AICoverGen
1.0.0
YouTubeビデオまたはローカルオーディオファイルからRVC V2トレーニングされたAI音声とカバーを作成するための自律パイプライン。 AIアシスタント/チャットボット/vtuberに歌機能を追加したい開発者、またはお気に入りのキャラクターがお気に入りの曲を歌っているのを聞きたい人のために。
ショーケース:https://www.youtube.com/watch?v=2qzue4wm7cm
セットアップガイド:https://www.youtube.com/watch?v=pdlhk4vvhqk
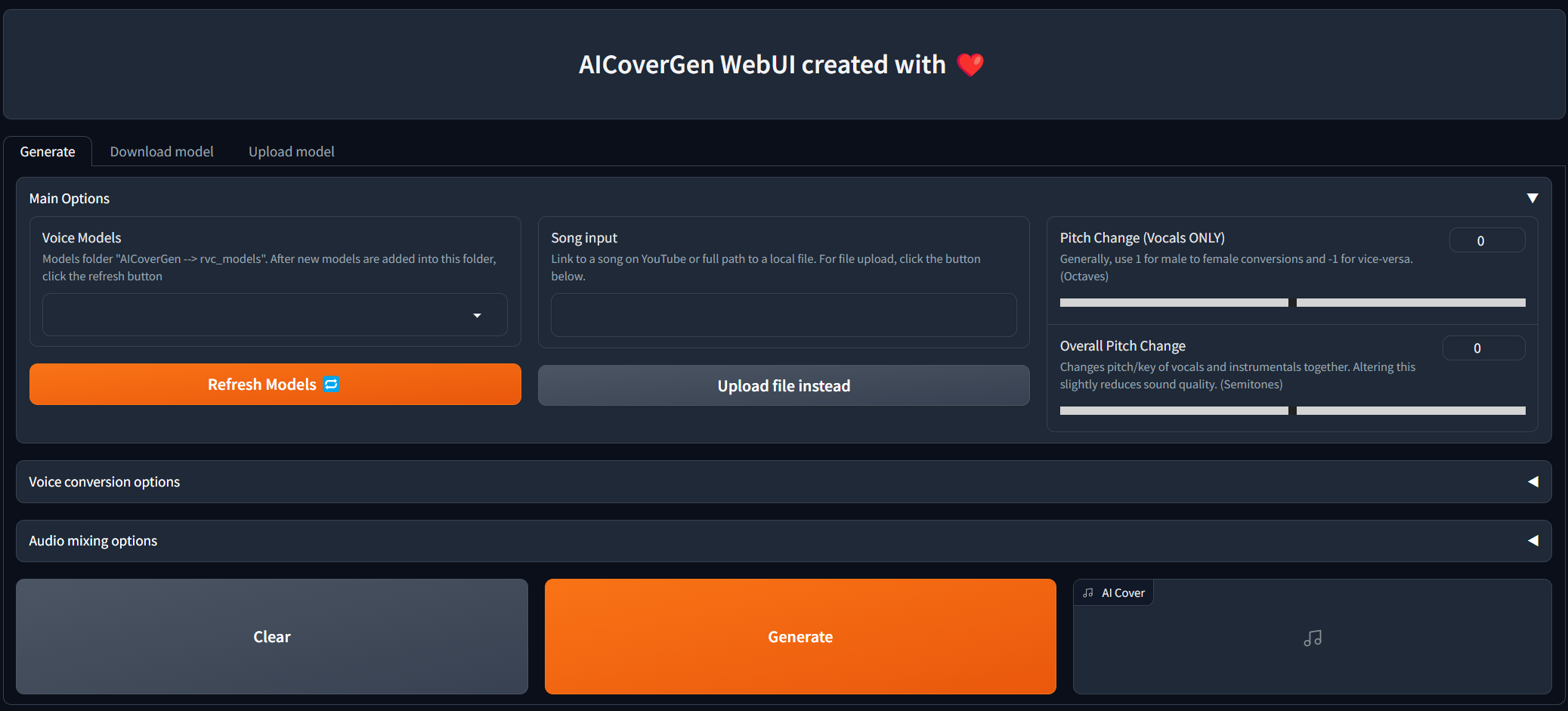
WebUIは絶え間ない開発とテストを受けていますが、ローカルとコラブの両方で今すぐ試してみることができます!
