COCO LM
v0.1.0
พื้นที่เก็บข้อมูลนี้มีสคริปต์สำหรับการปรับแต่งแบบจำลอง Coco-LM แบบปรับแต่งบนเกณฑ์มาตรฐานกาวและทีม 2.0
Paper: Coco-LM: การแก้ไขและลำดับข้อความที่ตัดกันสำหรับรูปแบบภาษาก่อนการฝึกอบรม
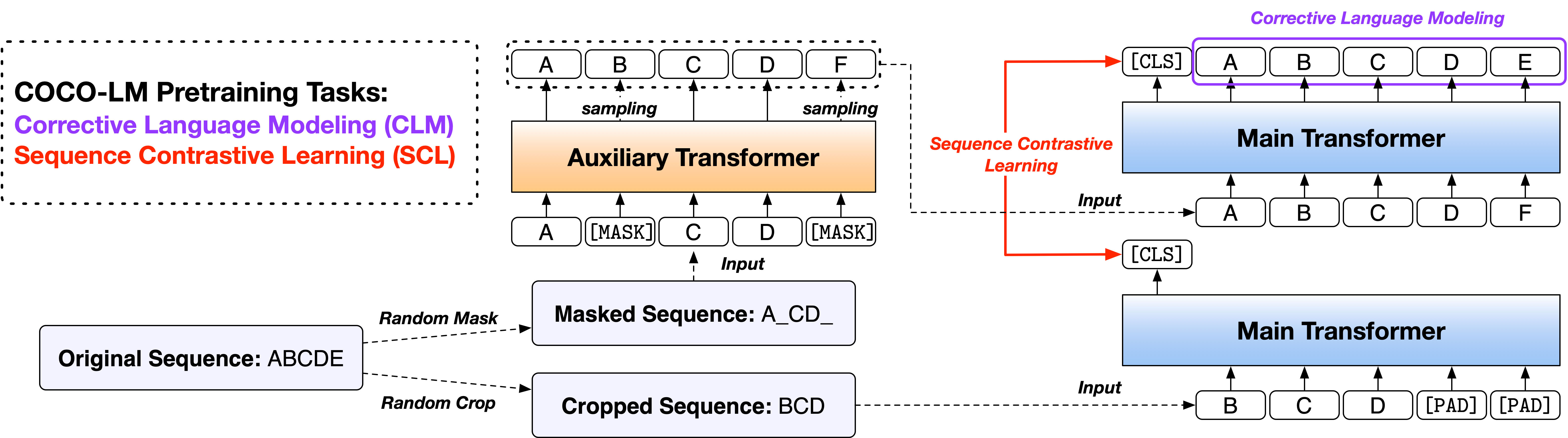
เราให้บริการสคริปต์ในสองเวอร์ชันโดยใช้รหัสฐานโอเพนซอร์สที่ใช้กันอย่างแพร่หลายสองรายการคือห้องสมุด Fairseq และห้องสมุด HuggingFace Transformers รหัสสองรุ่นส่วนใหญ่เทียบเท่ากับฟังก์ชั่นและคุณมีอิสระที่จะใช้ทั้งสองอย่าง อย่างไรก็ตามเราทราบว่าเวอร์ชัน Fairseq เป็นสิ่งที่เราใช้ในการทดลองของเราและมันจะทำซ้ำผลลัพธ์ในกระดาษได้ดีที่สุด รุ่น HuggingFace ถูกนำมาใช้ในภายหลังเพื่อให้เข้ากันได้กับห้องสมุด HuggingFace Transformers และอาจให้ผลลัพธ์ที่แตกต่างกันเล็กน้อย
โปรดติดตามไฟล์ readme ภายใต้ไดเรกทอรีสองไดเรกทอรีเพื่อเรียกใช้รหัส
เกณฑ์มาตรฐานการประเมินภาษาทั่วไป (กาว) เป็นการรวบรวมงานการทำความเข้าใจภาษาคู่ประโยคหรือประโยคคู่สำหรับการประเมินและวิเคราะห์ระบบการทำความเข้าใจภาษาธรรมชาติ
ชุดกาว Dev Set ผลลัพธ์ของฐาน Coco-LM ++ และขนาดใหญ่ ++ มีดังนี้ (ค่ามัธยฐานของ 5 เมล็ดสุ่มที่แตกต่างกัน):
| แบบอย่าง | mnli-m/mm | qqp | qnli | SST-2 | โคล่า | rte | MRPC | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|---|
| ฐาน Coco-LM ++ | 90.2/90.0 | 92.2 | 94.2 | 94.6 | 67.3 | 87.4 | 91.2 | 91.8 | 88.6 |
| Coco-LM ขนาดใหญ่ ++ | 91.4/91.6 | 92.8 | 95.7 | 96.9 | 73.9 | 91.0 | 92.2 | 92.7 | 90.8 |
ชุดทดสอบกาวผลการทดสอบของฐาน Coco-LM ++ และขนาดใหญ่ ++ มีดังนี้ (ไม่มีชุด, กลอุบายเฉพาะงาน ฯลฯ ):
| แบบอย่าง | mnli-m/mm | qqp | qnli | SST-2 | โคล่า | rte | MRPC | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|---|
