AICoverGen
1.0.0
YouTube 비디오 또는 로컬 오디오 파일에서 RVC V2 교육 AI 음성으로 커버를 생성하는 자율 파이프 라인. AI 어시스턴트/챗봇/vtuber에 노래 기능을 추가하려는 개발자 또는 좋아하는 캐릭터가 좋아하는 노래를 듣고 싶은 사람들을 위해 개발자를 위해.
쇼케이스 : https://www.youtube.com/watch?v=2qzue4wm7cm
설정 가이드 : https://www.youtube.com/watch?v=pdlhk4vvhqk
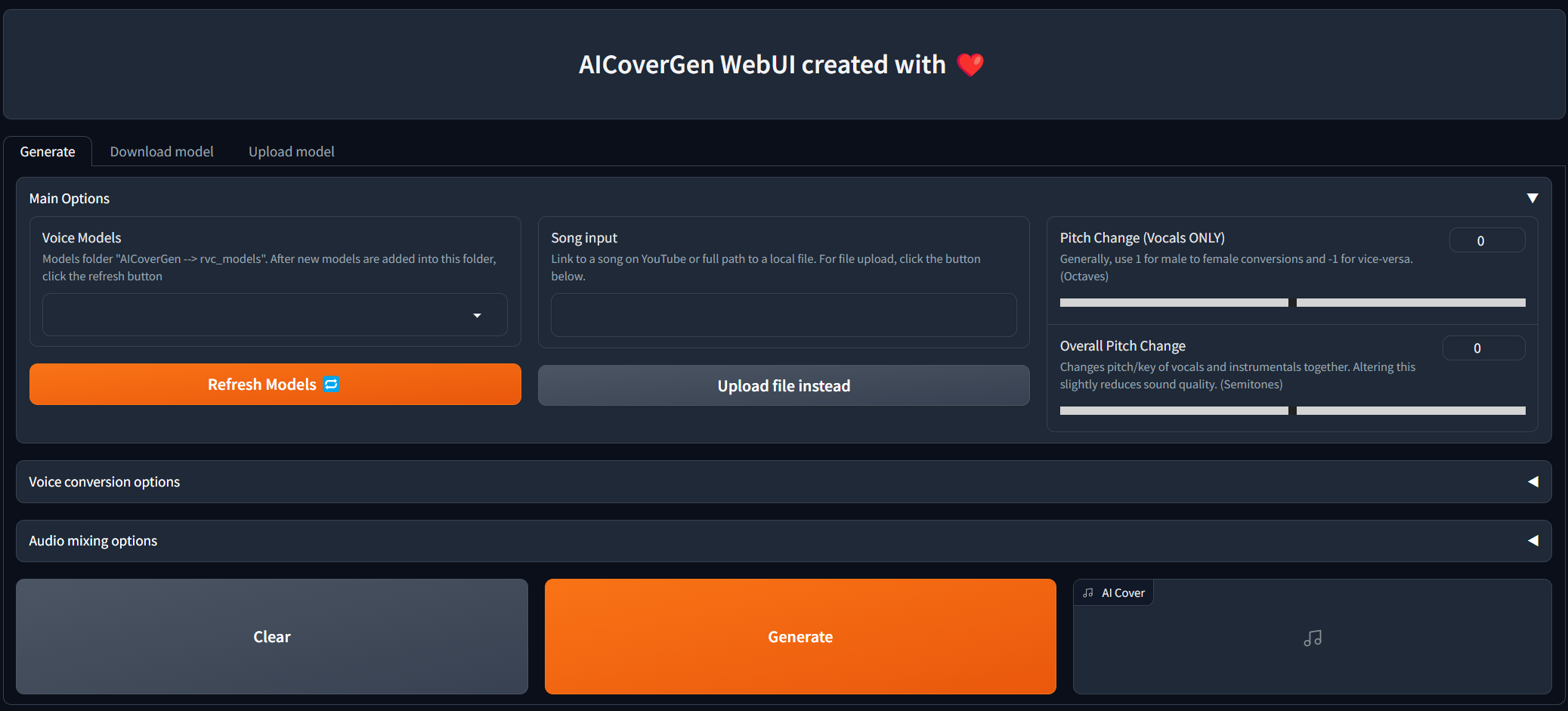
Webui는 끊임없는 개발 및 테스트를 받고 있지만 지금은 지역 및 Colab에서 시도해 볼 수 있습니다!