AICoverGenディレクトリにコマンドラインウィンドウを開き、次のコマンドを実行することにより、新しい要件と変更をインストールして引き出します。
pip install -r requirements.txt
git pull
コラブユーザーの場合は、コラブノートブックの上部ナビゲーションバーのRuntimeをクリックして、ドロップダウンメニューでDisconnect and delete runtime 。次に、ノートブックの指示に従ってWebUIを実行します。
十分な強力なNvidia GPUのない人のために、Google Colabを使用してAicovergenを試してみることができます。
数分後にGoogle Colabノートブックが切断されることに直面している人のために、WebUIを使用しない代替手段があります。
これをローカルに実行したい人は、以下のセットアップガイドに従ってください。
ここで指示に従って、コンピューターにGitをインストールしてください。また、このガイドに従って、Pythonバージョン3.9をまだインストールしていない場合は、インストールしてください。 Pythonの他のバージョンを使用すると、依存関係の競合が発生する場合があります。
ここで指示に従って、コンピューターにFFMPEGをインストールしてください。
ここで指示に従ってSOXをインストールし、Windows Path環境に追加します。
コマンドラインウィンドウを開き、これらのコマンドを実行してこのリポジトリ全体をクローンし、必要な追加の依存関係をインストールします。
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
次のコマンドを実行して、必要なMDXNETボーカル分離モデルとHubertベースモデルをダウンロードします。
python src/download_models.py
Aicovergen WebUIを実行するには、次のコマンドを実行します。
python src/webui.py
| フラグ | 説明 |
|---|---|
-h 、 --help | このヘルプメッセージと出口を表示します。 |
--share | パブリックURLを作成します。これは、Google ColabでWeb UIを実行するのに役立ちます。 |
--listen | あなたのローカルネットワークからWeb UIに到達可能にします。 |
--listen-host LISTEN_HOST | サーバーが使用するホスト名。 |
--listen-port LISTEN_PORT | サーバーが使用するリスニングポート。 |
Running on local URL: http://127.0.0.1:7860が表示されたら、リンクをクリックしてWebUIでタブを開くことができます。
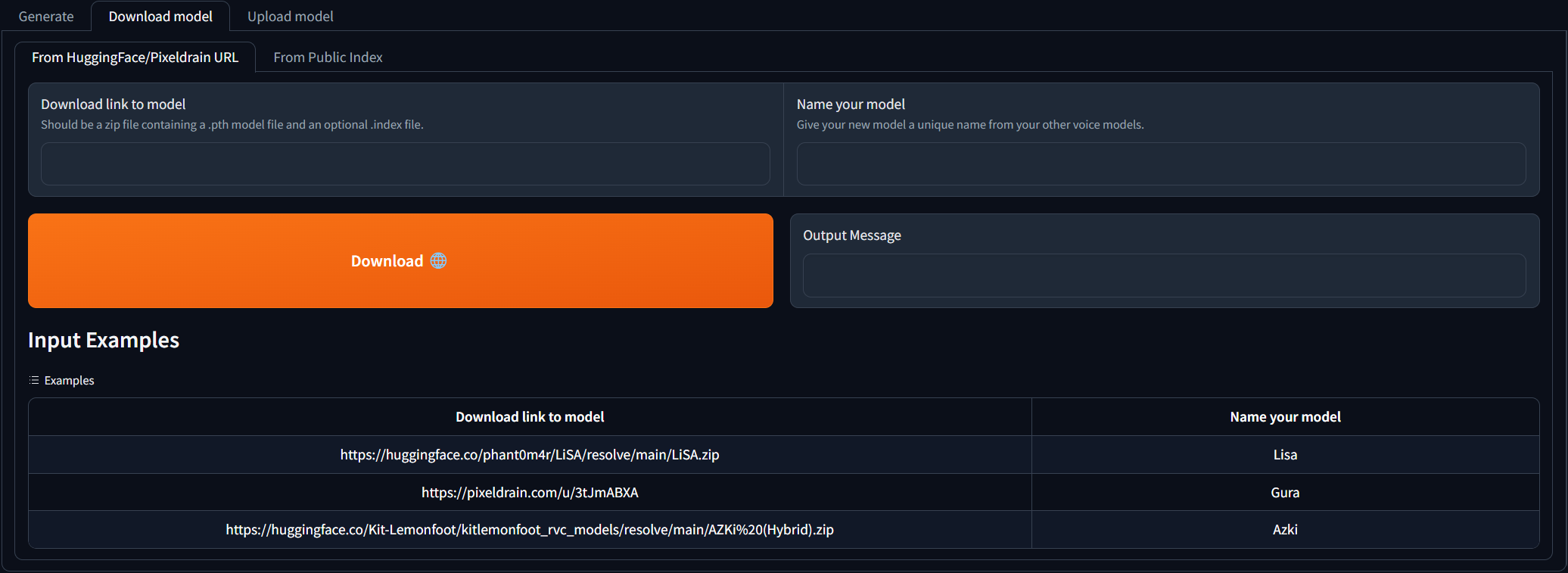
Download modelタブに移動し、ダウンロードリンクをRVCモデルに貼り付けて、一意の名前を付けます。既に訓練された音声モデルがダウンロードできるAIハブの不一致を検索できます。ダウンロードリンクがどのように見えるかについての例を参照できます。ダウンロードされたzipファイルには、.pthモデルファイルとオプションの.indexファイルが含まれている必要があります。
