AICoverGen
1.0.0
ไปป์ไลน์อิสระในการสร้างหน้าปกด้วย RVC V2 ใด ๆ ที่ได้รับการฝึกฝน AI Voice จากวิดีโอ YouTube หรือไฟล์เสียงท้องถิ่น สำหรับนักพัฒนาที่อาจต้องการเพิ่มฟังก์ชั่นการร้องเพลงลงใน AI Assistant/Chatbot/Vtuber ของพวกเขาหรือสำหรับผู้ที่ต้องการฟังตัวละครที่พวกเขาชื่นชอบร้องเพลงเพลงโปรดของพวกเขา
Showcase: https://www.youtube.com/watch?v=2QZUE4WM7CM
คู่มือการตั้งค่า: https://www.youtube.com/watch?v=PDLHK4VVHQK
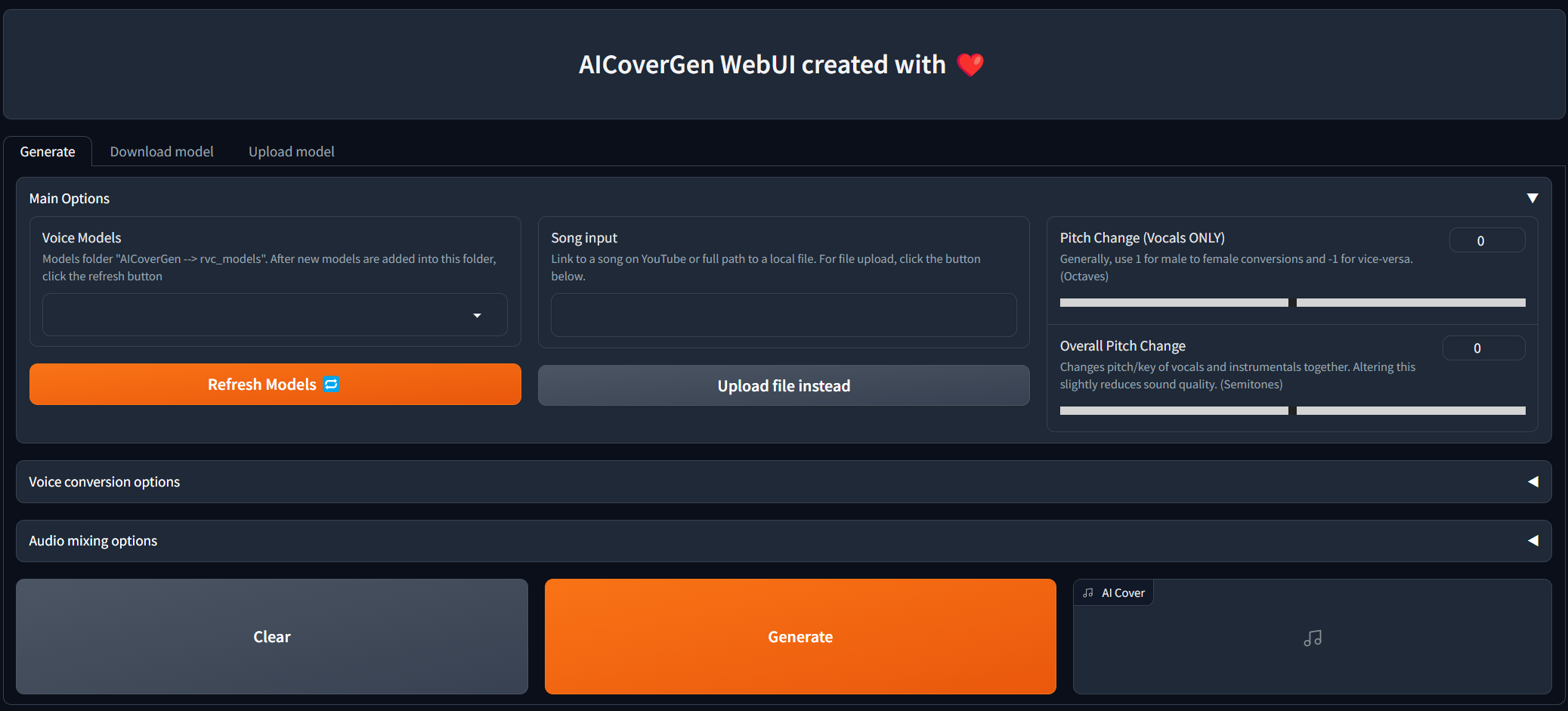
Webui อยู่ระหว่างการพัฒนาและการทดสอบอย่างต่อเนื่อง แต่คุณสามารถลองใช้งานได้ทั้งในท้องถิ่นและ colab!
