AICoverGen
1.0.0
Eine autonome Pipeline zum Erstellen von Covers mit allen RVC V2 -geschulten AI -Stimme von YouTube -Videos oder einer lokalen Audiodatei. Für Entwickler, die möglicherweise einen Gesangsfunktionalität in ihren KI -Assistenten/Chatbot/VTuber hinzufügen möchten, oder für Leute, die ihre Lieblingsfiguren ihr Lieblingslied singen hören möchten.
Showcase: https://www.youtube.com/watch?v=2qzuy4wm7cm
SETUP -Handbuch: https://www.youtube.com/watch?v=pdlhk4vvhqk
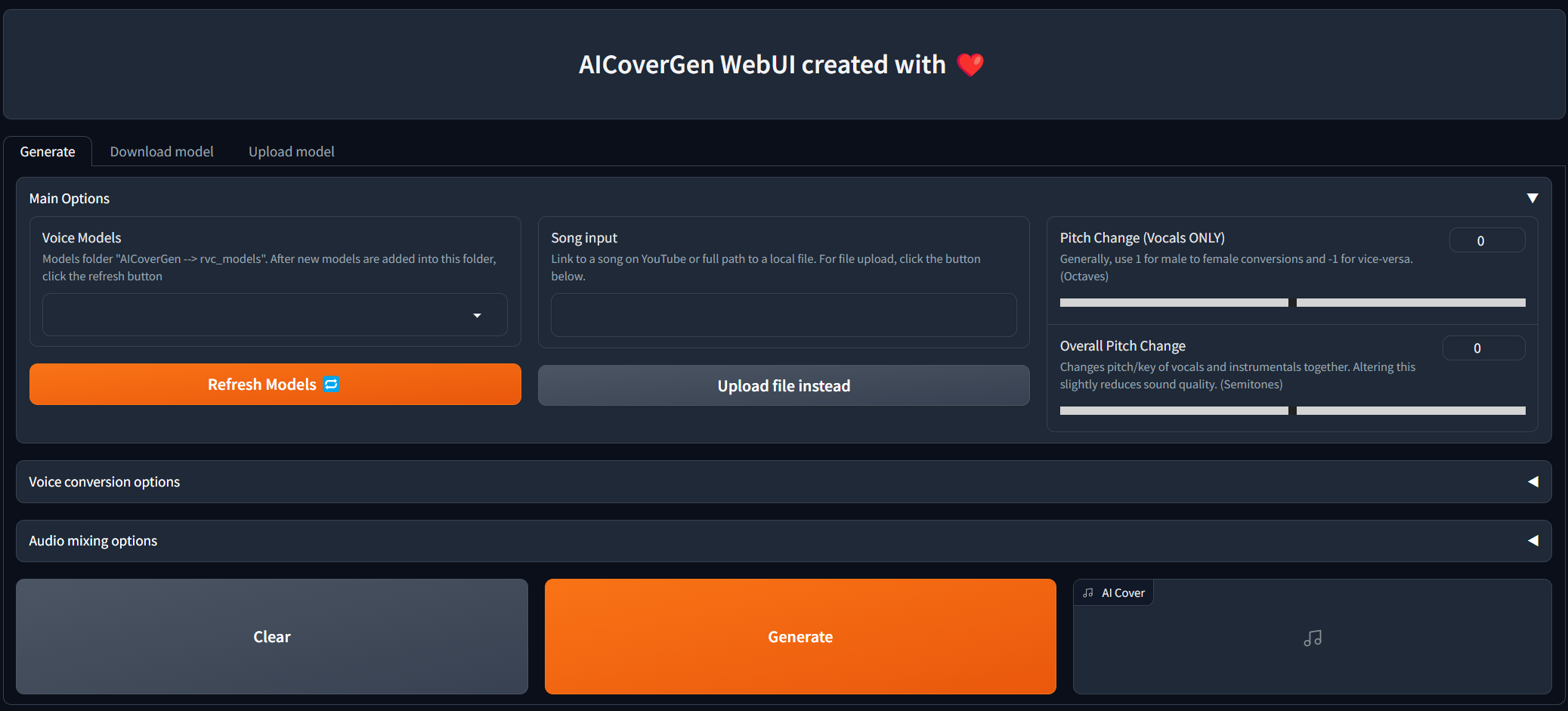
Webui befindet sich in ständiger Entwicklung und Tests, aber Sie können es jetzt sowohl auf lokaler als auch auf Colab ausprobieren!
