COCO LM
v0.1.0
该存储库包含用于胶水和小队2.0基准的微调可可读取模型的脚本。
论文:可可-LM:校正和对比的语言模型的文本序列
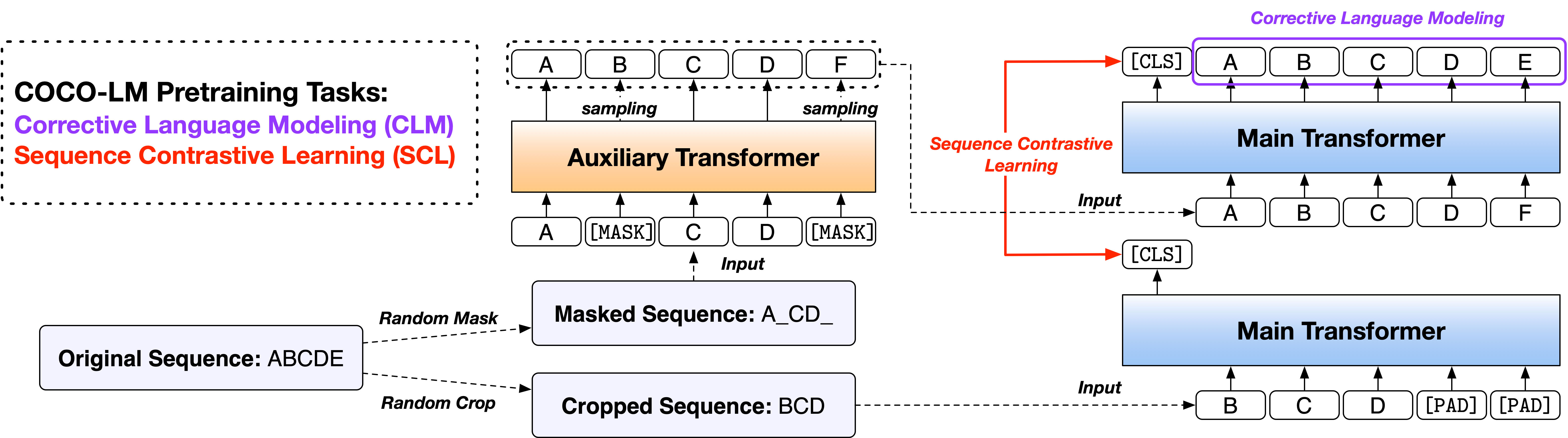
我们基于两个广泛使用的开源代码库,Fairseq库和HuggingFace Transfereers库,以两个版本提供脚本。这两个代码版本大多在功能上等效,您可以免费使用其中的两个代码。但是,我们注意到FairSeq版本是我们在实验中使用的,它将最好地重现论文中的结果。稍后将实现HuggingFace版本,以提供与Huggingface Transfereers库的兼容性,并可能产生略有不同的结果。
请按照两个目录下的“读书文件”文件运行代码。
一般语言理解评估(GLUE)基准是句子或句子的语言理解任务的集合,用于评估和分析自然语言理解系统。
可可-lm碱++和大++模型的胶水开发结果如下(5种随机种子的中值):
| 模型 | MNLI-M/mm | QQP | Qnli | SST-2 | 可乐 | rte | MRPC | STS-B | avg |
|---|---|---|---|---|---|---|---|---|---|
| 可可-LM碱++ | 90.2/90.0 | 92.2 | 94.2 | 94.6 | 67.3 | 87.4 | 91.2 | 91.8 | 88.6 |
| 可可lm ++ | 91.4/91.6 | 92.8 | 95.7 | 96.9 | 73.9 | 91.0 | 92.2 | 92.7 | 90.8 |
可可-lm base ++和大++模型的胶水测试集结果如下(没有集合,特定于任务的技巧等):
| 模型 | MNLI-M/mm | QQP | Qnli | SST-2 | 可乐 | rte | MRPC | STS-B | avg |
|---|---|---|---|---|---|---|---|---|---|
| 可可-LM碱++ | 89.8/89.3 | 89.8 | 94.2 | 95.6 | 68.6 | 82.3 | 88.5 | 90.3 | 87.4 |
| 可可lm ++ | 91.6/91.1 | 90.5 | 95.8 | 96.7 | 70.5 | 89.2 | 88.4 | 91.8 | 89.3 |
Stanford问题回答数据集(小队)是一个阅读理解数据集,由人群工人对Wikipedia文章提出的问题组成,每个问题的答案是来自相应的阅读段落中的文本或跨度的部分,否则问题可能是无法回答的。
Coco-LM碱++和大++模型的小队2.0 DEV集结果如下(5种随机种子的中值):
| 模型 | Em | F1 |
|---|---|---|
| 可可-LM碱++ | 85.4 | 88.1 |
| 可可lm ++ | 88.2 | 91.0 |
如果您发现代码和模型对您的研究有用,请引用以下论文:
@inproceedings{meng2021cocolm,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
该项目欢迎贡献和建议。大多数捐款要求您同意撰写贡献者许可协议(CLA),宣布您有权并实际上授予我们使用您的贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
当您提交拉动请求时,CLA机器人将自动确定您是否需要提供CLA并适当装饰PR(例如状态检查,评论)。只需按照机器人提供的说明即可。您只需要使用我们的CLA在所有存储库中进行一次。
该项目采用了Microsoft开源的行为代码。有关更多信息,请参见《行为守则常见问题守则》或与其他问题或评论联系[email protected]。


