AICoverGen
1.0.0
Un pipeline autonome pour créer des couvertures avec toute voix AI formée RVC V2 à partir de vidéos YouTube ou un fichier audio local. Pour les développeurs qui peuvent vouloir ajouter une fonctionnalité de chant à leur assistant / chatbot / vtuber AI, ou pour les personnes qui veulent entendre leurs personnages préférés chanter leur chanson préférée.
Showcase: https://www.youtube.com/watch?v=2qzue4wm7cm
Guide de configuration: https://www.youtube.com/watch?v=pdlhk4vvhqk
WebUI est en cours de développement et de tests constants, mais vous pouvez l'essayer dès maintenant sur local et colab!
Installez et tirez toutes les nouvelles exigences et modifications en ouvrant une fenêtre de ligne de commande dans le répertoire AICoverGen et en exécutant les commandes suivantes.
pip install -r requirements.txt
git pull
Pour les utilisateurs de Colab, cliquez simplement sur Runtime dans la barre de navigation supérieure du cahier Colab et Disconnect and delete runtime dans le menu déroulant. Suivez ensuite les instructions du cahier pour exécuter le webui.
Pour ceux qui n'ont pas un GPU NVIDIA suffisamment puissant, vous pouvez essayer Aicovergen à l'aide de Google Colab.
Pour ceux qui sont confrontés à des problèmes avec Google Colab Notebook déconnectés après quelques minutes, voici une alternative qui n'utilise pas le webui.
Pour ceux qui souhaitent l'exécuter localement, suivez le guide de configuration ci-dessous.
Suivez les instructions ici pour installer GIT sur votre ordinateur. Suivez également ce guide pour installer Python version 3.9 si vous ne l'avez pas déjà fait. L'utilisation d'autres versions de Python peut entraîner des conflits de dépendance.
Suivez les instructions ici pour installer FFMPEG sur votre ordinateur.
Suivez les instructions ici pour installer SOX et ajoutez-la à votre environnement Windows Path.
Ouvrez une fenêtre de ligne de commande et exécutez ces commandes pour cloner tout ce référentiel et installer les dépendances supplémentaires requises.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
Exécutez la commande suivante pour télécharger les modèles de séparation vocale MDXNET requis et le modèle de base Hubert.
python src/download_models.py
Pour exécuter le webui Aicovergen, exécutez la commande suivante.
python src/webui.py
| Drapeau | Description |
|---|---|
-h , --help | Montrez ce message d'aide et sortez. |
--share | Créer une URL publique. Ceci est utile pour exécuter l'interface utilisateur Web sur Google Colab. |
--listen | Rendez l'interface utilisateur Web accessible à partir de votre réseau local. |
--listen-host LISTEN_HOST | Le nom d'hôte que le serveur utilisera. |
--listen-port LISTEN_PORT | Le port d'écoute que le serveur utilisera. |
Une fois le message de sortie suivant Running on local URL: http://127.0.0.1:7860 apparaît, vous pouvez cliquer sur le lien pour ouvrir un onglet avec le webui.
