ELLEN
1.0.0
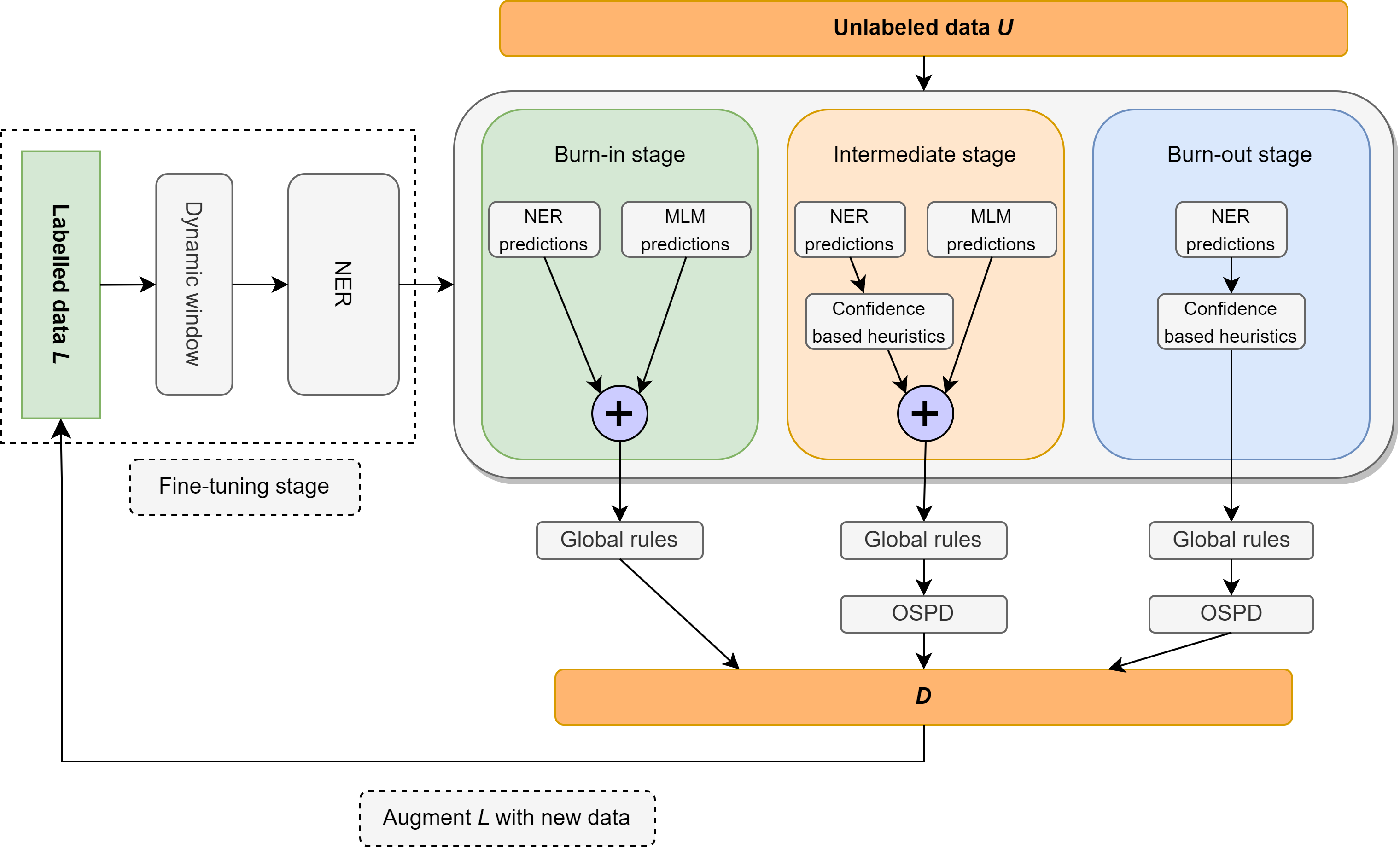
Neste trabalho, revisitamos o problema do reconhecimento de entidade nomeado semi-supervisionado (NER), com foco na supervisão extremamente leve, consistindo em um léxico contendo apenas 10 exemplos por classe. Introduzimos Ellen, um método neuro-simbólico simples, totalmente modular que combina modelos de linguagem ajustados com regras linguísticas. Essas regras incluem insights como "um sentido por discurso", usando um modelo de linguagem mascarada como um nerd não supervisionado, alavancando tags de parte de fala para identificar e eliminar entidades não marcadas como falsos negativos e outras intuições sobre as pontuações de confiança do classificador no contexto local e global. Ellen alcança desempenho muito forte no conjunto de dados CONLL-2003 ao usar a supervisão mínima do léxico acima. Também supera a maioria dos métodos NER semi-supervisionados existentes (e consideravelmente mais complexos) nas mesmas configurações de supervisão comumente usadas na literatura (ou seja, 5% dos dados de treinamento). Além disso, avaliamos nosso modelo CONLL-2003 em um cenário de tiro zero no WNUT-17, onde descobrimos que ele supera o GPT-3.5 e alcança desempenho comparável ao GPT-4. Em uma configuração de tiro zero, Ellen também atinge mais de 75% do desempenho de um modelo forte e totalmente supervisionado treinado em dados de ouro.
O código pronto para a câmera será lançado em breve.
| Precisão | Lembrar | F1 |
|---|---|---|
| 74,63% | 79,26% | 76,87% |
Ellen † supera métodos mais complexos, como Pu-Learning e Variational Sequencial Labelers (VSL-GG-Hier) ao usar 5% dos dados como supervisão.
| Métodos | P | R | F1 |
|---|---|---|---|
| VSL-GG-Hier | 84,13% | 82,64% | 83,38% |
| MT + ruído | 83,74% | 81,49% | 82,60% |
| Semi-lada | 86,93% | 85,74% | 86,33% |
| JointProp | 89,88% | 85,98% | 87,68% |
| Pu-learning | 85,79% | 81,03% | 83,34% |
| Ellen † | 81,88% | 88,01% | 84,87% |
| Método | Loc | Misc | Org | POR | Avg |
|---|---|---|---|---|---|
| T-ner | 64,21% | 42,04% | 42,98% | 66,11% | 55,11% |
| GPT-3.5 | 49,17% | 8,06% | 29,71% | 59,84% | 39,96% |
| GPT-4 | 58,70% | 25,40% | 38,05% | 56,87% | 43,72% |
| Ellen+ | 44,82% | 6,21% | 26,49% | 67,00% | 41,56% |
Introduzimos uma linha de base muito forte para NER totalmente não supervisionado usando menos de 10 tiros (mais de 56% F1 no CONLL-03 Dev!)
| Tipo de entidade | Precisão | Lembrar | F1 |
|---|---|---|---|
| Geral | 61,78% | 51,90% | 56,41% |
| Loc | 69,72% | 41,53% | 52,05% |
| Misc | 45,18% | 55,15% | 49,67% |
| Org | 44,85% | 40,88% | 42,77% |
| POR | 85,07% | 65,02% | 73,71% |
Se você achar esse trabalho útil, considere citar:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
O código divulgado neste repositório será gratuito para usar na maioria das circunstâncias sob a licença do MIT.
Haris riaz ([email protected]) ou ([email protected])


