ELLEN
1.0.0
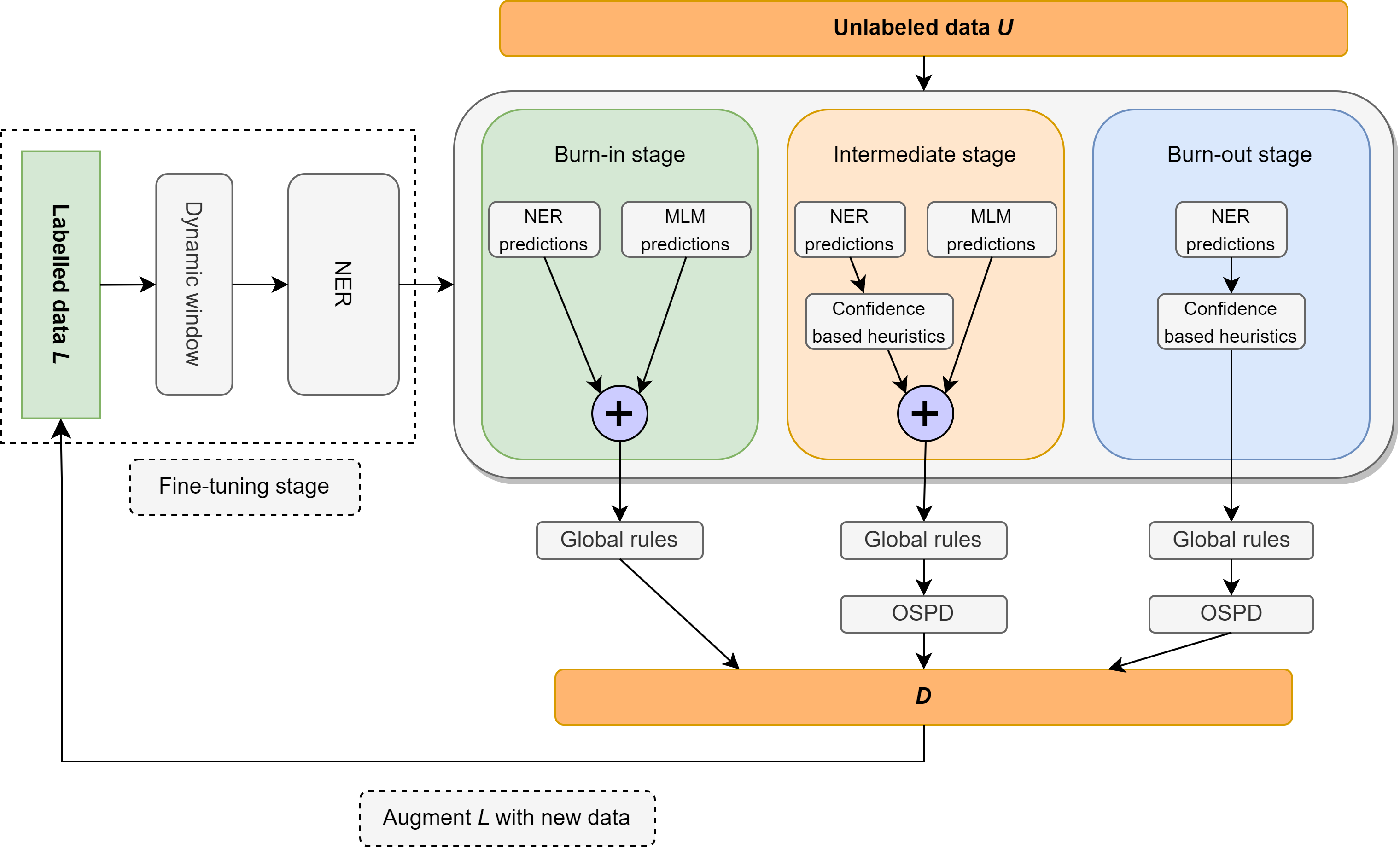
In dieser Arbeit werden wir das Problem der semi-vortrimierten benannten Entitätserkennung (NER) überprüft, die sich auf eine extrem leichte Überwachung konzentriert, die aus einem Lexikon besteht, das nur 10 Beispiele pro Klasse enthält. Wir stellen Ellen vor, eine einfache, vollständig modulare, neurosymbolische Methode, die feinstimmige Sprachmodelle mit sprachlichen Regeln kombiniert. Zu diesen Regeln gehören Erkenntnisse wie "Ein Sinn pro Diskurs", wobei ein maskiertes Sprachmodell als unbeaufsichtigter NER verwendet wird, das Teil der Speech-Tags nutzt, um unbezeichnete Entitäten als falsche Negative zu identifizieren und zu beseitigen, und andere Intuitionen über Klassifikator-Vertrauenswerte im lokalen und globalen Kontext. Ellen erzielt eine sehr starke Leistung im CONLL-2003-Datensatz, wenn die minimale Aufsicht aus dem obigen Lexikon verwendet wird. Es übertrifft auch die bestehenden (und wesentlich komplexeren) halbübergreifenden NER-Methoden unter den gleichen Aufsichtseinstellungen, die üblicherweise in der Literatur verwendet werden (dh 5% der Trainingsdaten). Darüber hinaus bewerten wir unser CONLL-2003-Modell in einem Null-Shot-Szenario auf WNUT-17, in dem wir feststellen, dass es GPT-3,5 übertrifft und eine vergleichbare Leistung mit GPT-4 erzielt. In einer Umgebung mit Nullschotten erzielt Ellen auch über 75% der Leistung eines starken, voll beaufsichtigten Modells, das auf Golddaten geschult ist.