AICoverGen 디렉토리에서 명령 줄 창을 열고 다음 명령을 실행하여 새로운 요구 사항과 변경 사항을 설치하고 가져옵니다.
pip install -r requirements.txt
git pull
Colab 사용자의 경우 Colab 노트북의 상단 탐색 표시 줄에서 Runtime 클릭하고 드롭 다운 메뉴에서 Disconnect and delete runtime . 그런 다음 노트북의 지침을 따라 WebUI를 실행하십시오.
강력한 NVIDIA GPU가없는 사람들의 경우 Google Colab을 사용하여 AICOVERGEN을 사용해 볼 수 있습니다.
몇 분 후 Google Colab 노트북 연결 문제에 직면 한 사람들의 경우 WebUI를 사용하지 않는 대안이 있습니다.
로컬 로이 실행하려는 사람들은 아래 설정 안내서를 따르십시오.
컴퓨터에 GIT를 설치하려면 여기 지침을 따라하십시오. 또한이 안내서를 따라 Python 버전 3.9를 설치하지 않은 경우 아직 설치하십시오. 다른 버전의 파이썬을 사용하면 의존성 충돌이 발생할 수 있습니다.
컴퓨터에 FFMPEG를 설치하려면 여기에 지침을 따르십시오.
여기에 지침을 따라 SOX를 설치하고 Windows 경로 환경에 추가하십시오.
명령 줄 창을 열고이 명령을 실행 하여이 전체 저장소를 복제하고 필요한 추가 종속성을 설치하십시오.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
다음 명령을 실행하여 필요한 MDXNET 보컬 분리 모델 및 Hubert Base 모델을 다운로드하십시오.
python src/download_models.py
AICOVERGEN WEBUI를 실행하려면 다음 명령을 실행하십시오.
python src/webui.py
| 깃발 | 설명 |
|---|---|
-h , --help | 이 도움말 메시지와 종료를 보여주십시오. |
--share | 공개 URL을 만듭니다. Google Colab에서 웹 UI를 실행하는 데 유용합니다. |
--listen | 로컬 네트워크에서 웹 UI에 도달 할 수 있도록하십시오. |
--listen-host LISTEN_HOST | 서버가 사용할 호스트 이름. |
--listen-port LISTEN_PORT | 서버가 사용할 청취 포트. |
Running on local URL: http://127.0.0.1:7860 나타나면 링크를 클릭하여 webui로 탭을 엽니 다.
