AICoverGen
1.0.0
Um pipeline autônomo para criar capas com qualquer voz de AI treinada RVC V2 a partir de vídeos do YouTube ou um arquivo de áudio local. Para os desenvolvedores que podem querer adicionar uma funcionalidade de canto em seu assistente de IA/chatbot/vtuber, ou para pessoas que querem ouvir seus personagens favoritos cantar sua música favorita.
Showcase: https://www.youtube.com/watch?v=2qzue4wm7cm
Guia de configuração: https://www.youtube.com/watch?v=pdlhk4vvhqk
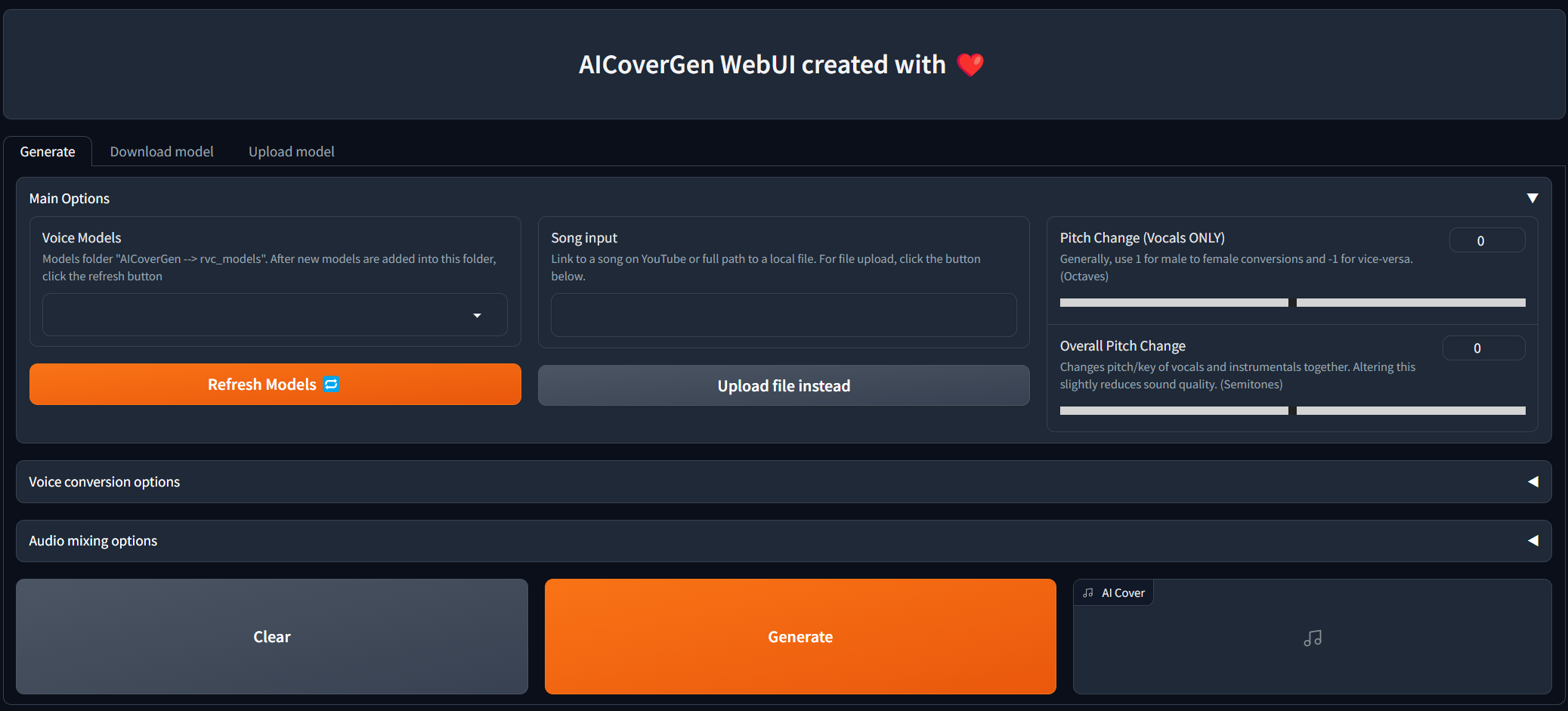
O Webui está sob constante desenvolvimento e teste, mas você pode experimentá -lo agora no local e no Colab!
Instale e puxe todos os novos requisitos e alterações abrindo uma janela da linha de comando no diretório AICoverGen e executando os seguintes comandos.
pip install -r requirements.txt
git pull
Para os usuários do COLAB, basta clicar em Runtime na barra de navegação superior do notebook Colab e Disconnect and delete runtime no menu suspenso. Em seguida, siga as instruções no caderno para executar o webui.
