AICoverGen
1.0.0
Una tubería autónoma para crear cubiertas con cualquier voz de IA capacitada por RVC V2 desde videos de YouTube o un archivo de audio local. Para los desarrolladores que quieran agregar una funcionalidad de canto a su asistente de IA/chatbot/vtuber, o para las personas que desean escuchar a sus personajes favoritos cantar su canción favorita.
Showcase: https://www.youtube.com/watch?v=2qzue4wm7cm
Guía de configuración: https://www.youtube.com/watch?v=pdlhk4vvhqk
Webui está bajo desarrollo y pruebas constantes, ¡pero puede probarlo ahora mismo en Local y Colab!
Instale y extraiga cualquier nuevo requisito y cambio abriendo una ventana de línea de comandos en el directorio AICoverGen y ejecutando los siguientes comandos.
pip install -r requirements.txt
git pull
Para los usuarios de Colab, simplemente haga clic en Runtime en la barra de navegación superior del cuaderno de Colab y Disconnect and delete runtime en el menú desplegable. Luego siga las instrucciones en el cuaderno para ejecutar el webui.
Para aquellos que no tienen una GPU NVIDIA lo suficientemente potente, pueden probar AiCovergen Out usando Google Colab.
Para aquellos que enfrentan problemas con la desconexión del cuaderno de Google Colab después de unos minutos, aquí hay una alternativa que no usa el WebUI.
Para aquellos que desean ejecutar esto localmente, siga la guía de configuración a continuación.
Siga las instrucciones aquí para instalar Git en su computadora. También siga esta guía para instalar Python versión 3.9 si aún no lo ha hecho. El uso de otras versiones de Python puede dar lugar a conflictos de dependencia.