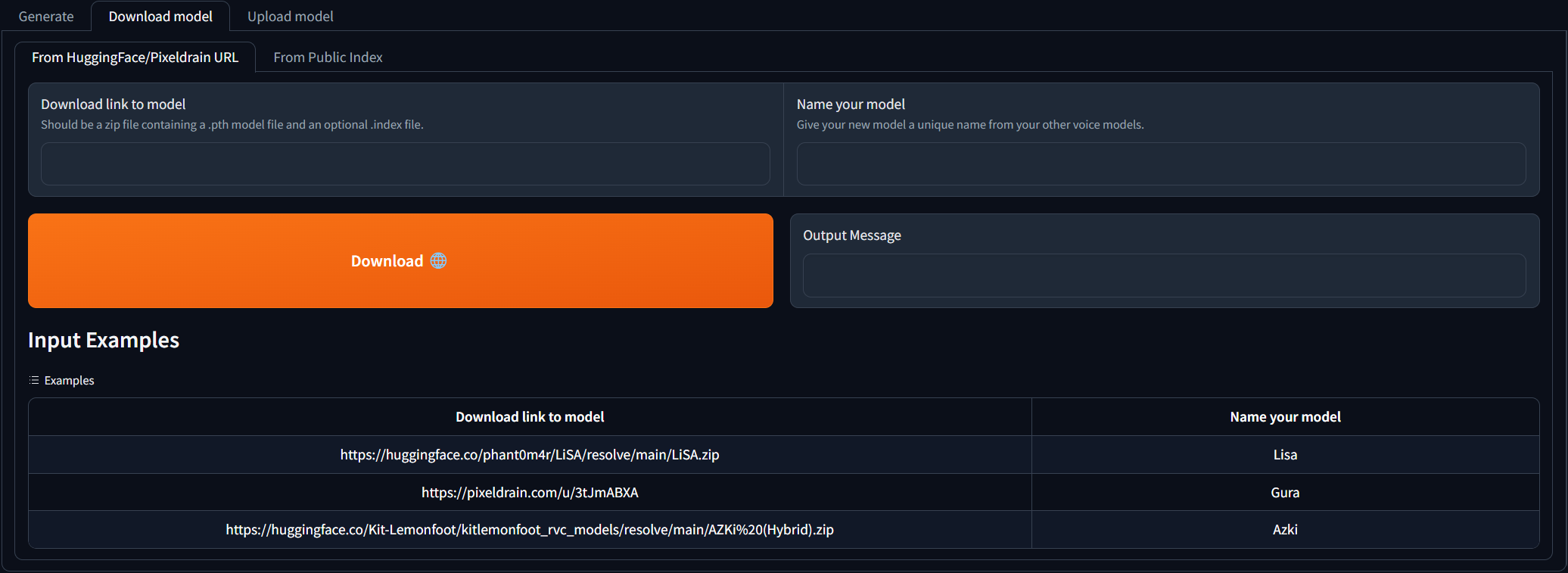
Download model 탭으로 이동하여 다운로드 링크를 RVC 모델에 붙여 넣고 고유 한 이름을 제공하십시오. 이미 훈련 된 음성 모델을 다운로드 할 수있는 AI 허브 불화를 검색 할 수 있습니다. 다운로드 링크가 어떻게 보이는지에 대한 예제를 참조 할 수 있습니다. 다운로드 된 zip 파일에는 .pth 모델 파일과 옵션. 인덱스 파일이 포함되어야합니다.
2 개의 입력 필드가 채워지면 Download 클릭하십시오! 출력 메시지에 [NAME] Model successfully downloaded! 새로 고침 모델 버튼을 클릭 한 후 Generate 탭에서 사용할 수 있어야합니다!
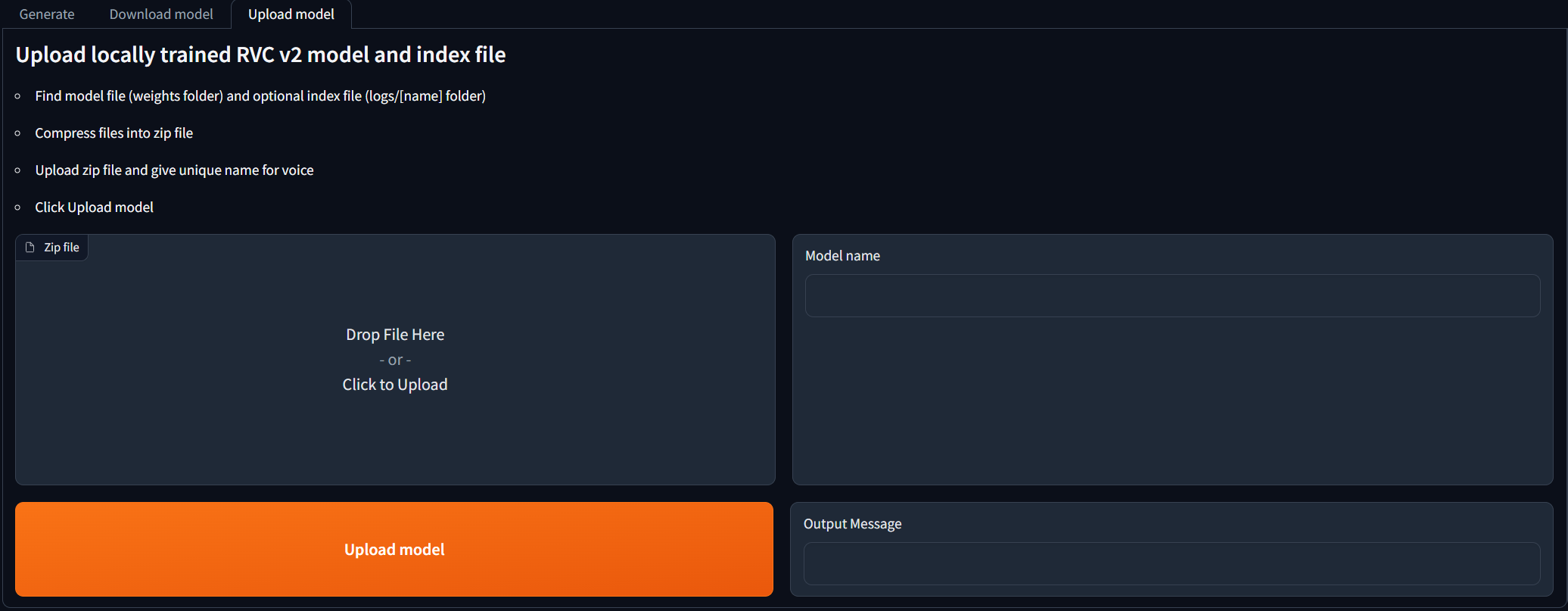
RVC V2 모델을 현지에서 교육하고 AI Cover Generation에 사용하려는 사람들을 위해. Upload model 탭으로 이동하여 지침을 따르십시오. 출력 메시지에 [NAME] Model successfully uploaded! 새로 고침 모델 버튼을 클릭 한 후 Generate 탭에서 사용할 수 있어야합니다!
Update 클릭하십시오. 모든 기본 옵션이 채워지면 Generate 클릭하면 GPU에 따라 AI 생성 커버가 몇 분 안에 나타납니다.
압축 (필요한 경우)을 풀고 .pth 및 .index 파일을 RVC_Models 디렉토리의 새 폴더로 전송하십시오. 각 폴더에는 하나의 .pth 와 하나의 .index 파일 만 포함되어야합니다.
디렉토리 구조는 다음과 같습니다.
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
명령 줄을 사용하여 AI 커버 생성 파이프 라인을 실행하려면 다음 명령을 실행하십시오.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| 깃발 | 설명 |
|---|---|
-h , --help | 이 도움말 메시지와 종료를 보여주십시오. |