Para aqueles sem uma GPU da NVIDIA o suficiente, você pode experimentar o Aicovergen usando o Google Colab.
Para aqueles que enfrentam problemas com o Google Colab Notebook desconectando após alguns minutos, aqui está uma alternativa que não usa o webui.
Para quem deseja executar isso localmente, siga o guia de configuração abaixo.
Siga as instruções aqui para instalar o git no seu computador. Siga também este guia para instalar o Python versão 3.9, se você ainda não o fez. O uso de outras versões do Python pode resultar em conflitos de dependência.
Siga as instruções aqui para instalar o FFMPEG no seu computador.
Siga as instruções aqui para instalar o Sox e adicione -o ao ambiente do Windows Path.
Abra uma janela da linha de comando e execute esses comandos para clonar todo esse repositório e instalar as dependências adicionais necessárias.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
Execute o seguinte comando para baixar os modelos de separação vocal MDXNET necessários e o modelo básico de Hubert.
python src/download_models.py
Para executar o Aicovergen Webui, execute o seguinte comando.
python src/webui.py
| Bandeira | Descrição |
|---|---|
-h , --help | Mostre esta mensagem de ajuda e saída. |
--share | Crie um URL público. Isso é útil para executar a interface do usuário da web no Google Colab. |
--listen | Torne a interface do usuário da Web acessível em sua rede local. |
--listen-host LISTEN_HOST | O nome do host que o servidor usará. |
--listen-port LISTEN_PORT | A porta de escuta que o servidor usará. |
Depois que a seguinte mensagem de saída Running on local URL: http://127.0.0.1:7860 aparecer, você pode clicar no link para abrir uma guia com o webui.
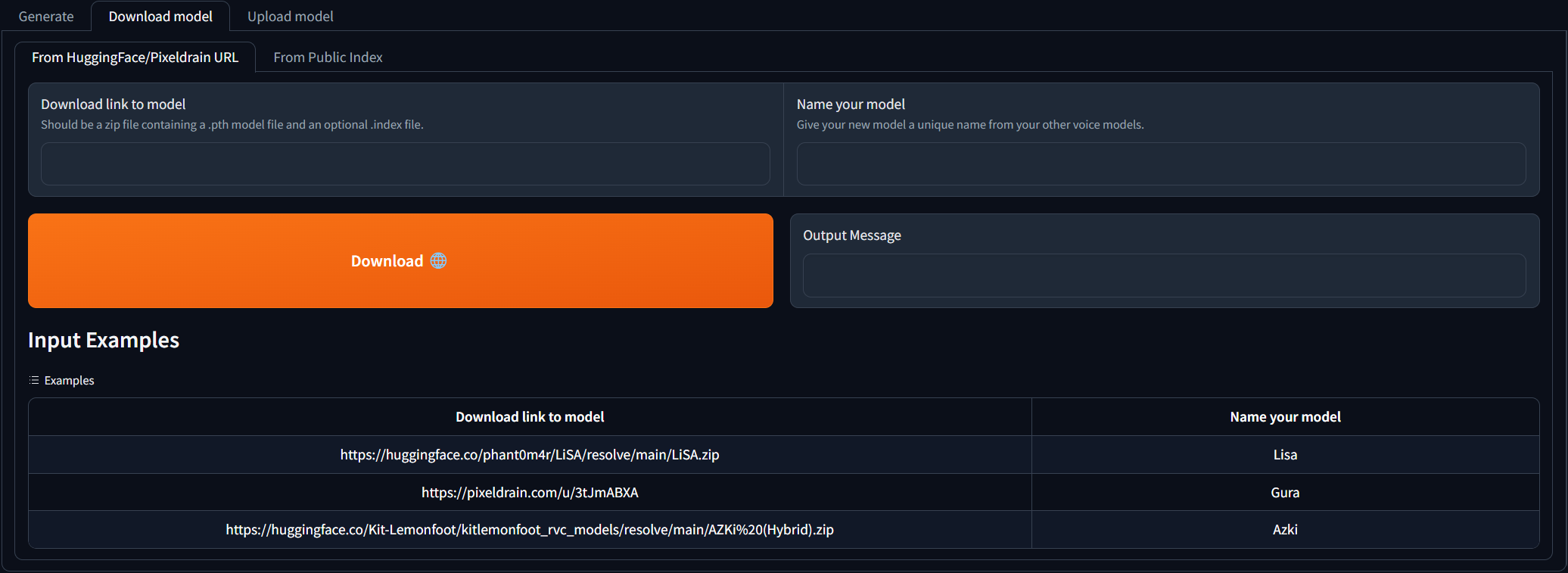
Navegue até a guia Download model e cole o link de download para o modelo RVC e dê um nome exclusivo. Você pode pesquisar a AI Hub Discord, onde os modelos de voz já treinados estão disponíveis para download. Você pode se referir aos exemplos de como o link de download deve ser. O arquivo zip baixado deve conter o arquivo .PTH Model e um arquivo .Index opcional.
