COCO LM
v0.1.0
Este repositorio contiene los scripts para ajustar los modelos previos a la pretrada de Coco-LM en los puntos de referencia de pegamento y escuadrón 2.0.
Documento: Coco-LM: corrección y contraste de secuencias de texto para el modelo de lenguaje previamente
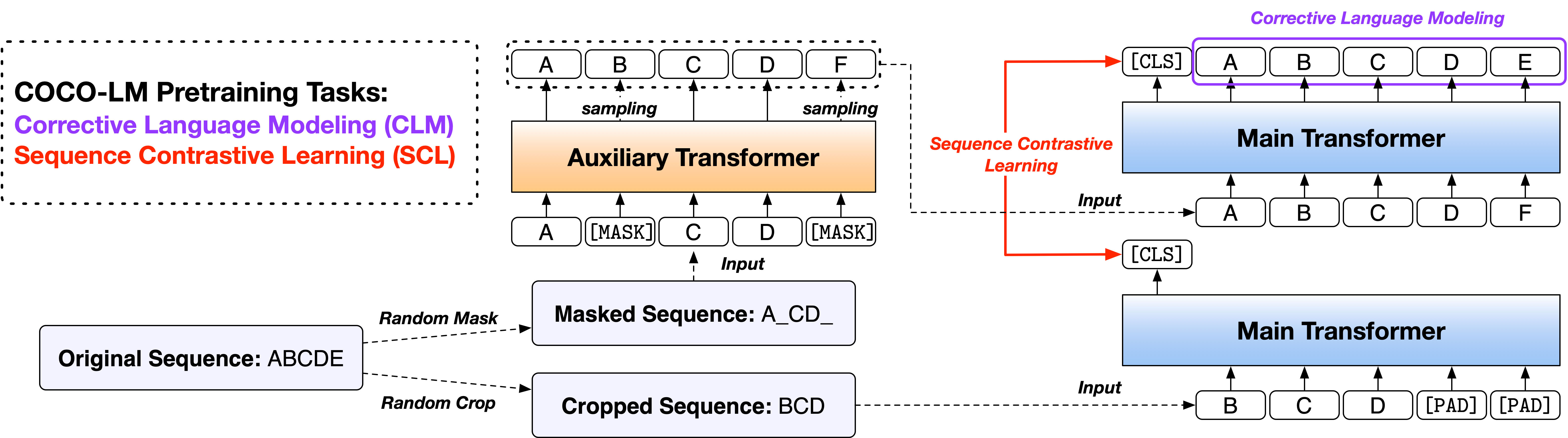
Proporcionamos los scripts en dos versiones, basados en dos bases de código de código abierto ampliamente utilizados, la biblioteca Fairseq y la biblioteca Huggingface Transformers. Las dos versiones de código son en su mayoría equivalentes en funcionalidad, y usted es libre de usar cualquiera de ellas. Sin embargo, observamos que la versión FairSeq es lo que utilizamos en nuestros experimentos, y mejor reproducirá los resultados en el documento; La versión Huggingface se implementa más tarde para proporcionar compatibilidad con la biblioteca Huggingface Transformers, y puede producir resultados ligeramente diferentes.
Siga los archivos ReadMe en los dos directorios para ejecutar el código.
El punto de referencia de evaluación general de comprensión del lenguaje (pegamento) es una colección de tareas de comprensión de lenguaje de oraciones o oraciones para evaluar y analizar los sistemas de comprensión del lenguaje natural.
Los resultados del conjunto de desarrollo de pegamento de los modelos de base ++ y grandes ++ grandes son los siguientes (mediana de 5 semillas aleatorias diferentes):
| Modelo | Mnli-m/mm | QQP | Qnli | SST-2 | Reajuste salarial | RTE | MRPC | STS-B | Aviso |
|---|---|---|---|---|---|---|---|---|---|
| Base de Coco-LM ++ | 90.2/90.0 | 92.2 | 94.2 | 94.6 | 67.3 | 87.4 | 91.2 | 91.8 | 88.6 |
| Coco-LM grande ++ | 91.4/91.6 | 92.8 | 95.7 | 96.9 | 73.9 | 91.0 | 92.2 | 92.7 | 90.8 |
Los resultados del conjunto de pruebas de pegamento de los modelos de Coco-LM Base ++ y grandes ++ son los siguientes (sin conjunto, trucos específicos de tareas, etc.):
| Modelo | Mnli-m/mm | QQP | Qnli | SST-2 | Reajuste salarial | RTE | MRPC | STS-B | Aviso |
|---|---|---|---|---|---|---|---|---|---|
| Base de Coco-LM ++ | 89.8/89.3 | 89.8 | 94.2 | 95.6 | 68.6 | 82.3 | 88.5 | 90.3 | 87.4 |
| Coco-LM grande ++ | 91.6/91.1 | 90.5 | 95.8 | 96.7 | 70.5 | 89.2 | 88.4 | 91.8 | 89.3 |
Stanford Pregunta Contestador de datos del conjunto de datos (Escuadrón) es un conjunto de datos de comprensión de lectura, que consiste en preguntas planteadas por los trabajadores colectivos en un conjunto de artículos de Wikipedia, donde la respuesta a cada pregunta es un segmento de texto, o en el tramo, del pasaje de lectura correspondiente, o la pregunta podría ser sin respuesta.
Squad 2.0 Dev Los resultados de la base de Coco-LM ++ y los modelos grandes ++ son los siguientes (mediana de 5 semillas aleatorias diferentes):
| Modelo | Em | F1 |
|---|---|---|
| Base de Coco-LM ++ | 85.4 | 88.1 |
| Coco-LM grande ++ | 88.2 | 91.0 |
Si encuentra útiles el código y los modelos para su investigación, cite el siguiente documento:
@inproceedings{meng2021cocolm,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
Este proyecto da la bienvenida a las contribuciones y sugerencias. La mayoría de las contribuciones requieren que acepte un Acuerdo de Licencia de Contributor (CLA) que declare que tiene derecho y realmente hacernos los derechos para utilizar su contribución. Para más detalles, visite https://cla.opensource.microsoft.com.
Cuando envíe una solicitud de extracción, un BOT CLA determinará automáticamente si necesita proporcionar un CLA y decorar el PR adecuadamente (por ejemplo, verificación de estado, comentario). Simplemente siga las instrucciones proporcionadas por el bot. Solo necesitará hacer esto una vez en todos los reposos usando nuestro CLA.
Este proyecto ha adoptado el Código de Conducta Open Open Microsoft. Para obtener más información, consulte el Código de Conducta Preguntas frecuentes o comuníquese con [email protected] con cualquier pregunta o comentario adicional.