-i SONG_INPUT | YouTube의 노래 또는 로컬 오디오 파일로의 링크. Windows 용 이중 인용문과 Unix와 같은 시스템의 단일 따옴표로 둘러싸여 있어야합니다. |
-dir MODEL_DIR_NAME | RVC_Models 디렉토리의 폴더 이름 .pth 및 .index 파일이 포함 된 디렉토리. |
-p PITCH_CHANGE | 옥타브에서 AI 보컬의 피치를 변경하십시오. 변경없이 0으로 설정하십시오. 일반적으로 남성에서 여성 전환의 경우 1을 사용하고 그 반대로 -1을 사용하십시오. |
-k | 선택 과목. 모든 중간 오디오 파일을 생성하기 위해 추가 할 수 있습니다. 예를 들어 고립 된 AI 보컬/악기. 공간을 저장하기 위해 떠나십시오. |
-ir INDEX_RATE | 선택 과목. 기본 0.5. AI의 악센트가 보컬에 남겨 두는 양을 제어하십시오. 0 <= index_rate <= 1. |
-fr FILTER_RADIUS | 선택 과목. 기본값 3. if> = 3 : 수확 된 피치 결과에 중간 필터링 중앙 필터링을 적용하십시오. 0 <= filter_radius <= 7. |
-rms RMS_MIX_RATE | 선택 과목. 기본 0.25. 원래 보컬의 음량 (0) 또는 고정 음량 (1)을 얼마나 사용 해야하는지 제어하십시오. 0 <= rms_mix_rate <= 1. |
-palgo PITCH_DETECTION_ALGO | 선택 과목. 기본 RMVPE. 가장 좋은 옵션은 RMVPE (Clarity in Vocals), Mangio-Crepe (부드러운 보컬)입니다. |
-hop CREPE_HOP_LENGTH | 선택 과목. 기본 128. Mangio-Crepe Algo를 구체적으로 사용할 때 밀리 초의 피치 변경 사항을 얼마나 자주 확인하는지 제어합니다. 값이 낮을수록 전환이 길고 음성 균열의 위험이 높지만 피치 정확도가 향상됩니다. |
-pro PROTECT | 선택 과목. 기본 0.33. AI 보컬에 오리지널 보컬의 호흡과 음성없는 자음의 양을 제어하십시오. 비활성화하려면 0.5를 설정합니다. 0 <= 보호 <= 0.5. |
