ELLEN
1.0.0
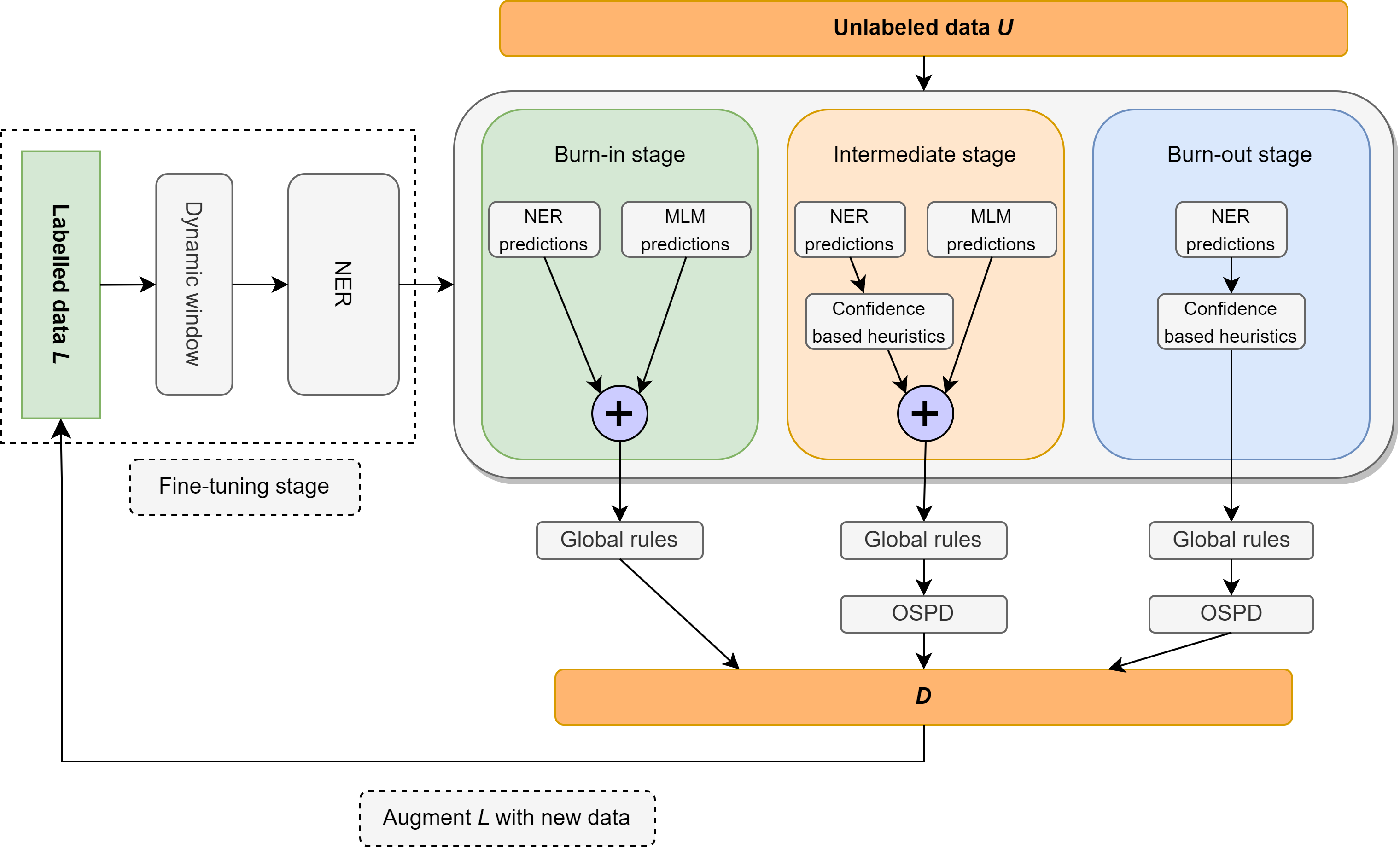
在这项工作中,我们重新审视了专注于极光监督的半监督命名实体识别(NER)的问题,该问题由每班只有10个示例的词典组成。我们介绍了Ellen,这是一种简单,完全模块化的神经符号方法,将微调语言模型与语言规则融合在一起。这些规则包括诸如“每次话语的一种意义”,以蒙版语言模型为无监督的NER之类的见解,利用言论的一部分标签以识别和消除无标记的实体为虚假的实体,以及其他有关本地和全球环境中分类器信心得分的直觉。当使用上面词典的最小监督时,Ellen在CONLL-2003数据集上实现了非常强大的性能。在文献中常用的相同监督设置下,它还优于大多数现有的(且更为复杂)的半监督NER方法(即培训数据的5%)。此外,我们在WNUT-17上的零击场景中评估了我们的CONLL-2003模型,我们发现它的表现优于GPT-3.5,并且与GPT-4的性能可比性可比性。在零拍摄的环境中,艾伦还达到了经过黄金数据训练的强,完全监督模型的75%以上。
相机就绪代码将很快发布。
| 精确 | 记起 | F1 |
|---|---|---|
| 74.63% | 79.26% | 76.87% |
Ellen†优于更复杂的方法,例如PU-LECERNING和变化顺序标记(VSL-GGG-HIER),当时使用5%的数据作为监督。
| 方法 | p | r | F1 |
|---|---|---|---|
| vsl-gg-hier | 84.13% | 82.64% | 83.38% |
| MT +噪声 | 83.74% | 81.49% | 82.60% |
| 半拉达 | 86.93% | 85.74% | 86.33% |
| 关节商品 | 89.88% | 85.98% | 87.68% |
| pu学习 | 85.79% | 81.03% | 83.34% |
| 艾伦† | 81.88% | 88.01% | 84.87% |
| 方法 | loc | 杂项 | org | 每 | avg |
|---|---|---|---|---|---|
| T-ner | 64.21% | 42.04% | 42.98% | 66.11% | 55.11% |
| GPT-3.5 | 49.17% | 8.06% | 29.71% | 59.84% | 39.96% |
| GPT-4 | 58.70% | 25.40% | 38.05% | 56.87% | 43.72% |
| 艾伦+ | 44.82% | 6.21% | 26.49% | 67.00% | 41.56% |
我们引入了一个非常强大的基线,用于使用少于10次的无监督NER(Conll-03 Dev上的56%F1超过56%!)
| 实体类型 | 精确 | 记起 | F1 |
|---|---|---|---|
| 全面的 | 61.78% | 51.90% | 56.41% |
| loc | 69.72% | 41.53% | 52.05% |
| 杂项 | 45.18% | 55.15% | 49.67% |
| org | 44.85% | 40.88% | 42.77% |
| 每 | 85.07% | 65.02% | 73.71% |
如果您觉得这项工作有用,请考虑引用:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
根据MIT许可证,该存储库中发布的代码将在大多数情况下免费使用。
haris riaz([email protected])或([email protected])