2つの入力フィールドが入力されたら、 Downloadをクリックするだけです!出力メッセージが[NAME] Model successfully downloaded! 、リフレッシュモデルボタンをクリックした後、 Generateタブで使用できるはずです。
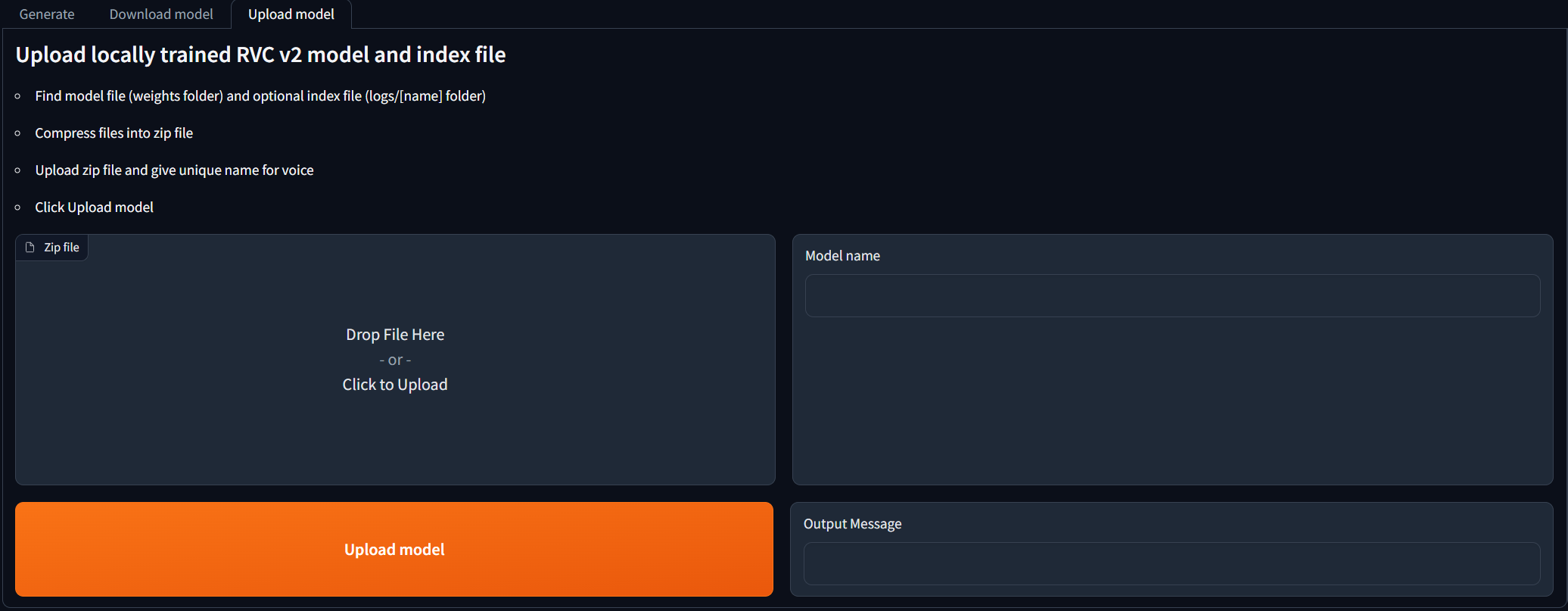
RVC V2モデルをローカルで訓練し、AIカバー世代に使用したい人向け。 Upload modelタブに移動し、手順に従ってください。出力メッセージに[NAME] Model successfully uploaded! 、リフレッシュモデルボタンをクリックした後、 Generateタブで使用できるはずです。
Updateをクリックしてリストを更新します。すべてのメインオプションが入力されたら、 Generateをクリックすると、GPUに応じてAI生成カバーが数分以内に表示されます。
UNZIP(必要に応じて)、. .pthおよび.indexファイルをrvc_modelsディレクトリの新しいフォルダーに転送します。各フォルダーには、1つの.pthと1つの.indexファイルのみが含まれている必要があります。
ディレクトリ構造は次のようになります。
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
コマンドラインを使用してAIカバー生成パイプラインを実行するには、次のコマンドを実行します。
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| フラグ | 説明 |
|---|---|
-h 、 --help | このヘルプメッセージと出口を表示します。 |
-i SONG_INPUT | YouTubeの曲へのリンクまたはローカルオーディオファイルへのパス。 Windowsの二重引用符と、Unixのようなシステムの単一引用符で囲む必要があります。 |
-dir MODEL_DIR_NAME | 特定の音声用の.pthおよび.indexファイルを含むRVC_Modelsディレクトリのフォルダーの名前。 |
-p PITCH_CHANGE | オクターブでAIボーカルのピッチを変更します。変更なしで0に設定します。一般に、男性から女性の変換に1を使用し、その逆に-1を使用します。 |
-k | オプション。すべての中間オーディオファイルを生成するために追加できます。たとえば、孤立したAIボーカル/インストゥルメンタル。スペースを節約するために除外してください。 |
-ir INDEX_RATE | オプション。デフォルト0.5。ボーカルに残るAIのアクセントのどれだけを制御します。 0 <= index_rate <= 1。 |
-fr FILTER_RADIUS | オプション。デフォルト3。> = 3:収穫されたピッチの結果に中央値フィルタリングの中央値フィルタリングを適用します。 0 <= filter_radius <= 7。 |
-rms RMS_MIX_RATE | オプション。デフォルト0.25。オリジナルのボーカルのラウドネス(0)または固定のラウドネス(1)を使用する量を制御します。 0 <= rms_mix_rate <= 1。 |