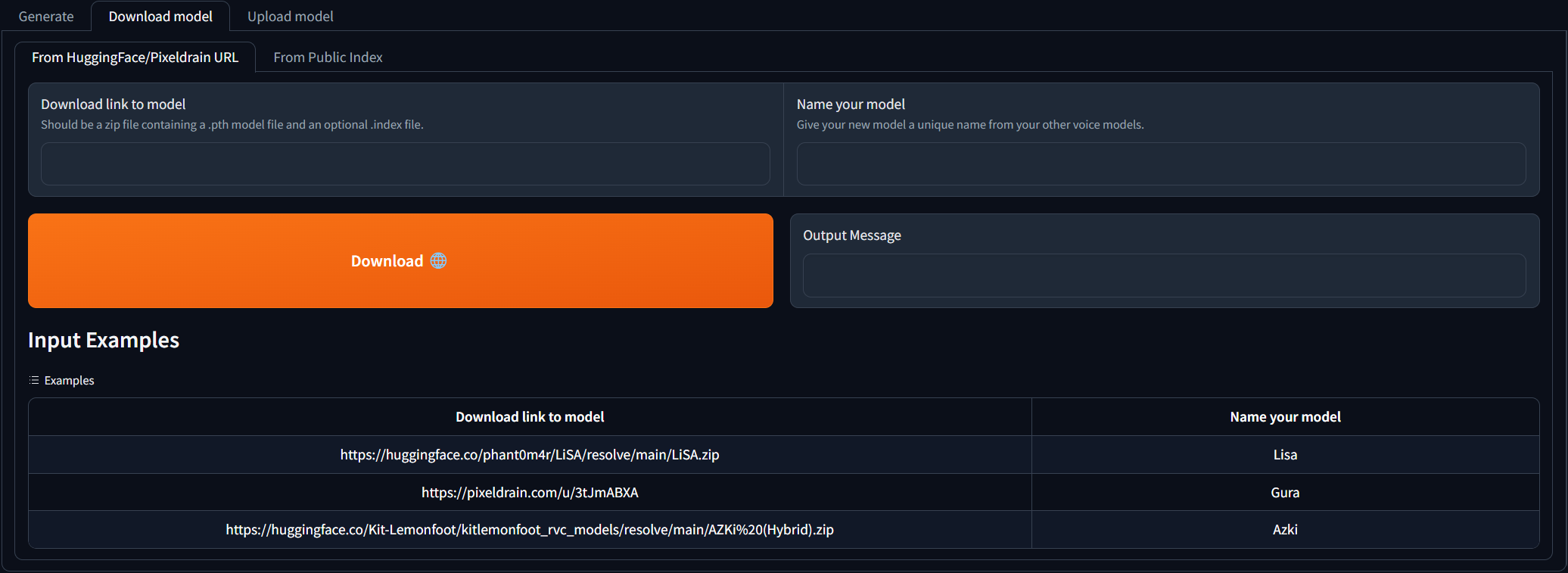
Accédez à l'onglet Download model et collez le lien de téléchargement vers le modèle RVC et donnez-lui un nom unique. Vous pouvez rechercher la discorde AI Hub où des modèles vocaux déjà formés sont disponibles en téléchargement. Vous pouvez vous référer aux exemples pour savoir à quoi devrait ressembler le lien de téléchargement. Le fichier zip téléchargé doit contenir le fichier de modèle .pth et un fichier .Index facultatif.
Une fois les 2 champs d'entrée remplis, cliquez simplement sur Download ! Une fois que le message de sortie indique [NAME] Model successfully downloaded! , vous devriez être en mesure de l'utiliser dans l'onglet Generate après avoir cliqué sur le bouton Rafraîchir les modèles!