ติดตั้งและดึงข้อกำหนดใหม่และการเปลี่ยนแปลงใด ๆ โดยการเปิดหน้าต่างบรรทัดคำสั่งในไดเรกทอรี AICoverGen และเรียกใช้คำสั่งต่อไปนี้
pip install -r requirements.txt
git pull
สำหรับผู้ใช้ Colab เพียงคลิก Runtime ในแถบการนำทางด้านบนของโน้ตบุ๊ก colab และ Disconnect and delete runtime ในเมนูดรอปดาวน์ จากนั้นทำตามคำแนะนำในสมุดบันทึกเพื่อเรียกใช้ WebUI
สำหรับผู้ที่ไม่มี Nvidia GPU ที่ทรงพลังพอคุณอาจลองใช้ Aicovergen โดยใช้ Google Colab
สำหรับผู้ที่ประสบปัญหาเกี่ยวกับสมุดบันทึก Google Colab ที่ตัดการเชื่อมต่อหลังจากผ่านไปสองสามนาทีต่อไปนี้เป็นทางเลือกที่ไม่ได้ใช้ WebUI
สำหรับผู้ที่ต้องการเรียกใช้งานนี้ให้ทำตามคู่มือการตั้งค่าด้านล่าง
ทำตามคำแนะนำที่นี่เพื่อติดตั้ง Git บนคอมพิวเตอร์ของคุณ ทำตามคู่มือนี้เพื่อติดตั้ง Python เวอร์ชัน 3.9 หากคุณยังไม่ได้ทำ การใช้ Python รุ่นอื่นอาจส่งผลให้เกิดความขัดแย้งในการพึ่งพา
ทำตามคำแนะนำที่นี่เพื่อติดตั้ง FFMPEG บนคอมพิวเตอร์ของคุณ
ทำตามคำแนะนำที่นี่เพื่อติดตั้ง SOX และเพิ่มลงในสภาพแวดล้อม Windows Path ของคุณ
เปิดหน้าต่างบรรทัดคำสั่งและเรียกใช้คำสั่งเหล่านี้เพื่อโคลนที่เก็บทั้งหมดนี้และติดตั้งการอ้างอิงเพิ่มเติมที่จำเป็น
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