-palgo PITCH_DETECTION_ALGO | オプション。デフォルトのrmvpe。最良のオプションは、RMVPE(ボーカルの明確さ)、次にMangio-Crepe(よりスムーズなボーカル)です。 |
-hop CREPE_HOP_LENGTH | オプション。デフォルト128。Mangio-Crepe Algoを具体的に使用する際に、ミリ秒のピッチの変化をチェックする頻度を制御します。値が低いと、変換が長くなり、音声亀裂のリスクが高くなりますが、ピッチの精度が向上します。 |
-pro PROTECT | オプション。デフォルト0.33。元のボーカルの息と声のない子音のどれだけが、AIボーカルに残るかを制御します。無効になるように0.5を設定します。 0 <=保護<= 0.5。 |
-mv MAIN_VOCALS_VOLUME_CHANGE | オプション。デフォルト0。メインAIボーカルのコントロールボリューム。 -3を使用してボリュームを3デシベルまたは3つ減らして、ボリュームを3デシベルに増やします。 |
-bv BACKUP_VOCALS_VOLUME_CHANGE | オプション。デフォルト0。バックアップAIボーカルのコントロールボリューム。 |
-iv INSTRUMENTAL_VOLUME_CHANGE | オプション。デフォルト0。バックグラウンドミュージック/インストゥルメンタルのコントロールボリューム。 |
-pall PITCH_CHANGE_ALL | オプション。デフォルト0。セミトーンのバックグラウンドミュージック、バックアップボーカル、AIボーカルのピッチ/キーを変更します。音質をわずかに低下させます。 |
-rsize REVERB_SIZE | オプション。デフォルト0.15。部屋が大きいほど、リバーブ時間が長くなります。 0 <= reverb_size <= 1。 |
-rwet REVERB_WETNESS | オプション。デフォルト0.2。リバーブを使用したAIボーカルのレベル。 0 <= reverb_wetness <= 1。 |
-rdry REVERB_DRYNESS | オプション。デフォルト0.8。リバーブなしのAIボーカルのレベル。 0 <= reverb_dryness <= 1。 |
-rdamp REVERB_DAMPING | オプション。デフォルト0.7。リバーブの高周波数の吸収。 0 <= reverb_damping <= 1。 |
-oformat OUTPUT_FORMAT | オプション。デフォルトMP3。最高の品質と大きなファイルサイズのWAV、まともな品質と小さなファイルサイズのMP3。 |
次の目的で変換された音声の使用は禁止されています。
個人を批判または攻撃する。
特定の政治的地位、宗教、またはイデオロギーを擁護する、または反対する。
適切なゾーニングなしで強く刺激的な表現を公開します。
音声モデルと生成された音声クリップの販売。
他の人を傷つけたり傷つけたりするという悪意のある意図を持って、声の元の所有者のなりすまし。
個人情報の盗難や不正な電話につながる詐欺目的。
私は、このソフトウェアの使用/誤用または使用不能に関連する、または何らかの形で発生する、または何らかの形で発生する、直接的、間接的、結果的、偶発的、または特別な損害について責任を負いません。