Siga las instrucciones aquí para instalar FFMPEG en su computadora.
Siga las instrucciones aquí para instalar Sox y agréguelo a su entorno de ruta de Windows.
Abra una ventana de línea de comando y ejecute estos comandos para clonar todo este repositorio e instalar las dependencias adicionales requeridas.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
Ejecute el siguiente comando para descargar los modelos de separación vocal MDXNet requeridos y el modelo base Hubert.
python src/download_models.py
Para ejecutar AiCovergen WebUI, ejecute el siguiente comando.
python src/webui.py
| Bandera | Descripción |
|---|---|
-h , --help | Muestre este mensaje de ayuda y salida. |
--share | Crear una URL pública. Esto es útil para ejecutar la interfaz de usuario web en Google Colab. |
--listen | Haga que la interfaz de usuario web sea accesible desde su red local. |
--listen-host LISTEN_HOST | El nombre de host que usará el servidor. |
--listen-port LISTEN_PORT | El puerto de escucha que usará el servidor. |
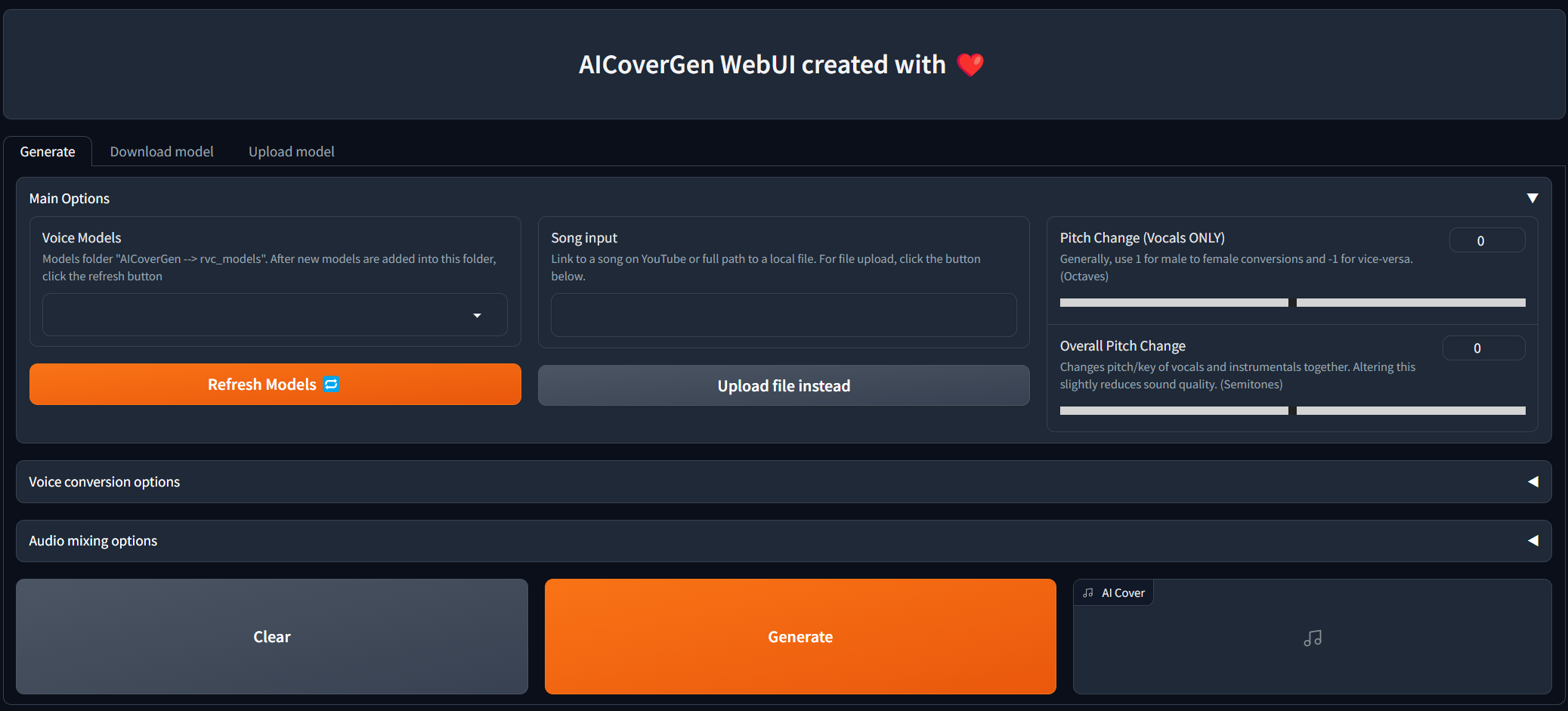
Una vez que aparece el siguiente mensaje de salida Running on local URL: http://127.0.0.1:7860 , puede hacer clic en el enlace para abrir una pestaña con el webui.
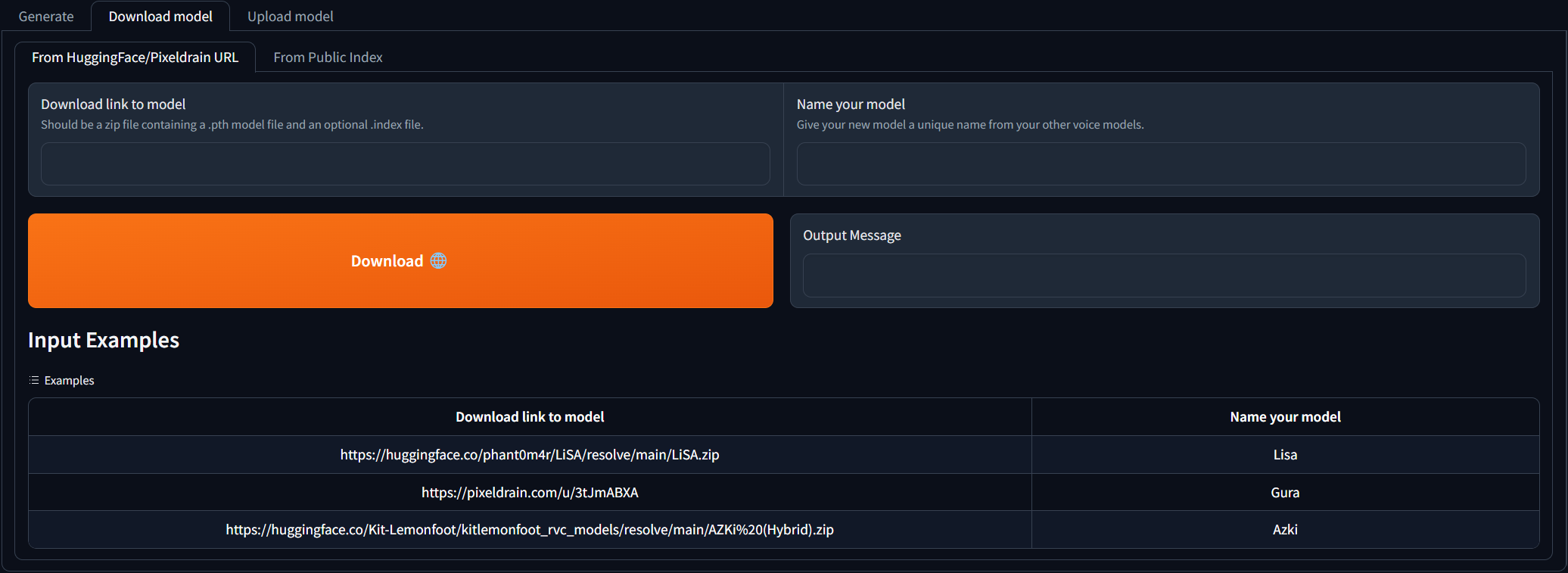
Navegue a la pestaña Download model y pegue el enlace de descarga al modelo RVC y dale un nombre único. Puede buscar en la discordia del centro de AI donde los modelos de voz ya entrenados están disponibles para descargar. Puede consultar los ejemplos de cómo debería ser el enlace de descarga. El archivo zip descargado debe contener el archivo del modelo .pth y un archivo .index opcional.
