COCO LM
v0.1.0
Repositori ini berisi skrip untuk menyempurnakan model pretrained coco-LM pada tolok ukur lem dan pasukan 2.0.
Kertas: Coco-LM: Mengoreksi dan mengontrak urutan teks untuk pretraining model bahasa
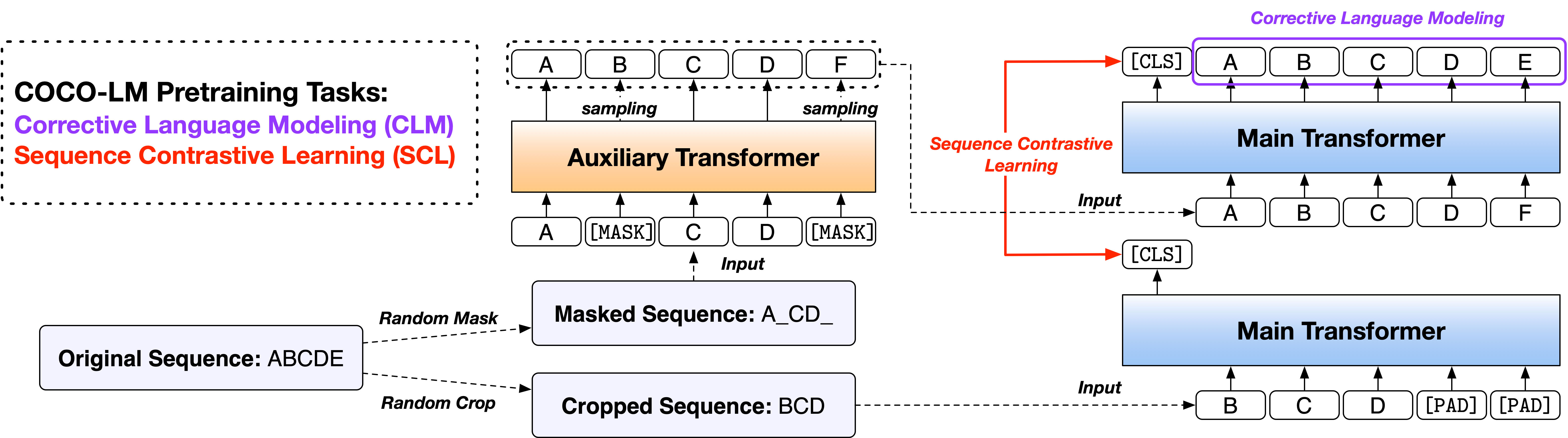
Kami menyediakan skrip dalam dua versi, berdasarkan dua basis kode open-source yang banyak digunakan, Perpustakaan Fairseq dan Perpustakaan Huggingface Transformers. Dua versi kode sebagian besar setara dalam fungsionalitas, dan Anda bebas menggunakan keduanya. Namun, kami mencatat bahwa versi Fairseq adalah apa yang kami gunakan dalam percobaan kami, dan itu akan mereproduksi hasil di koran; Versi Huggingface diimplementasikan kemudian untuk memberikan kompatibilitas dengan perpustakaan HuggingFace Transformers, dan dapat menghasilkan hasil yang sedikit berbeda.
Harap ikuti file readme di bawah dua direktori untuk menjalankan kode.
Benchmark evaluasi pemahaman bahasa umum (lem) adalah kumpulan tugas-tugas pemahaman bahasa kalimat atau kalimat untuk mengevaluasi dan menganalisis sistem pemahaman bahasa alami.
Glue Dev Hasil Hasil Coco-LM Base ++ dan Besar ++ Model adalah sebagai berikut (median 5 biji acak yang berbeda):
| Model | Mnli-m/mm | QQP | Qnli | SST-2 | Cola | Rte | Mrpc | STS-B | Rata -rata |
|---|---|---|---|---|---|---|---|---|---|
| Basis Coco-LM ++ | 90.2/90.0 | 92.2 | 94.2 | 94.6 | 67.3 | 87.4 | 91.2 | 91.8 | 88.6 |
| Coco-LM Besar ++ | 91.4/91.6 | 92.8 | 95.7 | 96.9 | 73.9 | 91.0 | 92.2 | 92.7 | 90.8 |
Hasil Hasil Tes Tes Lem dari Basis Coco-LM ++ dan Model ++ Besar adalah sebagai berikut (tidak ada ansambel, trik khusus tugas, dll.):
| Model | Mnli-m/mm | QQP | Qnli | SST-2 | Cola | Rte | Mrpc | STS-B | Rata -rata |
|---|---|---|---|---|---|---|---|---|---|
| Basis Coco-LM ++ | 89.8/89.3 | 89.8 | 94.2 | 95.6 | 68.6 | 82.3 | 88.5 | 90.3 | 87.4 |
| Coco-LM Besar ++ | 91.6/91.1 | 90.5 | 95.8 | 96.7 | 70.5 | 89.2 | 88.4 | 91.8 | 89.3 |
Stanford Pertanyaan menjawab Dataset (Skuad) adalah dataset pemahaman bacaan, yang terdiri dari pertanyaan yang diajukan oleh pekerja kerumunan pada satu set artikel Wikipedia, di mana jawaban untuk setiap pertanyaan adalah segmen teks, atau rentang, dari bagian bacaan yang sesuai, atau pertanyaannya mungkin tidak dapat dijawab.
Skuad 2.0 Dev Menetapkan Hasil Basis Coco-LM ++ dan Model ++ Besar adalah sebagai berikut (median 5 biji acak yang berbeda):
| Model | Em | F1 |
|---|---|---|
| Basis Coco-LM ++ | 85.4 | 88.1 |
| Coco-LM Besar ++ | 88.2 | 91.0 |
Jika Anda menemukan kode dan model yang berguna untuk penelitian Anda, silakan kutip makalah berikut:
@inproceedings{meng2021cocolm,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
Proyek ini menyambut kontribusi dan saran. Sebagian besar kontribusi mengharuskan Anda untuk menyetujui perjanjian lisensi kontributor (CLA) yang menyatakan bahwa Anda memiliki hak untuk, dan benar -benar melakukannya, beri kami hak untuk menggunakan kontribusi Anda. Untuk detailnya, kunjungi https://cla.opensource.microsoft.com.
Saat Anda mengirimkan permintaan tarik, bot CLA akan secara otomatis menentukan apakah Anda perlu memberikan CLA dan menghiasi PR secara tepat (misalnya, pemeriksaan status, komentar). Cukup ikuti instruksi yang disediakan oleh bot. Anda hanya perlu melakukan ini sekali di semua repo menggunakan CLA kami.
Proyek ini telah mengadopsi kode perilaku open source Microsoft. Untuk informasi lebih lanjut, lihat FAQ Kode Perilaku atau hubungi [email protected] dengan pertanyaan atau komentar tambahan.