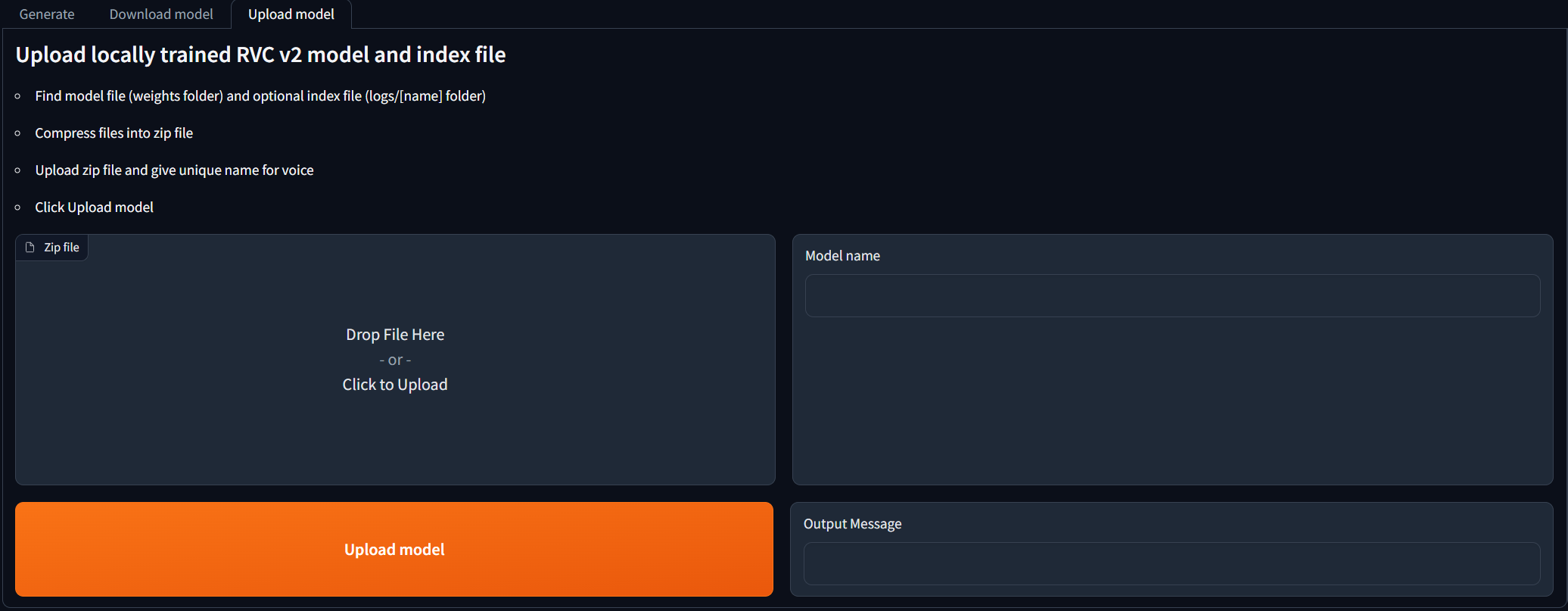
Pour les personnes qui ont formé les modèles RVC V2 localement et qui souhaitent les utiliser pour les générations de couverture de l'IA. Accédez à l'onglet Upload model et suivez les instructions. Une fois que le message de sortie indique [NAME] Model successfully uploaded! , vous devriez être en mesure de l'utiliser dans l'onglet Generate après avoir cliqué sur le bouton Rafraîchir les modèles!
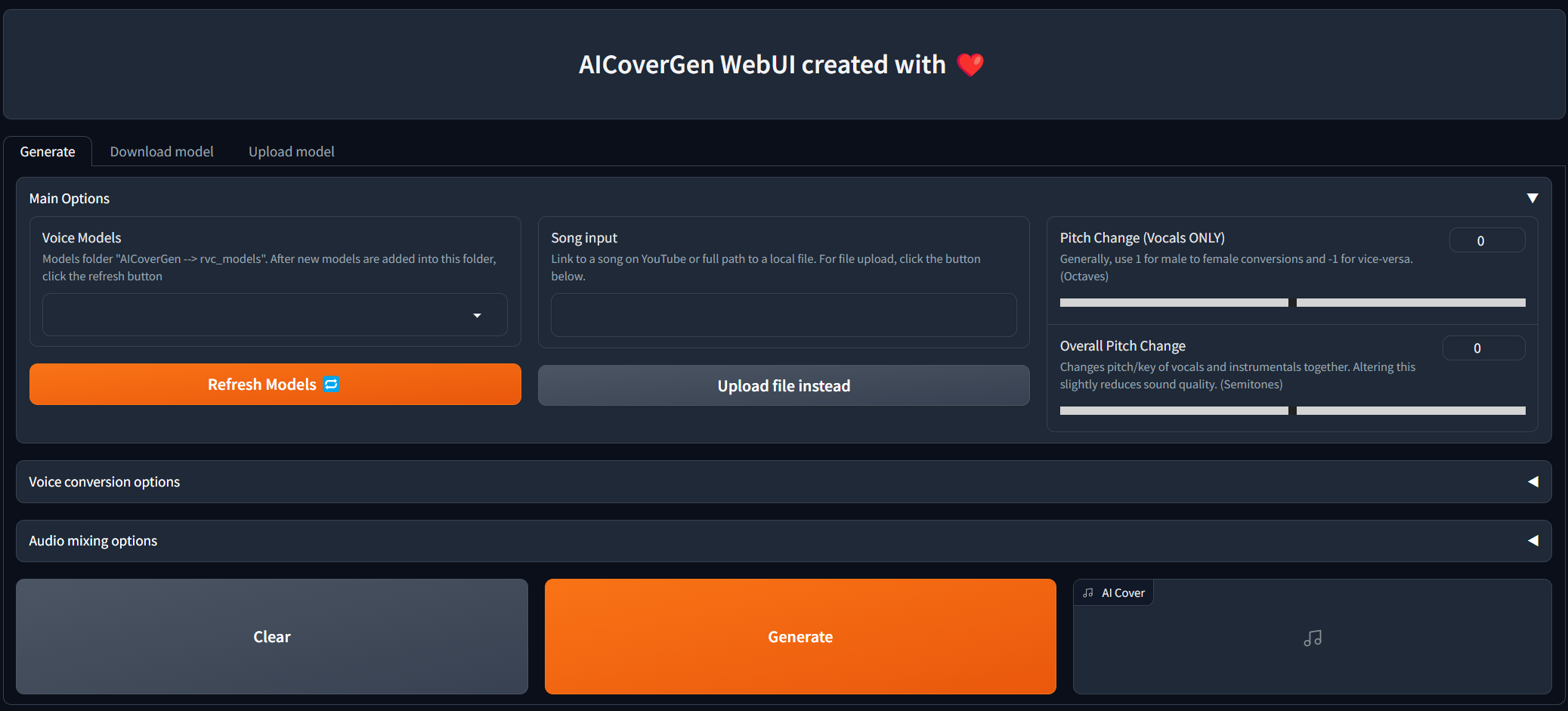
Update si vous avez ajouté les fichiers manuellement au répertoire RVC_Models pour actualiser la liste. Une fois que toutes les options principales sont remplies, cliquez sur Generate et la couverture générée par l'IA doit apparaître en moins de quelques minutes en fonction de votre GPU.
Unzip (si nécessaire) et transférez les fichiers .pth et .index dans un nouveau dossier dans le répertoire RVC_Models. Chaque dossier ne doit contenir qu'un seul fichier .pth et un .index .
La structure du répertoire devrait ressembler à ceci:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
Pour exécuter le pipeline de génération de couverture AI à l'aide de la ligne de commande, exécutez la commande suivante.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| Drapeau | Description |
|---|---|
-h , --help | Montrez ce message d'aide et sortez. |
-i SONG_INPUT | Lien vers une chanson sur YouTube ou chemin vers un fichier audio local. Devrait être enfermé en doubles citations pour Windows et des citations simples pour les systèmes de type UNIX. |
-dir MODEL_DIR_NAME | Nom du dossier dans le répertoire RVC_Models contenant vos fichiers .pth et .index pour une voix spécifique. |
-p PITCH_CHANGE | Changer la hauteur des voix de l'IA dans les octaves. Réglé sur 0 pour aucun changement. Généralement, utilisez 1 pour les conversions masculines à femmes et -1 pour vice-versa. |