Depois que os 2 campos de entrada forem preenchidos, basta clicar em Download ! Depois que a mensagem de saída diz [NAME] Model successfully downloaded! , você poderá usá -lo na guia Generate depois de clicar no botão Modelos de atualização!
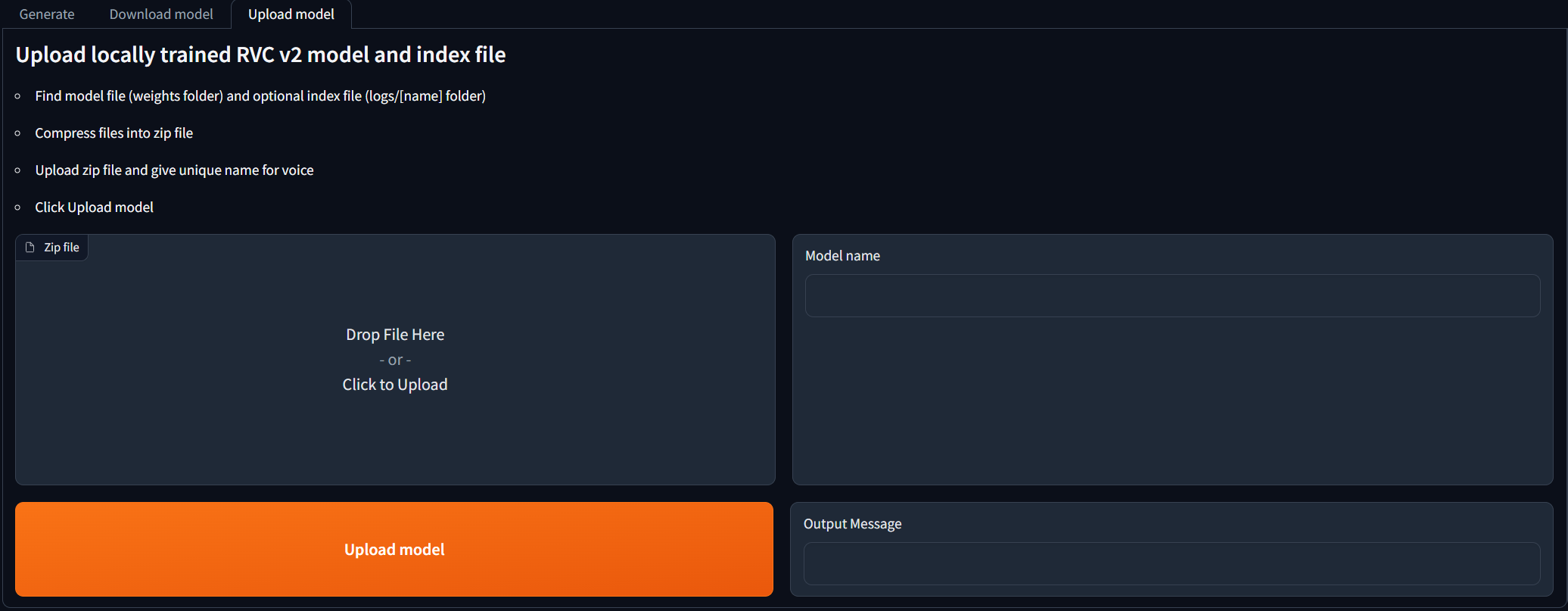
Para as pessoas que treinaram os modelos RVC V2 localmente e gostariam de usá -los para as gerações de cobertura de IA. Navegue até a guia Upload model e siga as instruções. Depois que a mensagem de saída diz [NAME] Model successfully uploaded! , você poderá usá -lo na guia Generate depois de clicar no botão Modelos de atualização!
Update se você adicionou os arquivos manualmente ao diretório rvc_models para atualizar a lista. Depois que todas as opções principais forem preenchidas, clique Generate e a tampa gerada pela IA deve aparecer em menos de alguns minutos, dependendo da sua GPU.
Unzip (se necessário) e transfira os arquivos .pth e .index para uma nova pasta no diretório rvc_models. Cada pasta deve conter apenas um arquivo .pth e um .index .