Installieren und ziehen Sie neue Anforderungen und Änderungen durch, indem Sie ein Befehlszeilenfenster im AICoverGen -Verzeichnis öffnen und die folgenden Befehle ausführen.
pip install -r requirements.txt
git pull
Für Colab -Benutzer klicken Sie einfach Runtime in der oberen Navigationsleiste des Colab -Notizbuchs und Disconnect and delete runtime . Befolgen Sie dann die Anweisungen im Notebook, um das Webui auszuführen.
Für diejenigen ohne eine mächtige Nvidia -GPU können Sie Aicovergen mit Google Colab ausprobieren.
Für diejenigen, die Probleme mit Google Colab Notebook haben, die sich nach wenigen Minuten trennen, ist hier eine Alternative, bei der das Webui nicht verwendet wird.
Für diejenigen, die dies lokal ausführen möchten, folgen Sie der folgenden Setup -Handbuch.
Befolgen Sie die Anweisungen hier, um Git auf Ihrem Computer zu installieren. Folgen Sie dieser Anleitung auch, um die Python Version 3.9 zu installieren, wenn Sie es noch nicht getan haben. Die Verwendung anderer Versionen von Python kann zu Abhängigkeitskonflikten führen.
Befolgen Sie die Anweisungen hier, um FFMPEG auf Ihrem Computer zu installieren.
Befolgen Sie die Anweisungen hier, um SOX zu installieren, und fügen Sie sie Ihrer Windows -Path -Umgebung hinzu.
Öffnen Sie ein Befehlszeilenfenster und führen Sie diese Befehle aus, um das gesamte Repository zu klonen und die zusätzlichen Abhängigkeiten zu installieren.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
Führen Sie den folgenden Befehl aus, um die erforderlichen MDXNET Vocal Separationsmodelle und das Hubert -Basismodell herunterzuladen.
python src/download_models.py
Führen Sie den folgenden Befehl aus.
python src/webui.py
| Flagge | Beschreibung |
|---|---|
-h , --help | Zeigen Sie diese Hilfsnachricht und Beenden Sie. |
--share | Erstellen Sie eine öffentliche URL. Dies ist nützlich, um die Web -Benutzeroberfläche auf Google Colab auszuführen. |
--listen | Machen Sie die Web -Benutzeroberfläche von Ihrem lokalen Netzwerk erreichbar. |
--listen-host LISTEN_HOST | Der Hostname, den der Server verwendet. |
--listen-port LISTEN_PORT | Der Hörport, den der Server verwendet. |
Sobald die folgende Ausgabenachricht Running on local URL: http://127.0.0.1:7860 , können Sie auf den Link klicken, um eine Registerkarte mit dem Webui zu öffnen.