เรียกใช้คำสั่งต่อไปนี้เพื่อดาวน์โหลดโมเดลการแยกเสียง MDXNet ที่ต้องการและโมเดลฐาน Hubert
python src/download_models.py
ในการเรียกใช้ Aicovergen WebUI ให้เรียกใช้คำสั่งต่อไปนี้
python src/webui.py
| ธง | คำอธิบาย |
|---|---|
-h , --help | แสดงข้อความความช่วยเหลือนี้และออก |
--share | สร้าง URL สาธารณะ สิ่งนี้มีประโยชน์สำหรับการเรียกใช้เว็บ UI บน Google Colab |
--listen | ทำให้เว็บ UI เข้าถึงได้จากเครือข่ายท้องถิ่นของคุณ |
--listen-host LISTEN_HOST | ชื่อโฮสต์ที่เซิร์ฟเวอร์จะใช้ |
--listen-port LISTEN_PORT | พอร์ตการฟังที่เซิร์ฟเวอร์จะใช้ |
เมื่อข้อความผลลัพธ์ต่อไปนี้ Running on local URL: http://127.0.0.1:7860 ปรากฏขึ้นคุณสามารถคลิกที่ลิงค์เพื่อเปิดแท็บด้วย webui
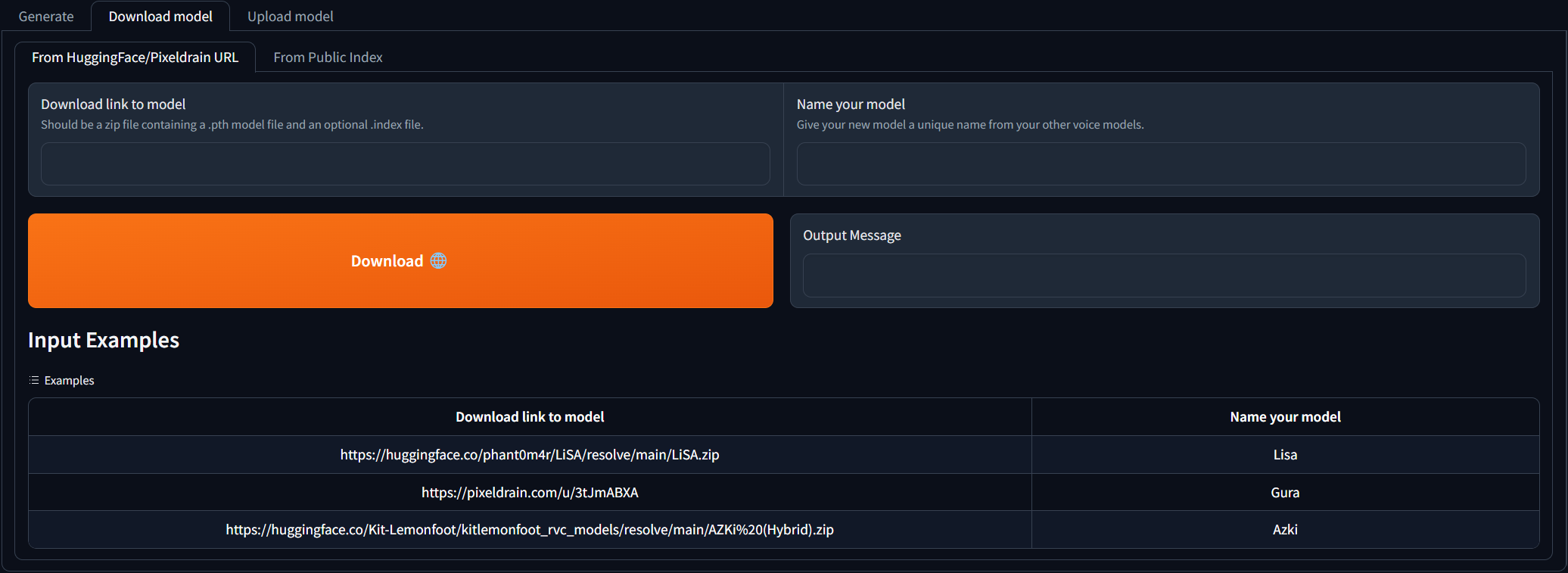
นำทางไปยังแท็บ Download model และวางลิงค์ดาวน์โหลดไปยังรุ่น RVC และให้ชื่อที่ไม่ซ้ำกัน คุณสามารถค้นหาความไม่ลงรอยกันของ AI Hub ที่มีการดาวน์โหลดแบบจำลองเสียงที่ได้รับการฝึกฝนแล้ว คุณอาจอ้างถึงตัวอย่างว่าลิงค์ดาวน์โหลดควรมีลักษณะอย่างไร ไฟล์ zip ที่ดาวน์โหลดควรมีไฟล์. pth model และไฟล์. index เป็นตัวเลือก
เมื่อฟิลด์อินพุต 2 กรอกข้อมูลเพียงคลิก Download ! เมื่อข้อความเอาต์พุตบอกว่า [NAME] Model successfully downloaded! คุณควรจะสามารถใช้ในแท็บ Generate หลังจากคลิกปุ่มรีเฟรชรุ่น!