-k | Facultatif. Peut être ajouté pour garder tous les fichiers audio intermédiaires générés. Par exemple, les voix / instruments IA isolés. Laisser de côté pour économiser de l'espace. |
-ir INDEX_RATE | Facultatif. Par défaut 0,5. Contrôlez la part de l'accent de l'IA à laisser dans la voix. 0 <= index_rate <= 1. |
-fr FILTER_RADIUS | Facultatif. Par défaut 3. Si> = 3: appliquez le filtrage médian médian au filtrage médian aux résultats de la hauteur récoltée. 0 <= filter_radius <= 7. |
-rms RMS_MIX_RATE | Facultatif. Par défaut 0,25. Contrôlez combien utiliser l'intensité de la voix originale (0) ou une volume fixe (1). 0 <= rms_mix_rate <= 1. |
-palgo PITCH_DETECTION_ALGO | Facultatif. RMVPE par défaut. La meilleure option est RMVPE (clarté dans les voix), puis Mangio-Crepe (voix plus lisses). |
-hop CREPE_HOP_LENGTH | Facultatif. Par défaut 128. Contrôle la fréquence à laquelle il vérifie les modifications de hauteur en millisecondes lors de l'utilisation spécifiquement de l'algo mangio-prépe. Des valeurs plus faibles entraînent des conversions plus longues et un risque plus élevé de fissures vocales, mais une meilleure précision de hauteur. |
-pro PROTECT | Facultatif. Par défaut 0,33. Contrôlez la quantité de voix des voix originales et des consonnes sans voix à quitter dans la voix de l'IA. Réglez 0,5 pour désactiver. 0 <= protéger <= 0,5. |
-mv MAIN_VOCALS_VOLUME_CHANGE | Facultatif. Par défaut 0. Volume de contrôle des voix principales de l'IA. Utilisez -3 pour diminuer le volume de 3 décibels, ou 3 pour augmenter le volume de 3 décibels. |
-bv BACKUP_VOCALS_VOLUME_CHANGE | Facultatif. Par défaut 0. Volume de contrôle des voix de sauvegarde AI. |
