COCO LM
v0.1.0
Ce référentiel contient les scripts pour les modèles pré-entraînés par Coco-LM raffinés sur des repères Glue et Squad 2.0.
Papier: Coco-LM: Correction et séquences de texte contrastées pour le modèle de langue pré-formation
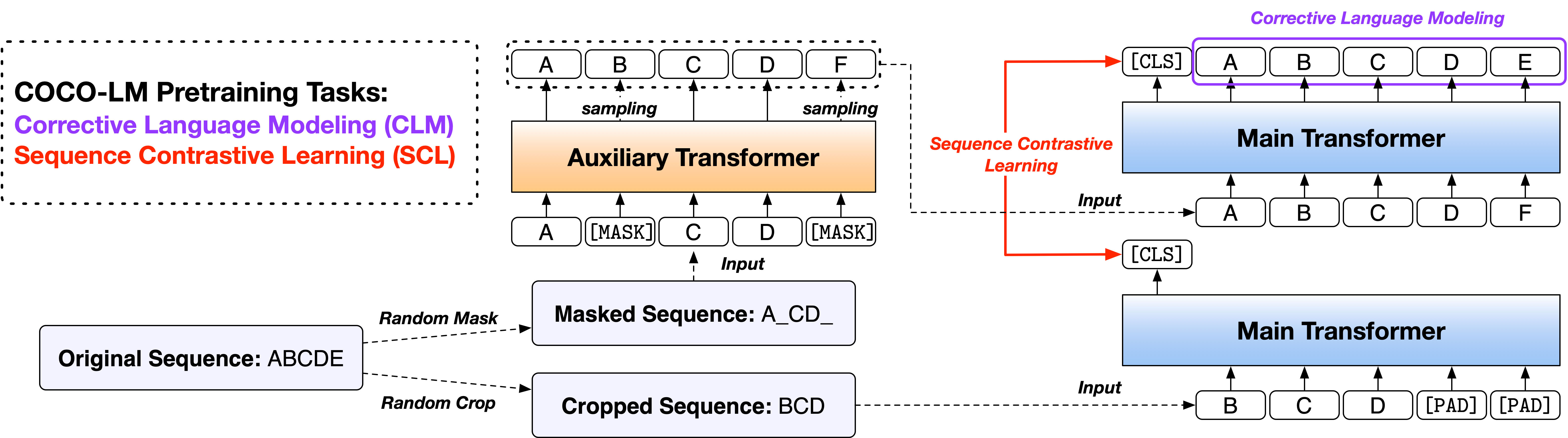
Nous fournissons les scripts en deux versions, sur la base de deux bases de code open source largement utilisées, de la bibliothèque Fairseq et de la bibliothèque de transformateurs HuggingFace. Les deux versions de code sont principalement équivalentes en fonctionnalité, et vous êtes libre de les utiliser. Cependant, nous notons que la version Fairseq est ce que nous avons utilisé dans nos expériences, et elle reproduira mieux les résultats dans le papier; La version HuggingFace est implémentée plus tard pour assurer la compatibilité avec la bibliothèque HuggingFace Transformers et peut donner des résultats légèrement différents.
Veuillez suivre les fichiers ReadMe sous les deux répertoires pour exécuter le code.
La référence d'évaluation générale de la compréhension du langage (GLUE) est une collection de tâches de compréhension du langage des phrases ou des phrases pour évaluer et analyser les systèmes de compréhension du langage naturel.
Les résultats de fonction de développement de la base de la base coco-lm ++ et les grands modèles ++ sont les suivants (médiane de 5 graines aléatoires différentes):
| Modèle | MNLI-M / MM | QQP | QNLI | SST-2 | Cola | Rte | MRPC | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|---|
| Coco-lm base ++ | 90.2 / 90.0 | 92.2 | 94.2 | 94.6 | 67.3 | 87.4 | 91.2 | 91.8 | 88.6 |
| Coco-lm grand ++ | 91.4 / 91.6 | 92.8 | 95.7 | 96.9 | 73.9 | 91.0 | 92.2 | 92.7 | 90.8 |
Les résultats des tests de colle de Coco-LM Base ++ et les grands modèles ++ sont les suivants (pas d'ensemble, astuces spécifiques à la tâche, etc.):
| Modèle | MNLI-M / MM | QQP | QNLI | SST-2 | Cola | Rte | MRPC | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|---|
| Coco-lm base ++ | 89.8 / 89.3 | 89.8 | 94.2 | 95.6 | 68.6 | 82.3 | 88.5 | 90.3 | 87.4 |
| Coco-lm grand ++ | 91.6 / 91.1 | 90.5 | 95.8 | 96.7 | 70.5 | 89.2 | 88.4 | 91.8 | 89.3 |
La question de la question de Stanford répondant à un ensemble de données (Squad) est un ensemble de données de compréhension en lecture, composé de questions posées par des travailleurs de mi-temps sur un ensemble d'articles de Wikipedia, où la réponse à chaque question est un segment de texte, ou de portée, du passage de lecture correspondant, ou de la question pourrait être incomparable.
Squad 2.0 Dev set Resseaux Résultats de Coco-LM Base ++ et de grands modèles ++ sont les suivants (médiane de 5 graines aléatoires différentes):
| Modèle | Em | F1 |
|---|---|---|
| Coco-lm base ++ | 85.4 | 88.1 |
| Coco-lm grand ++ | 88.2 | 91.0 |
Si vous trouvez le code et les modèles utiles pour vos recherches, veuillez citer l'article suivant:
@inproceedings{meng2021cocolm,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
Ce projet accueille les contributions et les suggestions. La plupart des contributions vous obligent à accepter un accord de licence de contributeur (CLA) déclarant que vous avez le droit de faire et en fait, accordez-nous les droits d'utilisation de votre contribution. Pour plus de détails, visitez https://cla.opensource.microsoft.com.
Lorsque vous soumettez une demande de traction, un bot CLA déterminera automatiquement si vous devez fournir un CLA et décorer le RP de manière appropriée (par exemple, vérification d'état, commentaire). Suivez simplement les instructions fournies par le bot. Vous n'aurez besoin de le faire qu'une seule fois sur tous les dépositions en utilisant notre CLA.
Ce projet a adopté le code de conduite open source Microsoft. Pour plus d'informations, consultez le code de conduite FAQ ou contactez [email protected] avec toute question ou commentaire supplémentaire.