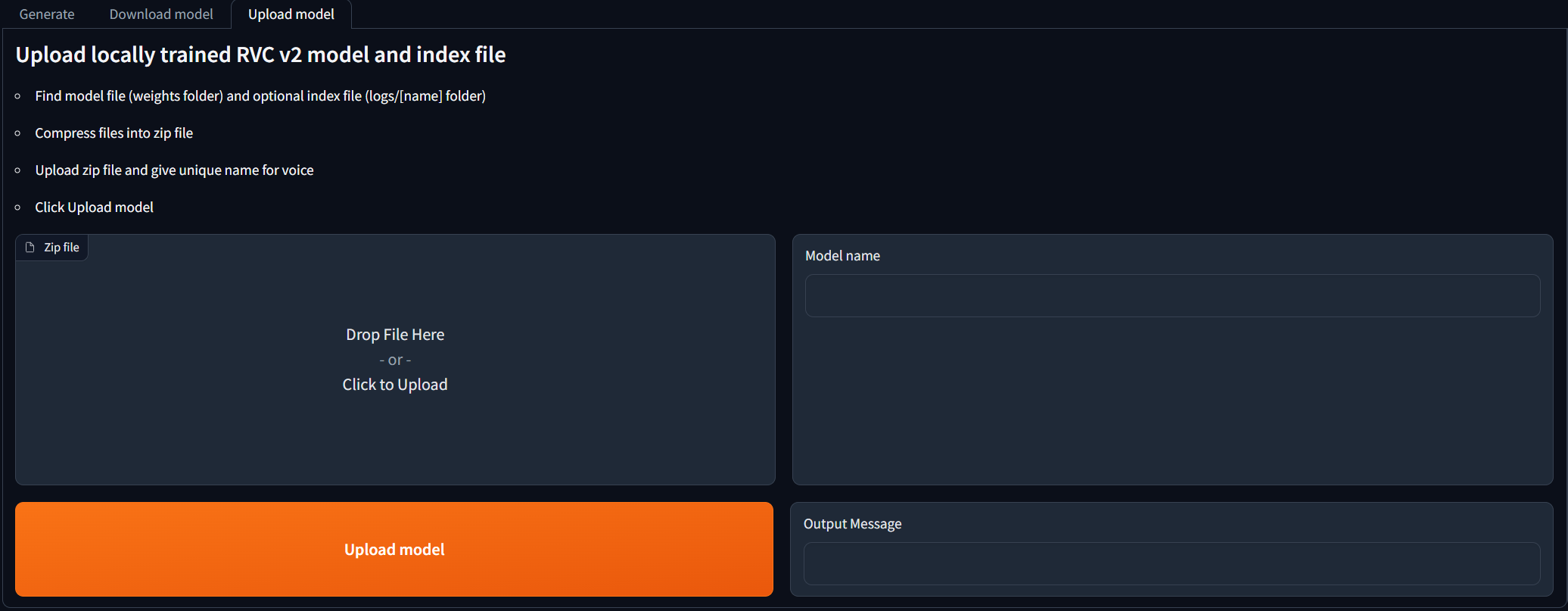
สำหรับผู้ที่ได้รับการฝึกฝนแบบจำลอง RVC V2 ในพื้นที่และต้องการใช้พวกเขาสำหรับ AI Cover Generations นำทางไปยังแท็บ Upload model และทำตามคำแนะนำ เมื่อข้อความเอาต์พุตบอกว่า [NAME] Model successfully uploaded! คุณควรจะสามารถใช้ในแท็บ Generate หลังจากคลิกปุ่มรีเฟรชรุ่น!