Una vez que se completan los 2 campos de entrada, simplemente haga clic en Download ! ¡Una vez que el mensaje de salida dice [NAME] Model successfully downloaded! ¡Debería poder usarlo en la pestaña Generate después de hacer clic en el botón Rebresh Models!
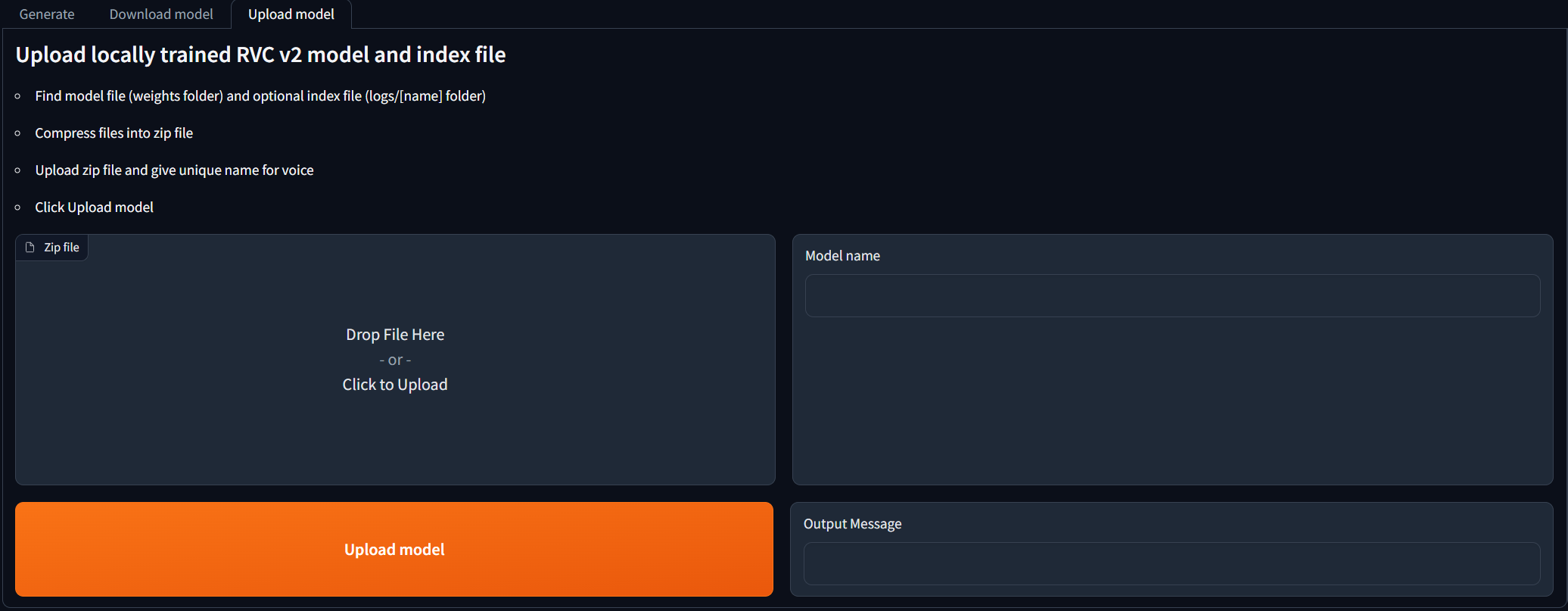
Para las personas que han entrenado modelos RVC V2 localmente y desean usarlos para las generaciones de portada de IA. Navegue a la pestaña Upload model y siga las instrucciones. ¡Una vez que el mensaje de salida dice [NAME] Model successfully uploaded! ¡Debería poder usarlo en la pestaña Generate después de hacer clic en el botón Rebresh Models!
Update si agregó los archivos manualmente al directorio RVC_Models para actualizar la lista. Una vez que se completen todas las opciones principales, haga clic en Generate y la cubierta generada por IA debe aparecer en menos de unos minutos dependiendo de su GPU.
Unzip (si es necesario) y transfiera los archivos .pth y .index a una nueva carpeta en el directorio rvc_models. Cada carpeta solo debe contener un archivo .pth y un .index .