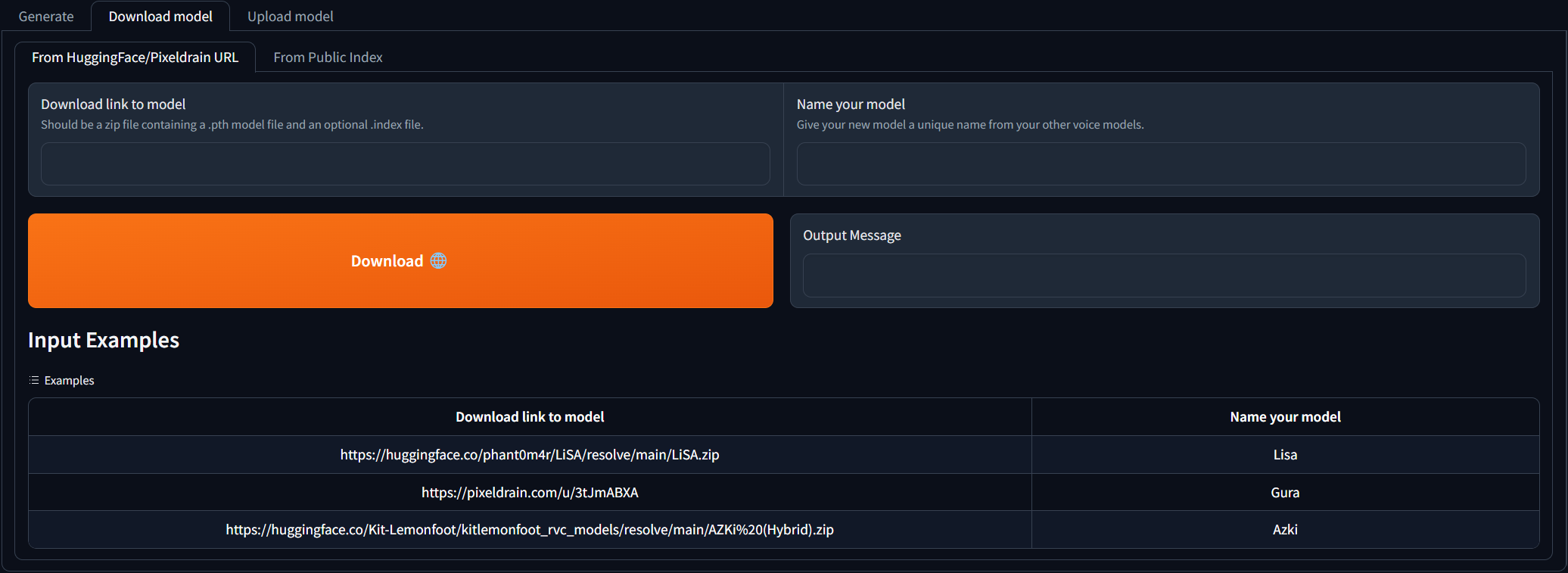
Navigieren Sie zur Registerkarte Download model und fügen Sie den Download -Link zum RVC -Modell ein und geben Sie ihm einen eindeutigen Namen. Sie können die AI Hub Discord durchsuchen, in der bereits geschulte Sprachmodelle zum Download zur Verfügung stehen. Sie können sich auf die Beispiele verweisen, wie der Download -Link aussehen sollte. Die heruntergeladene ZIP -Datei sollte die .PTH -Modelldatei und eine optionale .Index -Datei enthalten.
Sobald die 2 Eingabefelder ausgefüllt sind, klicken Sie einfach auf Download ! Sobald die Ausgabemeldung das [NAME] Model successfully downloaded! Sie sollten in der Lage sein, es auf der Registerkarte Generate zu verwenden, nachdem Sie auf die Schaltfläche "Aktualisierungsmodelle" geklickt haben!
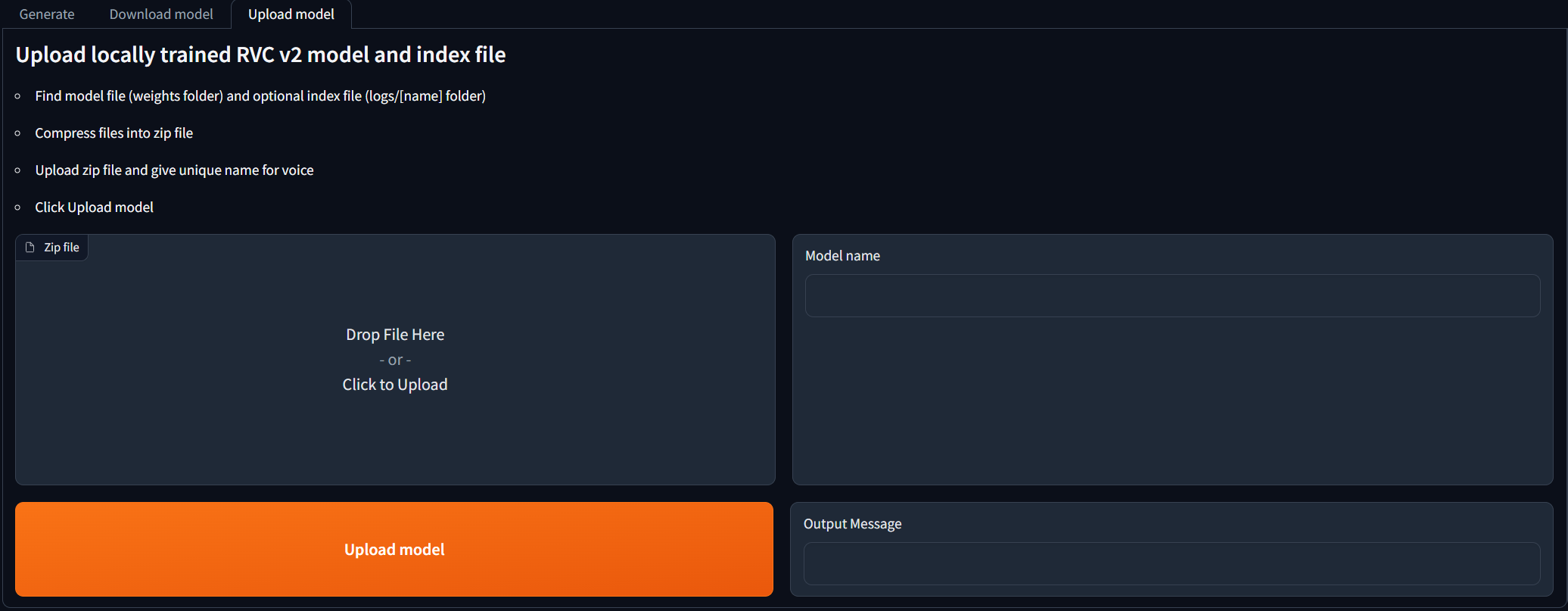
Für Menschen, die RVC V2 -Modelle lokal ausgebildet haben und sie für KI -Deckungsgenerationen verwenden möchten. Navigieren Sie zur Registerkarte Upload model und befolgen Sie die Anweisungen. Sobald die Ausgabemeldung das [NAME] Model successfully uploaded! Sie sollten in der Lage sein, es auf der Registerkarte Generate zu verwenden, nachdem Sie auf die Schaltfläche "Aktualisierungsmodelle" geklickt haben!
Update , wenn Sie die Dateien manuell zum Verzeichnis rvc_models hinzufügen, um die Liste zu aktualisieren. Sobald alle Hauptoptionen ausgefüllt sind, klicken Sie auf Generate , und die KI erzeugte Abdeckung sollte je nach GPU in weniger als wenigen Minuten angezeigt werden.
Unzipp (falls erforderlich) und übertragen Sie die Dateien .pth und .index in einen neuen Ordner im Verzeichnis rvc_models. Jeder Ordner sollte nur eine .pth und eine .index -Datei enthalten.
Die Verzeichnisstruktur sollte ungefähr so aussehen:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
Führen Sie den folgenden Befehl aus.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| Flagge | Beschreibung |