Update หากคุณเพิ่มไฟล์ด้วยตนเองลงในไดเรกทอรี RVC_Models เพื่อรีเฟรชรายการ เมื่อตัวเลือกหลักทั้งหมดกรอกข้อมูลคลิก Generate และฝาครอบ AI ที่สร้างขึ้นควรปรากฏในเวลาน้อยกว่าสองสามนาทีขึ้นอยู่กับ GPU ของคุณ
คลายซิป (ถ้าจำเป็น) และถ่ายโอนไฟล์ .pth และ .index ไปยังโฟลเดอร์ใหม่ในไดเรกทอรี RVC_Models แต่ละโฟลเดอร์ควรมี .pth และหนึ่งไฟล์ .index หนึ่งไฟล์
โครงสร้างไดเรกทอรีควรมีลักษณะเช่นนี้:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
ในการเรียกใช้ไปป์ไลน์การสร้างปก AI โดยใช้บรรทัดคำสั่งให้เรียกใช้คำสั่งต่อไปนี้
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| ธง | คำอธิบาย |
|---|---|
-h , --help | แสดงข้อความความช่วยเหลือนี้และออก |
-i SONG_INPUT | ลิงก์ไปยังเพลงบน YouTube หรือ Path ไปยังไฟล์เสียงท้องถิ่น ควรปิดล้อมในราคาสองเท่าสำหรับ Windows และคำพูดเดี่ยวสำหรับระบบที่มีลักษณะคล้าย UNIX |
-dir MODEL_DIR_NAME | ชื่อของโฟลเดอร์ในไดเรกทอรี RVC_Models ที่มีไฟล์ .pth และ .index ของคุณสำหรับเสียงเฉพาะ |
-p PITCH_CHANGE | เปลี่ยนระยะห่างของเสียงร้อง AI ใน Octaves ตั้งค่าเป็น 0 โดยไม่มีการเปลี่ยนแปลง โดยทั่วไปให้ใช้ 1 สำหรับการแปลงเพศชายเป็นหญิงและ -1 สำหรับในทางกลับกัน |
-k | ไม่จำเป็น. สามารถเพิ่มเพื่อให้ไฟล์เสียงระดับกลางทั้งหมดสร้างขึ้น เช่นเสียงร้อง/เครื่องดนตรี AI ที่แยกได้ ออกไปเพื่อประหยัดพื้นที่ |
-ir INDEX_RATE | ไม่จำเป็น. ค่าเริ่มต้น 0.5 ควบคุมสำเนียง AI ที่จะทิ้งไว้ในเสียงร้องมากน้อยเพียงใด 0 <= index_rate <= 1 |
-fr FILTER_RADIUS | ไม่จำเป็น. ค่าเริ่มต้น 3. ถ้า> = 3: ใช้การกรองค่ามัธยฐานการกรองค่ามัธยฐานกับผลการเก็บเกี่ยว 0 <= filter_radius <= 7 |
-rms RMS_MIX_RATE | ไม่จำเป็น. ค่าเริ่มต้น 0.25 ควบคุมจำนวนเสียงร้องของเสียงร้องดั้งเดิม (0) หรือความดังคงที่ (1) 0 <= RMS_MIX_RATE <= 1 |
-palgo PITCH_DETECTION_ALGO | ไม่จำเป็น. ค่าเริ่มต้น RMVPE ตัวเลือกที่ดีที่สุดคือ RMVPE (ความชัดเจนในเสียงร้อง) จากนั้น Mangio-Crepe (เสียงร้องที่ราบรื่นขึ้น) |
-hop CREPE_HOP_LENGTH | ไม่จำเป็น. ค่าเริ่มต้น 128. ควบคุมความถี่ตรวจสอบการเปลี่ยนแปลงระดับเสียงในมิลลิวินาทีเมื่อใช้ Mangio-crepe Algo โดยเฉพาะ ค่าที่ต่ำกว่านำไปสู่การแปลงที่ยาวนานขึ้นและความเสี่ยงที่สูงขึ้นของการแตกเสียง แต่ความแม่นยำระดับเสียงที่ดีกว่า |