A estrutura do diretório deve parecer algo assim:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
Para executar o pipeline de geração de capa da IA usando a linha de comando, execute o seguinte comando.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| Bandeira | Descrição |
|---|---|
-h , --help | Mostre esta mensagem de ajuda e saída. |
-i SONG_INPUT | Link para uma música no YouTube ou caminho para um arquivo de áudio local. Deve ser incluído em cotações duplas para janelas e citações únicas para sistemas semelhantes a Unix. |
-dir MODEL_DIR_NAME | Nome da pasta no diretório rvc_models, contendo seus arquivos .pth e .index para uma voz específica. |
-p PITCH_CHANGE | Mude o tom de vocais de IA em oitavas. Definido como 0 sem alteração. Geralmente, use 1 para conversões masculinas para mulheres e -1 para vice -versa. |
-k | Opcional. Pode ser adicionado para manter todos os arquivos de áudio intermediários gerados. por exemplo, vocais/instrumentais isolados de IA. Deixe de fora para economizar espaço. |
-ir INDEX_RATE | Opcional. Padrão 0,5. Controle quanto do sotaque da IA deixar nos vocais. 0 <= index_rate <= 1. |
-fr FILTER_RADIUS | Opcional. Padrão 3. Se> = 3: Aplique a filtragem mediana da filtragem mediana nos resultados da afinação colhida. 0 <= filtro_radius <= 7. |
-rms RMS_MIX_RATE | Opcional. Padrão 0,25. Controle quanto usar o volume do vocal original (0) ou um volume fixo (1). 0 <= rms_mix_rate <= 1. |
-palgo PITCH_DETECTION_ALGO | Opcional. RMVPE padrão. A melhor opção é o RMVPE (clareza nos vocais), depois Mangio-Crepe (vocais mais suaves). |
-hop CREPE_HOP_LENGTH | Opcional. O padrão 128. Controla a frequência com que ele verifica as mudanças de afinação em milissegundos ao usar o algo Mangio-Crepe especificamente. Valores mais baixos levam a conversões mais longas e maior risco de rachaduras de voz, mas melhor precisão de afinação. |
-pro PROTECT | Opcional. Padrão 0,33. Controle quanto dos vocais originais e consoantes sem voz para deixar os vocais da IA. Defina 0,5 para desativar. 0 <= Protect <= 0,5. |
-mv MAIN_VOCALS_VOLUME_CHANGE | Opcional. Padrão 0. Volume de controle dos principais vocais da IA. Use -3 para diminuir o volume em 3 decibéis, ou 3 para aumentar o volume em 3 decibéis. |
-bv BACKUP_VOCALS_VOLUME_CHANGE | Opcional. Padrão 0. Volume de controle de vocais de backup AI. |
-iv INSTRUMENTAL_VOLUME_CHANGE | Opcional. Padrão 0. Volume de controle das músicas/instrumentais de fundo. |
-pall PITCH_CHANGE_ALL | Opcional. Padrão 0. Altere o passo/chave da música de fundo, vocais de backup e vocais de IA em semitones. Reduz a qualidade do som um pouco. |
-rsize REVERB_SIZE | Opcional. Padrão 0,15. Quanto maior a sala, mais tempo o tempo de reverb. 0 <= reverb_size <= 1. |
-rwet REVERB_WETNESS | Opcional. Padrão 0,2. Nível de vocais de IA com reverb. 0 <= reverb_wetness <= 1. |
-rdry REVERB_DRYNESS | Opcional. Padrão 0,8. Nível de vocais de IA sem reverb. 0 <= reverb_dryness <= 1. |
-rdamp REVERB_DAMPING | Opcional. Padrão 0,7. Absorção de altas frequências no reverb. 0 <= reverb_damping <= 1. |
-oformat OUTPUT_FORMAT | Opcional. MP3 padrão. WAV para a melhor qualidade e tamanho de arquivo grande, MP3 para qualidade decente e tamanho de arquivo pequeno. |
É proibido o uso da voz convertida para os seguintes propósitos.
Criticando ou atacando indivíduos.
Advogando ou opondo posições políticas específicas, religiões ou ideologias.
Exibindo publicamente expressões fortemente estimulantes sem o zoneamento adequado.
Venda de modelos de voz e clipes de voz gerados.
Representação do proprietário original da voz com intenções maliciosas de prejudicar/prejudicar os outros.
Fins fraudulentos que levam a roubo de identidade ou telefonemas fraudulentos.
Não sou responsável por nenhum dano direto, indireto, conseqüente, incidental ou especial decorrente de ou de qualquer forma relacionada ao uso/uso indevido ou incapacidade de usar este software.