Der Camera Ready Code wird bald veröffentlicht.
| Präzision | Abrufen | F1 |
|---|---|---|
| 74,63% | 79,26% | 76,87% |
Ellen † übertrifft komplexere Methoden wie PU-Learning und Variations-Sequential-Labeler (VSL-GG-Were), wenn 5% der Daten als Überwachung verwendet werden.
| Methoden | P | R | F1 |
|---|---|---|---|
| VSL-GG-HIER | 84,13% | 82,64% | 83,38% |
| MT + Rauschen | 83,74% | 81,49% | 82,60% |
| Semi-Lada | 86,93% | 85,74% | 86,33% |
| JointProp | 89,88% | 85,98% | 87,68% |
| Pu-Learning | 85,79% | 81,03% | 83,34% |
| Ellen † | 81,88% | 88,01% | 84,87% |
| Verfahren | Loc | Miser | Org | PRO | Avg |
|---|---|---|---|---|---|
| T-ner | 64,21% | 42,04% | 42,98% | 66,11% | 55,11% |
| GPT-3.5 | 49,17% | 8,06% | 29,71% | 59,84% | 39,96% |
| GPT-4 | 58,70% | 25,40% | 38,05% | 56,87% | 43,72% |
| Ellen+ | 44,82% | 6,21% | 26,49% | 67,00% | 41,56% |
Wir stellen eine sehr starke Grundlinie für vollständig unbeaufsichtigte NER mit weniger als 10 Schüssen vor (über 56% F1 auf CONLL-03 Dev!)
| Entitätstyp | Präzision | Abrufen | F1 |
|---|---|---|---|
| Gesamt | 61,78% | 51,90% | 56,41% |
| Loc | 69,72% | 41,53% | 52,05% |
| Miser | 45,18% | 55,15% | 49,67% |
| Org | 44,85% | 40,88% | 42,77% |
| PRO | 85,07% | 65,02% | 73,71% |
Wenn Sie diese Arbeit nützlich finden, sollten Sie sich angeben:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Der in diesem Repository veröffentlichte Code kann unter den MIT -Lizenz für die meisten Umstände verwendet werden.
Haris Riaz ([email protected]) oder ([email protected])