|---|---|
-h , --help | Zeigen Sie diese Hilfsnachricht und Beenden Sie. |
-i SONG_INPUT | Link zu einem Song auf YouTube oder Pfad zu einer lokalen Audio -Datei. Sollte in doppelten Zitaten für Windows und einzelne Zitate für Unix-ähnliche Systeme eingeschlossen sein. |
-dir MODEL_DIR_NAME | Name des Ordners im Verzeichnis rvc_models, das Ihre .pth und .index -Dateien für eine bestimmte Stimme enthält. |
-p PITCH_CHANGE | Ändern Sie die Tonhöhe des AI -Vocals in Oktaven. Für keine Änderung auf 0 einstellen. Verwenden Sie im Allgemeinen 1 für männliche bis weibliche Umbauten und -1 für umgekehrt. |
-k | Optional. Kann hinzugefügt werden, um alle intermediären Audiodateien zu halten. zB isolierte AI -Vocals/Instrumentals. Lassen Sie weg, um Platz zu sparen. |
-ir INDEX_RATE | Optional. Standard 0,5. Kontrollieren Sie, wie viel der Akzent der KI in den Gesang zurücklässt. 0 <= index_rate <= 1. |
-fr FILTER_RADIUS | Optional. Standardwerte 3. IF> = 3: MEDIAN FILTERING MEDIAN -FILTERING AUF DIE ERGEBTETEN PITGE ERGEBNISSE. 0 <= filter_radius <= 7. |
-rms RMS_MIX_RATE | Optional. Standard 0,25. Steuern Sie, wie viel die Lautstärke (0) oder eine feste Lautstärke (1) verwenden soll. 0 <= rms_mix_rate <= 1. |
-palgo PITCH_DETECTION_ALGO | Optional. Standard RMVPE. Die beste Option ist RMVPE (Klarheit im Gesang), dann Mangio-Crepe (glatterer Gesang). |
-hop CREPE_HOP_LENGTH | Optional. Standard 128. steuert, wie oft es auf Pitch-Änderungen in Millisekunden bei der Verwendung von Mangio-Crepe Algo überprüft wird. Niedrigere Werte führen zu längeren Umbauten und einem höheren Risiko für Sprachrisse, aber eine bessere Tonhöhengenauigkeit. |
-pro PROTECT | Optional. Standard 0,33. Kontrollieren Sie, wie viel von dem Atem des ursprünglichen Gesangs und der stimmlosen Konsonanten im KI -Gesang zurücklassen. Stellen Sie 0,5 ein, um zu deaktivieren. 0 <= Protect <= 0,5. |