-iv INSTRUMENTAL_VOLUME_CHANGE | Facultatif. Par défaut 0. Volume de contrôle de la musique / instrumentaux de fond. |
-pall PITCH_CHANGE_ALL | Facultatif. Par défaut 0. Changer la hauteur / la clé de la musique de fond, les voix de sauvegarde et les voix de l'IA en Semitones. Réduit légèrement la qualité du son. |
-rsize REVERB_SIZE | Facultatif. Par défaut 0,15. Plus la pièce est grande, plus le temps de réverbération est long. 0 <= Reverb_Size <= 1. |
-rwet REVERB_WETNESS | Facultatif. Par défaut 0,2. Niveau de voix de l'IA avec réverbération. 0 <= Reverb_Wetness <= 1. |
-rdry REVERB_DRYNESS | Facultatif. Par défaut 0,8. Niveau des voix de l'IA sans réverbération. 0 <= Reverb_dryness <= 1. |
-rdamp REVERB_DAMPING | Facultatif. Par défaut 0,7. Absorption des hautes fréquences dans la réverbération. 0 <= Reverb_damping <= 1. |
-oformat OUTPUT_FORMAT | Facultatif. Mp3 par défaut. WAV pour la meilleure qualité et la taille grande, MP3 pour une qualité décente et une petite taille de fichier. |
L'utilisation de la voix convertie aux fins suivantes est interdite.
Critiquer ou attaquer des individus.
Plaider ou s'opposer à des positions politiques spécifiques, des religions ou des idéologies.
Affichant publiquement des expressions fortement stimulantes sans zonage approprié.
Vente de modèles vocaux et clips vocaux générés.
Une imitation du propriétaire d'origine de la voix avec des intentions malveillantes de nuire / blesser les autres.
Des objectifs frauduleux qui conduisent à un vol d'identité ou à des appels téléphoniques frauduleux.
Je ne suis pas responsable des dommages directs, indirects, conséquents, accessoires ou spéciaux résultant de ou de quelque manière que ce soit lié à l'utilisation / abus ou à l'incapacité d'utiliser ce logiciel.