-mv MAIN_VOCALS_VOLUME_CHANGE | 선택 과목. 기본 0. 메인 AI 보컬의 제어 볼륨. -3을 사용하여 부피를 3 데시벨 또는 3으로 줄이려면 3 데시벨 씩 부피를 증가시킵니다. |
-bv BACKUP_VOCALS_VOLUME_CHANGE | 선택 과목. 기본값 0. 백업 AI 보컬의 제어량. |
-iv INSTRUMENTAL_VOLUME_CHANGE | 선택 과목. 기본 0. 배경 음악/악기의 제어 볼륨. |
-pall PITCH_CHANGE_ALL | 선택 과목. 기본 0. 백그라운드 음악, 백업 보컬 및 AI 보컬의 피치/키를 반입으로 변경하십시오. 음질을 약간 줄입니다. |
-rsize REVERB_SIZE | 선택 과목. 기본 0.15. 방이 클수록 리버브 시간이 길어집니다. 0 <= reverb_size <= 1. |
-rwet REVERB_WETNESS | 선택 과목. 기본 0.2. 리버브가있는 AI 보컬 레벨. 0 <= Reverb_wetness <= 1. |
-rdry REVERB_DRYNESS | 선택 과목. 기본 0.8. 리버브가없는 AI 보컬 레벨. 0 <= Reverb_dryness <= 1. |
-rdamp REVERB_DAMPING | 선택 과목. 기본 0.7. 리버브에서 고주파수의 흡수. 0 <= Reverb_damping <= 1. |
-oformat OUTPUT_FORMAT | 선택 과목. 기본 MP3. 최상의 품질 및 큰 파일 크기, 적절한 품질 및 작은 파일 크기에 대한 MP3를위한 WAV. |
다음 목적으로 변환 된 음성의 사용은 금지됩니다.
개인을 비판하거나 공격합니다.
특정 정치적 지위, 종교 또는 이데올로기를 옹호하거나 반대하는 것.
적절한 구역 설정없이 강력하게 자극적 인 표현을 공개적으로 표시합니다.
음성 모델 판매 및 생성 된 음성 클립.
다른 사람들을 해치거나 상처하려는 악의적 인 의도로 목소리의 원래 소유자를 가장합니다.
신원 도용 또는 사기 전화 통화로 이어지는 사기 목적.
본인은 사용/오용 또는이 소프트웨어를 사용할 수없는 방식으로 또는 어떤 방식 으로든 발생하는 직접, 간접적, 결과적, 부수적 또는 특별한 손해에 대해 책임을지지 않습니다.