-pro PROTECT | ไม่จำเป็น. ค่าเริ่มต้น 0.33 ควบคุมลมหายใจของเสียงร้องดั้งเดิมและพยัญชนะที่ไม่มีเสียงที่จะออกไปในเสียงร้องของ AI ตั้งค่า 0.5 เพื่อปิดการใช้งาน 0 <= ป้องกัน <= 0.5 |
-mv MAIN_VOCALS_VOLUME_CHANGE | ไม่จำเป็น. ค่าเริ่มต้น 0. ปริมาณการควบคุมของนักร้อง AI หลัก ใช้ -3 เพื่อลดระดับเสียงลง 3 เดซิเบลหรือ 3 เพื่อเพิ่มระดับเสียง 3 เดซิเบล |
-bv BACKUP_VOCALS_VOLUME_CHANGE | ไม่จำเป็น. ค่าเริ่มต้น 0. ปริมาณการควบคุมของเสียงร้องสำรอง AI |
-iv INSTRUMENTAL_VOLUME_CHANGE | ไม่จำเป็น. ค่าเริ่มต้น 0. ปริมาณการควบคุมของเพลง/เครื่องมือพื้นหลัง |
-pall PITCH_CHANGE_ALL | ไม่จำเป็น. ค่าเริ่มต้น 0. เปลี่ยนสนาม/คีย์ของเพลงพื้นหลังเสียงร้องสำรองและเสียงร้อง AI ใน semitones ลดคุณภาพเสียงเล็กน้อย |
-rsize REVERB_SIZE | ไม่จำเป็น. ค่าเริ่มต้น 0.15 ยิ่งห้องมีขนาดใหญ่ขึ้นเท่าไหร่เวลาก้องก็นานขึ้น 0 <= reverb_size <= 1 |
-rwet REVERB_WETNESS | ไม่จำเป็น. ค่าเริ่มต้น 0.2 ระดับของนักร้อง AI กับเสียงสะท้อน 0 <= reverb_wetness <= 1 |
-rdry REVERB_DRYNESS | ไม่จำเป็น. ค่าเริ่มต้น 0.8 ระดับของนักร้อง AI ที่ไม่มีเสียงสะท้อน 0 <= reverb_dryness <= 1 |
-rdamp REVERB_DAMPING | ไม่จำเป็น. ค่าเริ่มต้น 0.7. การดูดซับความถี่สูงในพัดโบก 0 <= reverb_damping <= 1 |
-oformat OUTPUT_FORMAT | ไม่จำเป็น. เริ่มต้น mp3. WAV สำหรับคุณภาพที่ดีที่สุดและขนาดไฟล์ขนาดใหญ่ mp3 สำหรับคุณภาพที่เหมาะสมและขนาดไฟล์ขนาดเล็ก |
ห้ามใช้เสียงที่แปลงแล้วเพื่อจุดประสงค์ต่อไปนี้
วิพากษ์วิจารณ์หรือโจมตีบุคคล
การสนับสนุนหรือคัดค้านตำแหน่งทางการเมืองศาสนาหรืออุดมการณ์ที่เฉพาะเจาะจง
แสดงการแสดงออกที่กระตุ้นอย่างมากต่อสาธารณะโดยไม่ต้องแบ่งเขตที่เหมาะสม
การขายโมเดลเสียงและคลิปเสียงที่สร้างขึ้น
การแอบอ้างตัวตนของเจ้าของเสียงดั้งเดิมด้วยความตั้งใจที่เป็นอันตรายที่จะทำร้าย/ทำร้ายผู้อื่น
วัตถุประสงค์ในการฉ้อโกงที่นำไปสู่การขโมยข้อมูลประจำตัวหรือโทรศัพท์ที่ฉ้อโกง
ฉันไม่ต้องรับผิดชอบต่อความเสียหายทางตรงทางอ้อมผลสืบเนื่องหรือความเสียหายพิเศษที่เกิดขึ้นจากหรือในทางที่เชื่อมต่อกับการใช้/การใช้ในทางที่ผิดหรือไม่สามารถใช้ซอฟต์แวร์นี้ได้