-mv MAIN_VOCALS_VOLUME_CHANGE | Optional. Standard 0. Kontrollvolumen des Haupt -AI -Vocals. Verwenden Sie -3, um das Volumen um 3 Dezibel oder 3 zu verringern, um das Volumen um 3 Dezibel zu erhöhen. |
-bv BACKUP_VOCALS_VOLUME_CHANGE | Optional. Standard 0. Steuervolumen des Backup -AI -Vocals. |
-iv INSTRUMENTAL_VOLUME_CHANGE | Optional. Standard 0. Steuervolumen der Hintergrundmusik/Instrumente. |
-pall PITCH_CHANGE_ALL | Optional. Standard 0. Ändern Sie die Tonhöhe/Schlüssel der Hintergrundmusik, den Backup -Vocals und der AI -Vocals in Semitones. Reduziert die Klangqualität leicht. |
-rsize REVERB_SIZE | Optional. Standard 0,15. Je größer der Raum, desto länger die Hallzeit. 0 <= reverb_size <= 1. |
-rwet REVERB_WETNESS | Optional. Standard 0,2. Niveau des AI -Vocals mit Reverb. 0 <= reverb_wetness <= 1. |
-rdry REVERB_DRYNESS | Optional. Standard 0,8. Niveau des AI -Vocals ohne Hall. 0 <= reverb_dryness <= 1. |
-rdamp REVERB_DAMPING | Optional. Standard 0,7. Absorption hoher Frequenzen im Hall. 0 <= reverb_damping <= 1. |
-oformat OUTPUT_FORMAT | Optional. Standard MP3. WAV für die beste Qualität und große Dateigröße, MP3 für anständige Qualität und kleine Dateigröße. |
Die Verwendung der konvertierten Stimme für folgende Zwecke ist verboten.
Personen kritisieren oder angreifen.
Sich für bestimmte politische Positionen, Religionen oder Ideologien einsetzen oder sich entgegensetzen.
Öffentlich stark stimulierende Ausdrücke ohne ordnungsgemäße Zonierung aufzeigen.
Verkauf von Sprachmodellen und generierten Sprachclips.
Imitation des ursprünglichen Besitzers der Stimme mit böswilligen Absichten, andere zu schaden/zu verletzen.
Betrügerische Zwecke, die zu Identitätsdiebstahl oder betrügerischen Telefonanrufen führen.
Ich haftet nicht für direkte, indirekte, konsequente, zufällige oder besondere Schäden, die sich aus oder in irgendeiner Weise ergeben, die mit der Verwendung/Missbrauch oder der Unfähigkeit, diese Software zu verwenden, verbunden sind.


