個.pth和一個.index文件。
目錄結構應該看起來像這樣:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
要使用命令行運行AI封面生成管道,請運行以下命令。
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| 旗幟 | 描述 |
|---|---|
-h , --help | 顯示此幫助消息並退出。 |
-i SONG_INPUT | 鏈接到YouTube上的歌曲或本地音頻文件的路徑。應將Windows的雙引號和類似Unix的系統的單引號封閉。 |
-dir MODEL_DIR_NAME | rvc_models目錄中包含您的.pth和.index文件的文件夾的名稱。 |
-p PITCH_CHANGE | 改變八度音調的AI聲音。設置為0,以免更改。通常,使用1用於雄性轉化為女性,為-1用於副副主席。 |
-k | 選修的。可以添加以保持所有中間音頻文件生成。例如隔離AI人聲/樂器。留出來節省空間。 |
-ir INDEX_RATE | 選修的。默認為0.5。控制AI留下多少口音。 0 <= index_rate <= 1。 |
-fr FILTER_RADIUS | 選修的。默認3。如果> = 3:將中值過濾濾波到收穫的音高結果。 0 <= filter_radius <= 7。 |
-rms RMS_MIX_RATE | 選修的。默認為0.25。控制使用原始聲樂的響度(0)或固定的響度(1)的多少。 0 <= rms_mix_rate <= 1。 |
-palgo PITCH_DETECTION_ALGO | 選修的。默認RMVPE。最佳選擇是RMVPE(人聲清晰),然後是Mangio-Crepe(聲音更平滑)。 |
-hop CREPE_HOP_LENGTH | 選修的。默認值128。控制使用Mangio-Crepe Algo專門使用毫秒的音高變化的頻率。較低的值會導致更長的轉換和更高的語音裂紋風險,但音高準確性更好。 |
-pro PROTECT | 選修的。默認為0.33。控制有多少原始人聲的呼吸和無聲的輔音留在AI人聲中。設置為0.5以禁用。 0 <=保護<= 0.5。 |
-mv MAIN_VOCALS_VOLUME_CHANGE | 選修的。默認為0。主AI人聲的控制音量。使用-3將體積減少3分貝,或3分貝,將體積增加3分貝。 |
-bv BACKUP_VOCALS_VOLUME_CHANGE | 選修的。默認為0。備份AI人聲的控制量。 |
-iv INSTRUMENTAL_VOLUME_CHANGE | 選修的。默認值0。背景音樂/樂器的控製卷。 |
-pall PITCH_CHANGE_ALL | 選修的。默認值0。在半音中更改背景音樂,備份人聲和AI人聲的鑰匙。略微降低了聲音質量。 |
-rsize REVERB_SIZE | 選修的。默認為0.15。房間越大,混響時間越長。 0 <= Reverb_size <= 1。 |
-rwet REVERB_WETNESS | 選修的。默認為0.2。帶有混響的AI人聲級別。 0 <= Reverb_wetness <= 1。 |
-rdry REVERB_DRYNESS | 選修的。默認為0.8。無混音的AI人聲級別。 0 <= reverb_dryness <= 1。 |
-rdamp REVERB_DAMPING | 選修的。默認為0.7。混響中高頻的吸收。 0 <= Reverb_damping <= 1。 |
-oformat OUTPUT_FORMAT | 選修的。默認mp3。 WAV的最佳質量和較大的文件大小,MP3的質量不錯,文件大小。 |
禁止將轉換的語音用於以下目的。
批評或攻擊個人。
倡導或反對特定的政治立場,宗教或意識形態。
公開表現出強烈的刺激表達式,而無需進行適當的分區。
銷售語音模型和生成的語音剪輯。
冒充聲音的原始主人,以惡意傷害/傷害他人的意圖。
導致身份盜用或欺詐性電話的欺詐目的。
我對與使用/濫用或無法使用此軟件有關的任何直接,間接,結果,附帶或特殊損害不承擔任何責任。