| ฐาน Coco-LM ++ | 89.8/89.3 | 89.8 | 94.2 | 95.6 | 68.6 | 82.3 | 88.5 | 90.3 | 87.4 |
| Coco-LM ขนาดใหญ่ ++ | 91.6/91.1 | 90.5 | 95.8 | 96.7 | 70.5 | 89.2 | 88.4 | 91.8 | 89.3 |
ชุดข้อมูลการตอบคำถาม Stanford (Squad) เป็นชุดข้อมูลการอ่านความเข้าใจซึ่งประกอบด้วยคำถามที่วางโดยฝูงชนในชุดของบทความ Wikipedia ซึ่งคำตอบสำหรับคำถามทุกข้อคือส่วนของข้อความหรือช่วงจากข้อความการอ่านที่เกี่ยวข้องหรือคำถามอาจไม่สามารถตอบได้
Squad 2.0 Dev Set ผลลัพธ์ของ Coco-LM Base ++ และขนาดใหญ่ ++ มีดังนี้ (ค่ามัธยฐานของ 5 เมล็ดสุ่มที่แตกต่างกัน):
| แบบอย่าง | em | F1 |
|---|---|---|
| ฐาน Coco-LM ++ | 85.4 | 88.1 |
| Coco-LM ขนาดใหญ่ ++ | 88.2 | 91.0 |
หากคุณพบว่ารหัสและโมเดลมีประโยชน์สำหรับการวิจัยของคุณโปรดอ้างอิงบทความต่อไปนี้:
@inproceedings{meng2021cocolm,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
โครงการนี้ยินดีต้อนรับการมีส่วนร่วมและข้อเสนอแนะ การมีส่วนร่วมส่วนใหญ่กำหนดให้คุณต้องยอมรับข้อตกลงใบอนุญาตผู้มีส่วนร่วม (CLA) ประกาศว่าคุณมีสิทธิ์และทำจริงให้สิทธิ์ในการใช้การบริจาคของคุณ สำหรับรายละเอียดเยี่ยมชม https://cla.opensource.microsoft.com
เมื่อคุณส่งคำขอดึง CLA บอทจะพิจารณาโดยอัตโนมัติว่าคุณจำเป็นต้องให้ CLA และตกแต่ง PR อย่างเหมาะสม (เช่นการตรวจสอบสถานะแสดงความคิดเห็น) เพียงทำตามคำแนะนำที่จัดทำโดยบอท คุณจะต้องทำสิ่งนี้เพียงครั้งเดียวใน repos ทั้งหมดโดยใช้ CLA ของเรา
โครงการนี้ได้นำรหัสการดำเนินงานของ Microsoft โอเพ่นซอร์สมาใช้ สำหรับข้อมูลเพิ่มเติมโปรดดูจรรยาบรรณคำถามที่พบบ่อยหรือติดต่อ [email protected] พร้อมคำถามหรือความคิดเห็นเพิ่มเติมใด ๆ