La estructura del directorio debería verse algo así:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
Para ejecutar la tubería de generación de cobertura de IA usando la línea de comando, ejecute el siguiente comando.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| Bandera | Descripción |
|---|---|
-h , --help | Muestre este mensaje de ayuda y salida. |
-i SONG_INPUT | Enlace a una canción en YouTube o ruta a un archivo de audio local. Debe estar encerrado en cotizaciones dobles para Windows y citas individuales para sistemas similares a UNIX. |
-dir MODEL_DIR_NAME | Nombre de la carpeta en el directorio rvc_models que contiene sus archivos .pth y .index para una voz específica. |
-p PITCH_CHANGE | Cambiar el lanzamiento de las voces de IA en octavas. Establecer en 0 para no cambiar. En general, use 1 para conversiones masculinas a femeninas y -1 para viceversa. |
-k | Opcional. Se puede agregar para mantener todos los archivos de audio intermedios generados. por ejemplo, voces/instrumentales aislados de IA. Deje fuera para ahorrar espacio. |
-ir INDEX_RATE | Opcional. Predeterminado 0.5. Controle cuánto del acento de la IA dejar en la voz. 0 <= index_rate <= 1. |
-fr FILTER_RADIUS | Opcional. Predeterminado 3. IF> = 3: Aplicar el filtrado mediano de filtrado mediano a los resultados del tono cosechado. 0 <= Filter_radius <= 7. |
-rms RMS_MIX_RATE | Opcional. Predeterminado 0.25. Controle cuánto usar el volumen de la voz original (0) o un volumen fijo (1). 0 <= rms_mix_rate <= 1. |
-palgo PITCH_DETECTION_ALGO | Opcional. RMVPE predeterminado. La mejor opción es RMVPE (claridad en la voz), luego Mangio-CREPE (voces más suaves). |
-hop CREPE_HOP_LENGTH | Opcional. Predeterminado 128. Controla con qué frecuencia verifica los cambios de tono en milisegundos cuando se usa específicamente algo Mangio-Crepe. Los valores más bajos conducen a conversiones más largas y un mayor riesgo de grietas de voz, pero una mejor precisión del tono. |
-pro PROTECT | Opcional. Predeterminado 0.33. Controle cuánto de la aliento de las voces originales y las consonantes sin voz para dejar en las voces de IA. Establecer 0.5 para deshabilitar. 0 <= proteger <= 0.5. |
-mv MAIN_VOCALS_VOLUME_CHANGE | Opcional. Predeterminado 0. Volumen de control de las principales voces de IA. Use -3 para disminuir el volumen en 3 decibelios, o 3 para aumentar el volumen en 3 decibelios. |
-bv BACKUP_VOCALS_VOLUME_CHANGE | Opcional. Predeterminado 0. Volumen de control de las voces de AI de respaldo. |
-iv INSTRUMENTAL_VOLUME_CHANGE | Opcional. Predeterminado 0. Volumen de control de la música/instrumentos de fondo. |
-pall PITCH_CHANGE_ALL | Opcional. Predeterminado 0. Cambie el tono/clave de la música de fondo, la voz de copia de seguridad y las voces de IA en los semitonos. Reduce ligeramente la calidad del sonido. |
-rsize REVERB_SIZE | Opcional. Predeterminado 0.15. Cuanto más grande sea la habitación, más tiempo será el tiempo de la reverberación. 0 <= reverb_size <= 1. |
-rwet REVERB_WETNESS | Opcional. Predeterminado 0.2. Nivel de voces de IA con reverb. 0 <= reverb_wetness <= 1. |
-rdry REVERB_DRYNESS | Opcional. Predeterminado 0.8. Nivel de voces de IA sin reverberación. 0 <= Reverb_Dryness <= 1. |
-rdamp REVERB_DAMPING | Opcional. Predeterminado 0.7. Absorción de altas frecuencias en la reverb. 0 <= reverb_damping <= 1. |
-oformat OUTPUT_FORMAT | Opcional. MP3 predeterminado. WAV para la mejor calidad y tamaño de archivo grande, MP3 para calidad decente y tamaño de archivo pequeño. |
Se prohíbe el uso de la voz convertida para los siguientes fines.
Criticar o atacar a los individuos.
Defender u oponerse a posiciones políticas específicas, religiones o ideologías.
Mostrando públicamente expresiones fuertemente estimulantes sin la zonificación adecuada.
Venta de modelos de voz y clips de voz generados.
Suplantación del propietario original de la voz con intenciones maliciosas de dañar/dañar a otros.
Propósitos fraudulentos que conducen al robo de identidad o llamadas telefónicas fraudulentas.
No soy responsable de los daños directos, indirectos, consecuentes, incidentales o especiales que surgen de cualquier manera relacionada con el uso/mal uso o incapacidad de usar este software.


